 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomaly Detection In Surveillance Videos
Anomaly detection in surveillance videos is the process of identifying unusual or suspicious activities in video footage.
Papers and Code
Forward Consistency Learning with Gated Context Aggregation for Video Anomaly Detection
Jan 26, 2026As a crucial element of public security, video anomaly detection (VAD) aims to measure deviations from normal patterns for various events in real-time surveillance systems. However, most existing VAD methods rely on large-scale models to pursue extreme accuracy, limiting their feasibility on resource-limited edge devices. Moreover, mainstream prediction-based VAD detects anomalies using only single-frame future prediction errors, overlooking the richer constraints from longer-term temporal forward information. In this paper, we introduce FoGA, a lightweight VAD model that performs Forward consistency learning with Gated context Aggregation, containing about 2M parameters and tailored for potential edge devices. Specifically, we propose a Unet-based method that performs feature extraction on consecutive frames to generate both immediate and forward predictions. Then, we introduce a gated context aggregation module into the skip connections to dynamically fuse encoder and decoder features at the same spatial scale. Finally, the model is jointly optimized with a novel forward consistency loss, and a hybrid anomaly measurement strategy is adopted to integrate errors from both immediate and forward frames for more accurate detection. Extensive experiments demonstrate the effectiveness of the proposed method, which substantially outperforms state-of-the-art competing methods, running up to 155 FPS. Hence, our FoGA achieves an excellent trade-off between performance and the efficiency metric.
FTDMamba: Frequency-Assisted Temporal Dilation Mamba for Unmanned Aerial Vehicle Video Anomaly Detection
Jan 16, 2026Recent advances in video anomaly detection (VAD) mainly focus on ground-based surveillance or unmanned aerial vehicle (UAV) videos with static backgrounds, whereas research on UAV videos with dynamic backgrounds remains limited. Unlike static scenarios, dynamically captured UAV videos exhibit multi-source motion coupling, where the motion of objects and UAV-induced global motion are intricately intertwined. Consequently, existing methods may misclassify normal UAV movements as anomalies or fail to capture true anomalies concealed within dynamic backgrounds. Moreover, many approaches do not adequately address the joint modeling of inter-frame continuity and local spatial correlations across diverse temporal scales. To overcome these limitations, we propose the Frequency-Assisted Temporal Dilation Mamba (FTDMamba) network for UAV VAD, including two core components: (1) a Frequency Decoupled Spatiotemporal Correlation Module, which disentangles coupled motion patterns and models global spatiotemporal dependencies through frequency analysis; and (2) a Temporal Dilation Mamba Module, which leverages Mamba's sequence modeling capability to jointly learn fine-grained temporal dynamics and local spatial structures across multiple temporal receptive fields. Additionally, unlike existing UAV VAD datasets which focus on static backgrounds, we construct a large-scale Moving UAV VAD dataset (MUVAD), comprising 222,736 frames with 240 anomaly events across 12 anomaly types. Extensive experiments demonstrate that FTDMamba achieves state-of-the-art (SOTA) performance on two public static benchmarks and the new MUVAD dataset. The code and MUVAD dataset will be available at: https://github.com/uavano/FTDMamba.
Chain-of-Anomaly Thoughts with Large Vision-Language Models
Dec 23, 2025Automated video surveillance with Large Vision-Language Models is limited by their inherent bias towards normality, often failing to detect crimes. While Chain-of-Thought reasoning strategies show significant potential for improving performance in language tasks, the lack of inductive anomaly biases in their reasoning further steers the models towards normal interpretations. To address this, we propose Chain-of-Anomaly-Thoughts (CoAT), a multi-agent reasoning framework that introduces inductive criminal bias in the reasoning process through a final, anomaly-focused classification layer. Our method significantly improves Anomaly Detection, boosting F1-score by 11.8 p.p. on challenging low-resolution footage and Anomaly Classification by 3.78 p.p. in high-resolution videos.
