 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy-Gated Latent Recursion
Jun 15, 2026Inference-time scaling has become the dominant lever for improving language-model reasoning, but existing methods derive rollout diversity from a single source: stochastic token-level sampling. We argue that this single-axis sampling space is fundamentally limiting, and identify a second, fully deterministic and complementary axis: the layer span $L$ at which a frozen model's top decoder layers are recursively re-applied at high-uncertainty tokens. Different choices of $L$ produce distinct rollouts that solve different subsets of problems, with no stochasticity. We instantiate this axis through Entropy-Gated Latent Recursion (EGLR), a training-free decoding procedure that re-applies the top-$L$ layers for at most $K_{\max}$ iterations until the next-token distribution converges. Combined with $T$ temperature samples, EGLR turns a single-axis stochastic rollout pool into an $L\times T$ Cartesian sampling space at almost the same per-rollout cost. We characterize this space across $8$ instruction-tuned models and $6$ math reasoning benchmarks, and show that the $L$-axis is genuinely complementary to temperature: on MATH-500 with Qwen2.5-3B-Instruct, the joint $L\times T$ oracle reaches $91.6\%$, $+8.2$ percentage points beyond the temperature-only oracle ($83.4\%$) and $+10.4$ points beyond the layer-only oracle ($81.2\%$), confirming that the two axes capture genuinely complementary problems. The expanded rollout pool provides richer per-prompt candidates for any downstream procedure that consumes rollouts, including self-consistency, best-of-$N$ with verifiers, and group-relative RL training (GRPO), opening a new direction for inference-time scaling that does not rely on stochastic noise.
Target-Augmented Shared Fusion-based Multimodal Sarcasm Explanation Generation
Feb 11, 2025



Sarcasm is a linguistic phenomenon that intends to ridicule a target (e.g., entity, event, or person) in an inherent way. Multimodal Sarcasm Explanation (MuSE) aims at revealing the intended irony in a sarcastic post using a natural language explanation. Though important, existing systems overlooked the significance of the target of sarcasm in generating explanations. In this paper, we propose a Target-aUgmented shaRed fusion-Based sarcasm explanatiOn model, aka. TURBO. We design a novel shared-fusion mechanism to leverage the inter-modality relationships between an image and its caption. TURBO assumes the target of the sarcasm and guides the multimodal shared fusion mechanism in learning intricacies of the intended irony for explanations. We evaluate our proposed TURBO model on the MORE+ dataset. Comparison against multiple baselines and state-of-the-art models signifies the performance improvement of TURBO by an average margin of $+3.3\%$. Moreover, we explore LLMs in zero and one-shot settings for our task and observe that LLM-generated explanation, though remarkable, often fails to capture the critical nuances of the sarcasm. Furthermore, we supplement our study with extensive human evaluation on TURBO's generated explanations and find them out to be comparatively better than other systems.
M2H2: A Multimodal Multiparty Hindi Dataset For Humor Recognition in Conversations
Aug 03, 2021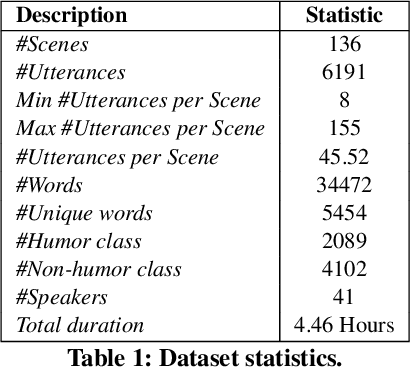


Humor recognition in conversations is a challenging task that has recently gained popularity due to its importance in dialogue understanding, including in multimodal settings (i.e., text, acoustics, and visual). The few existing datasets for humor are mostly in English. However, due to the tremendous growth in multilingual content, there is a great demand to build models and systems that support multilingual information access. To this end, we propose a dataset for Multimodal Multiparty Hindi Humor (M2H2) recognition in conversations containing 6,191 utterances from 13 episodes of a very popular TV series "Shrimaan Shrimati Phir Se". Each utterance is annotated with humor/non-humor labels and encompasses acoustic, visual, and textual modalities. We propose several strong multimodal baselines and show the importance of contextual and multimodal information for humor recognition in conversations. The empirical results on M2H2 dataset demonstrate that multimodal information complements unimodal information for humor recognition. The dataset and the baselines are available at http://www.iitp.ac.in/~ai-nlp-ml/resources.html and https://github.com/declare-lab/M2H2-dataset.
