 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemWeaver: Weaving Hybrid Memories for Traceable Long-Horizon Agentic Reasoning
Jan 26, 2026Large language model-based agents operating in long-horizon interactions require memory systems that support temporal consistency, multi-hop reasoning, and evidence-grounded reuse across sessions. Existing approaches largely rely on unstructured retrieval or coarse abstractions, which often lead to temporal conflicts, brittle reasoning, and limited traceability. We propose MemWeaver, a unified memory framework that consolidates long-term agent experiences into three interconnected components: a temporally grounded graph memory for structured relational reasoning, an experience memory that abstracts recurring interaction patterns from repeated observations, and a passage memory that preserves original textual evidence. MemWeaver employs a dual-channel retrieval strategy that jointly retrieves structured knowledge and supporting evidence to construct compact yet information-dense contexts for reasoning. Experiments on the LoCoMo benchmark demonstrate that MemWeaver substantially improves multi-hop and temporal reasoning accuracy while reducing input context length by over 95\% compared to long-context baselines.
SAGE: A Visual Language Model for Anomaly Detection via Fact Enhancement and Entropy-aware Alignment
Jul 10, 2025While Vision-Language Models (VLMs) have shown promising progress in general multimodal tasks, they often struggle in industrial anomaly detection and reasoning, particularly in delivering interpretable explanations and generalizing to unseen categories. This limitation stems from the inherently domain-specific nature of anomaly detection, which hinders the applicability of existing VLMs in industrial scenarios that require precise, structured, and context-aware analysis. To address these challenges, we propose SAGE, a VLM-based framework that enhances anomaly reasoning through Self-Guided Fact Enhancement (SFE) and Entropy-aware Direct Preference Optimization (E-DPO). SFE integrates domain-specific knowledge into visual reasoning via fact extraction and fusion, while E-DPO aligns model outputs with expert preferences using entropy-aware optimization. Additionally, we introduce AD-PL, a preference-optimized dataset tailored for industrial anomaly reasoning, consisting of 28,415 question-answering instances with expert-ranked responses. To evaluate anomaly reasoning models, we develop Multiscale Logical Evaluation (MLE), a quantitative framework analyzing model logic and consistency. SAGE demonstrates superior performance on industrial anomaly datasets under zero-shot and one-shot settings. The code, model and dataset are available at https://github.com/amoreZgx1n/SAGE.
DesignProbe: A Graphic Design Benchmark for Multimodal Large Language Models
Apr 23, 2024A well-executed graphic design typically achieves harmony in two levels, from the fine-grained design elements (color, font and layout) to the overall design. This complexity makes the comprehension of graphic design challenging, for it needs the capability to both recognize the design elements and understand the design. With the rapid development of Multimodal Large Language Models (MLLMs), we establish the DesignProbe, a benchmark to investigate the capability of MLLMs in design. Our benchmark includes eight tasks in total, across both the fine-grained element level and the overall design level. At design element level, we consider both the attribute recognition and semantic understanding tasks. At overall design level, we include style and metaphor. 9 MLLMs are tested and we apply GPT-4 as evaluator. Besides, further experiments indicates that refining prompts can enhance the performance of MLLMs. We first rewrite the prompts by different LLMs and found increased performances appear in those who self-refined by their own LLMs. We then add extra task knowledge in two different ways (text descriptions and image examples), finding that adding images boost much more performance over texts.
Spot the Error: Non-autoregressive Graphic Layout Generation with Wireframe Locator
Jan 29, 2024



Layout generation is a critical step in graphic design to achieve meaningful compositions of elements. Most previous works view it as a sequence generation problem by concatenating element attribute tokens (i.e., category, size, position). So far the autoregressive approach (AR) has achieved promising results, but is still limited in global context modeling and suffers from error propagation since it can only attend to the previously generated tokens. Recent non-autoregressive attempts (NAR) have shown competitive results, which provides a wider context range and the flexibility to refine with iterative decoding. However, current works only use simple heuristics to recognize erroneous tokens for refinement which is inaccurate. This paper first conducts an in-depth analysis to better understand the difference between the AR and NAR framework. Furthermore, based on our observation that pixel space is more sensitive in capturing spatial patterns of graphic layouts (e.g., overlap, alignment), we propose a learning-based locator to detect erroneous tokens which takes the wireframe image rendered from the generated layout sequence as input. We show that it serves as a complementary modality to the element sequence in object space and contributes greatly to the overall performance. Experiments on two public datasets show that our approach outperforms both AR and NAR baselines. Extensive studies further prove the effectiveness of different modules with interesting findings. Our code will be available at https://github.com/ffffatgoose/SpotError.