Recognition of Abnormal Events in Surveillance Videos using Weakly Supervised Dual-Encoder Models
Nov 17, 2025

We address the challenge of detecting rare and diverse anomalies in surveillance videos using only video-level supervision. Our dual-backbone framework combines convolutional and transformer representations through top-k pooling, achieving 90.7% area under the curve (AUC) on the UCF-Crime dataset.
Towards Personalized Quantum Federated Learning for Anomaly Detection
Nov 08, 2025



Anomaly detection has a significant impact on applications such as video surveillance, medical diagnostics, and industrial monitoring, where anomalies frequently depend on context and anomaly-labeled data are limited. Quantum federated learning (QFL) overcomes these concerns by distributing model training among several quantum clients, consequently eliminating the requirement for centralized quantum storage and processing. However, in real-life quantum networks, clients frequently differ in terms of hardware capabilities, circuit designs, noise levels, and how classical data is encoded or preprocessed into quantum states. These differences create inherent heterogeneity across clients - not just in their data distributions, but also in their quantum processing behaviors. As a result, training a single global model becomes ineffective, especially when clients handle imbalanced or non-identically distributed (non-IID) data. To address this, we propose a new framework called personalized quantum federated learning (PQFL) for anomaly detection. PQFL enhances local model training at quantum clients using parameterized quantum circuits and classical optimizers, while introducing a quantum-centric personalization strategy that adapts each client's model to its own hardware characteristics and data representation. Extensive experiments show that PQFL significantly improves anomaly detection accuracy under diverse and realistic conditions. Compared to state-of-the-art methods, PQFL reduces false errors by up to 23%, and achieves gains of 24.2% in AUROC and 20.5% in AUPR, highlighting its effectiveness and scalability in practical quantum federated settings.
Robust Spatiotemporally Contiguous Anomaly Detection Using Tensor Decomposition
Oct 01, 2025Anomaly detection in spatiotemporal data is a challenging problem encountered in a variety of applications, including video surveillance, medical imaging data, and urban traffic monitoring. Existing anomaly detection methods focus mainly on point anomalies and cannot deal with temporal and spatial dependencies that arise in spatio-temporal data. Tensor-based anomaly detection methods have been proposed to address this problem. Although existing methods can capture dependencies across different modes, they are primarily supervised and do not account for the specific structure of anomalies. Moreover, these methods focus mainly on extracting anomalous features without providing any statistical confidence. In this paper, we introduce an unsupervised tensor-based anomaly detection method that simultaneously considers the sparse and spatiotemporally smooth nature of anomalies. The anomaly detection problem is formulated as a regularized robust low-rank + sparse tensor decomposition where the total variation of the tensor with respect to the underlying spatial and temporal graphs quantifies the spatiotemporal smoothness of the anomalies. Once the anomalous features are extracted, we introduce a statistical anomaly scoring framework that accounts for local spatio-temporal dependencies. The proposed framework is evaluated on both synthetic and real data.
HyCoVAD: A Hybrid SSL-LLM Model for Complex Video Anomaly Detection
Sep 26, 2025



Video anomaly detection (VAD) is crucial for intelligent surveillance, but a significant challenge lies in identifying complex anomalies, which are events defined by intricate relationships and temporal dependencies among multiple entities rather than by isolated actions. While self-supervised learning (SSL) methods effectively model low-level spatiotemporal patterns, they often struggle to grasp the semantic meaning of these interactions. Conversely, large language models (LLMs) offer powerful contextual reasoning but are computationally expensive for frame-by-frame analysis and lack fine-grained spatial localization. We introduce HyCoVAD, Hybrid Complex Video Anomaly Detection, a hybrid SSL-LLM model that combines a multi-task SSL temporal analyzer with LLM validator. The SSL module is built upon an nnFormer backbone which is a transformer-based model for image segmentation. It is trained with multiple proxy tasks, learns from video frames to identify those suspected of anomaly. The selected frames are then forwarded to the LLM, which enriches the analysis with semantic context by applying structured, rule-based reasoning to validate the presence of anomalies. Experiments on the challenging ComplexVAD dataset show that HyCoVAD achieves a 72.5% frame-level AUC, outperforming existing baselines by 12.5% while reducing LLM computation. We release our interaction anomaly taxonomy, adaptive thresholding protocol, and code to facilitate future research in complex VAD scenarios.