Multi-task Learning for Multi-modal Emotion Recognition and Sentiment Analysis
May 14, 2019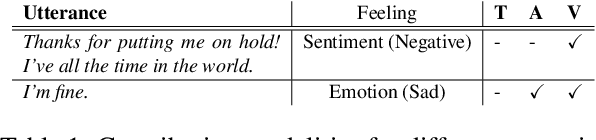
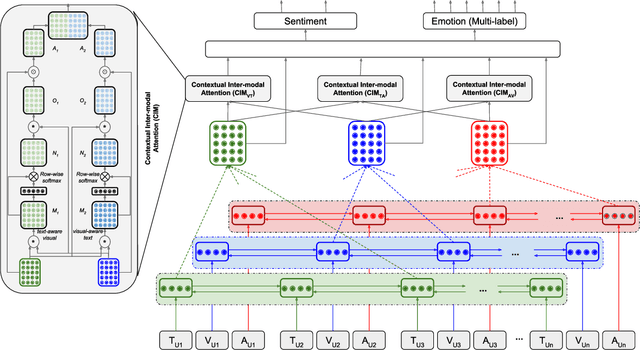
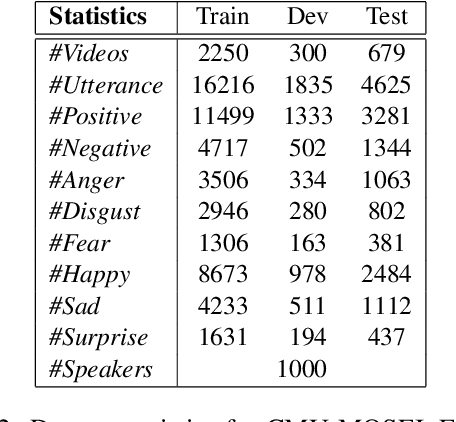
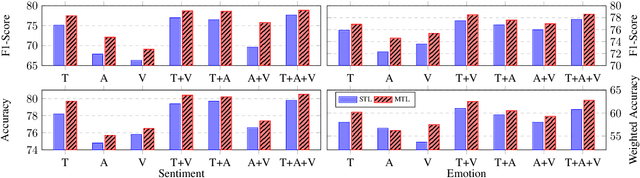
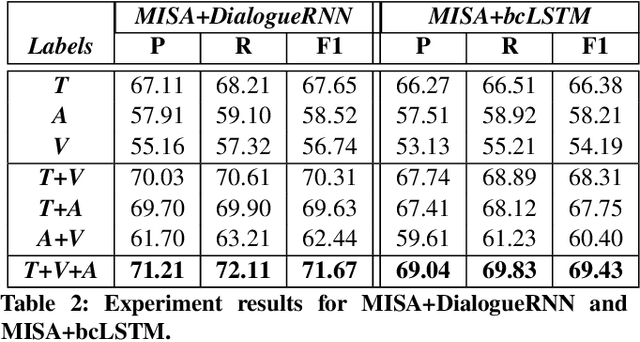
Related tasks often have inter-dependence on each other and perform better when solved in a joint framework. In this paper, we present a deep multi-task learning framework that jointly performs sentiment and emotion analysis both. The multi-modal inputs (i.e., text, acoustic and visual frames) of a video convey diverse and distinctive information, and usually do not have equal contribution in the decision making. We propose a context-level inter-modal attention framework for simultaneously predicting the sentiment and expressed emotions of an utterance. We evaluate our proposed approach on CMU-MOSEI dataset for multi-modal sentiment and emotion analysis. Evaluation results suggest that multi-task learning framework offers improvement over the single-task framework. The proposed approach reports new state-of-the-art performance for both sentiment analysis and emotion analysis.