Towards Knowledge-Intensive Text-to-SQL Semantic Parsing with Formulaic Knowledge
Jan 03, 2023



In this paper, we study the problem of knowledge-intensive text-to-SQL, in which domain knowledge is necessary to parse expert questions into SQL queries over domain-specific tables. We formalize this scenario by building a new Chinese benchmark KnowSQL consisting of domain-specific questions covering various domains. We then address this problem by presenting formulaic knowledge, rather than by annotating additional data examples. More concretely, we construct a formulaic knowledge bank as a domain knowledge base and propose a framework (ReGrouP) to leverage this formulaic knowledge during parsing. Experiments using ReGrouP demonstrate a significant 28.2% improvement overall on KnowSQL.
MultiSpider: Towards Benchmarking Multilingual Text-to-SQL Semantic Parsing
Dec 27, 2022Text-to-SQL semantic parsing is an important NLP task, which greatly facilitates the interaction between users and the database and becomes the key component in many human-computer interaction systems. Much recent progress in text-to-SQL has been driven by large-scale datasets, but most of them are centered on English. In this work, we present MultiSpider, the largest multilingual text-to-SQL dataset which covers seven languages (English, German, French, Spanish, Japanese, Chinese, and Vietnamese). Upon MultiSpider, we further identify the lexical and structural challenges of text-to-SQL (caused by specific language properties and dialect sayings) and their intensity across different languages. Experimental results under three typical settings (zero-shot, monolingual and multilingual) reveal a 6.1% absolute drop in accuracy in non-English languages. Qualitative and quantitative analyses are conducted to understand the reason for the performance drop of each language. Besides the dataset, we also propose a simple schema augmentation framework SAVe (Schema-Augmentation-with-Verification), which significantly boosts the overall performance by about 1.8% and closes the 29.5% performance gap across languages.
UniSAr: A Unified Structure-Aware Autoregressive Language Model for Text-to-SQL
Apr 13, 2022
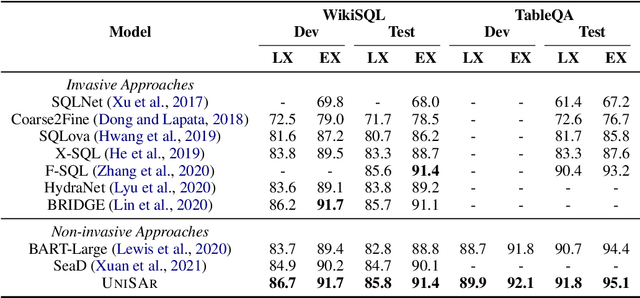
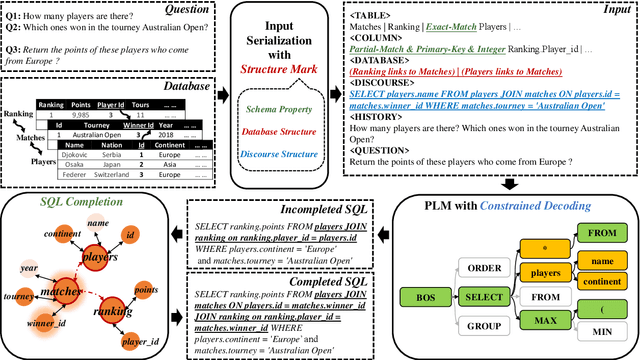
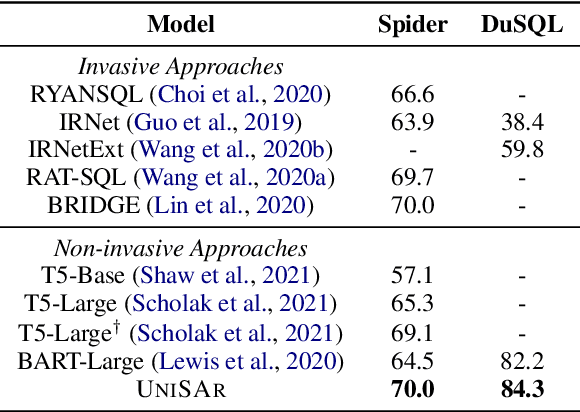
Existing text-to-SQL semantic parsers are typically designed for particular settings such as handling queries that span multiple tables, domains or turns which makes them ineffective when applied to different settings. We present UniSAr (Unified Structure-Aware Autoregressive Language Model), which benefits from directly using an off-the-shelf language model architecture and demonstrates consistently high performance under different settings. Specifically, UniSAr extends existing autoregressive language models to incorporate three non-invasive extensions to make them structure-aware: (1) adding structure mark to encode database schema, conversation context, and their relationships; (2) constrained decoding to decode well structured SQL for a given database schema; and (3) SQL completion to complete potential missing JOIN relationships in SQL based on database schema. On seven well-known text-to-SQL datasets covering multi-domain, multi-table and multi-turn, UniSAr demonstrates highly comparable or better performance to the most advanced specifically-designed text-to-SQL models. Importantly, our UniSAr is non-invasive, such that other core model advances in text-to-SQL can also adopt our extensions to further enhance performance.