Unlocking Vision-Language Models for Video Anomaly Detection via Fine-Grained Prompting
Oct 02, 2025
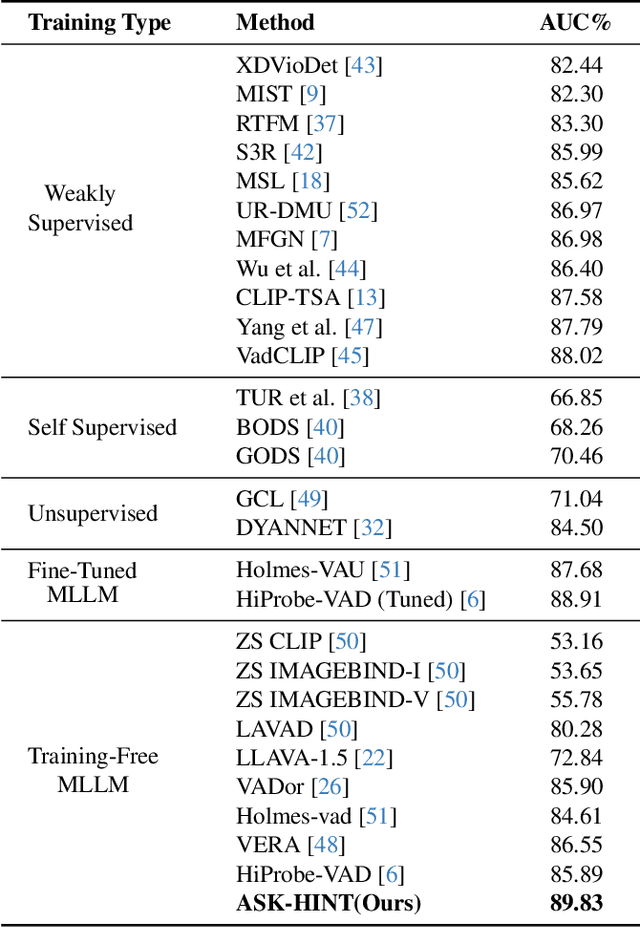
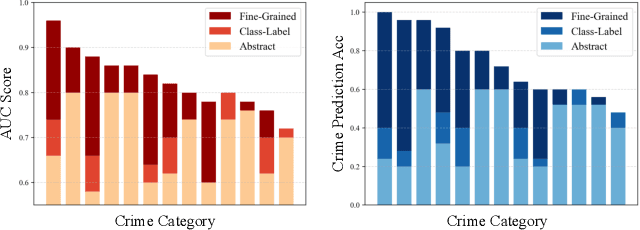
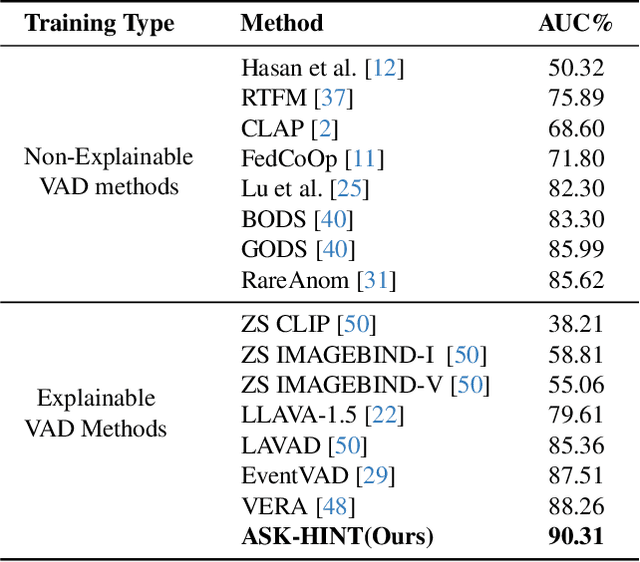
Prompting has emerged as a practical way to adapt frozen vision-language models (VLMs) for video anomaly detection (VAD). Yet, existing prompts are often overly abstract, overlooking the fine-grained human-object interactions or action semantics that define complex anomalies in surveillance videos. We propose ASK-Hint, a structured prompting framework that leverages action-centric knowledge to elicit more accurate and interpretable reasoning from frozen VLMs. Our approach organizes prompts into semantically coherent groups (e.g. violence, property crimes, public safety) and formulates fine-grained guiding questions that align model predictions with discriminative visual cues. Extensive experiments on UCF-Crime and XD-Violence show that ASK-Hint consistently improves AUC over prior baselines, achieving state-of-the-art performance compared to both fine-tuned and training-free methods. Beyond accuracy, our framework provides interpretable reasoning traces towards anomaly and demonstrates strong generalization across datasets and VLM backbones. These results highlight the critical role of prompt granularity and establish ASK-Hint as a new training-free and generalizable solution for explainable video anomaly detection.
MoniTor: Exploiting Large Language Models with Instruction for Online Video Anomaly Detection
Oct 24, 2025Video Anomaly Detection (VAD) aims to locate unusual activities or behaviors within videos. Recently, offline VAD has garnered substantial research attention, which has been invigorated by the progress in large language models (LLMs) and vision-language models (VLMs), offering the potential for a more nuanced understanding of anomalies. However, online VAD has seldom received attention due to real-time constraints and computational intensity. In this paper, we introduce a novel Memory-based online scoring queue scheme for Training-free VAD (MoniTor), to address the inherent complexities in online VAD. Specifically, MoniTor applies a streaming input to VLMs, leveraging the capabilities of pre-trained large-scale models. To capture temporal dependencies more effectively, we incorporate a novel prediction mechanism inspired by Long Short-Term Memory (LSTM) networks. This ensures the model can effectively model past states and leverage previous predictions to identify anomalous behaviors. Thereby, it better understands the current frame. Moreover, we design a scoring queue and an anomaly prior to dynamically store recent scores and cover all anomalies in the monitoring scenario, providing guidance for LLMs to distinguish between normal and abnormal behaviors over time. We evaluate MoniTor on two large datasets (i.e., UCF-Crime and XD-Violence) containing various surveillance and real-world scenarios. The results demonstrate that MoniTor outperforms state-of-the-art methods and is competitive with weakly supervised methods without training. Code is available at https://github.com/YsTvT/MoniTor.
GTA-Crime: A Synthetic Dataset and Generation Framework for Fatal Violence Detection with Adversarial Snippet-Level Domain Adaptation
Sep 10, 2025Recent advancements in video anomaly detection (VAD) have enabled identification of various criminal activities in surveillance videos, but detecting fatal incidents such as shootings and stabbings remains difficult due to their rarity and ethical issues in data collection. Recognizing this limitation, we introduce GTA-Crime, a fatal video anomaly dataset and generation framework using Grand Theft Auto 5 (GTA5). Our dataset contains fatal situations such as shootings and stabbings, captured from CCTV multiview perspectives under diverse conditions including action types, weather, time of day, and viewpoints. To address the rarity of such scenarios, we also release a framework for generating these types of videos. Additionally, we propose a snippet-level domain adaptation strategy using Wasserstein adversarial training to bridge the gap between synthetic GTA-Crime features and real-world features like UCF-Crime. Experimental results validate our GTA-Crime dataset and demonstrate that incorporating GTA-Crime with our domain adaptation strategy consistently enhances real world fatal violence detection accuracy. Our dataset and the data generation framework are publicly available at https://github.com/ta-ho/GTA-Crime.