 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashback: Memory-Driven Zero-shot, Real-time Video Anomaly Detection
May 21, 2025Video Anomaly Detection (VAD) automatically identifies anomalous events from video, mitigating the need for human operators in large-scale surveillance deployments. However, three fundamental obstacles hinder real-world adoption: domain dependency and real-time constraints -- requiring near-instantaneous processing of incoming video. To this end, we propose Flashback, a zero-shot and real-time video anomaly detection paradigm. Inspired by the human cognitive mechanism of instantly judging anomalies and reasoning in current scenes based on past experience, Flashback operates in two stages: Recall and Respond. In the offline recall stage, an off-the-shelf LLM builds a pseudo-scene memory of both normal and anomalous captions without any reliance on real anomaly data. In the online respond stage, incoming video segments are embedded and matched against this memory via similarity search. By eliminating all LLM calls at inference time, Flashback delivers real-time VAD even on a consumer-grade GPU. On two large datasets from real-world surveillance scenarios, UCF-Crime and XD-Violence, we achieve 87.3 AUC (+7.0 pp) and 75.1 AP (+13.1 pp), respectively, outperforming prior zero-shot VAD methods by large margins.
Infusing Environmental Captions for Long-Form Video Language Grounding
Aug 06, 2024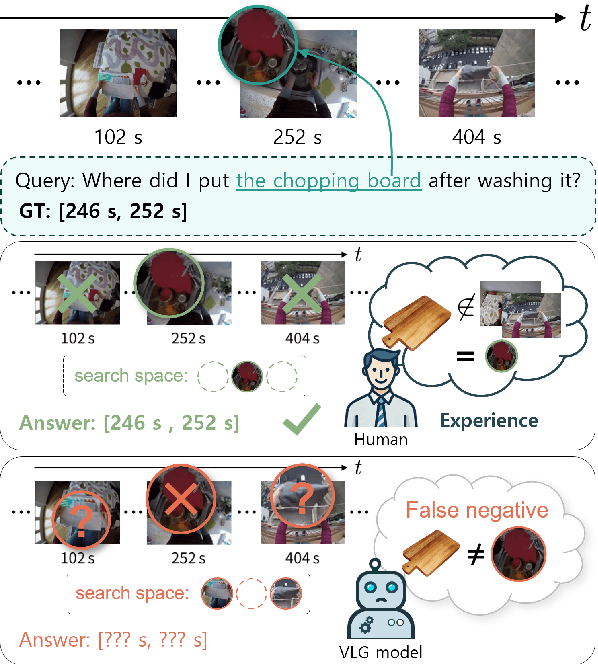
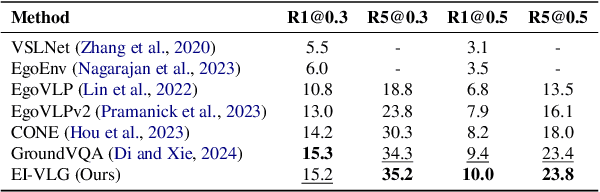
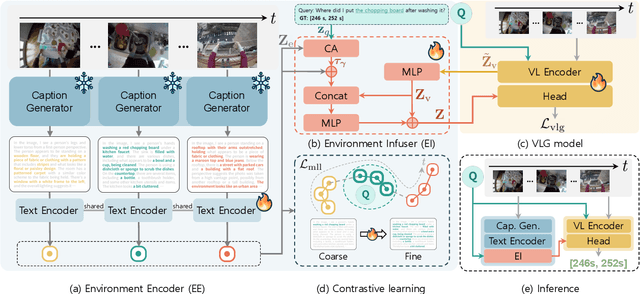
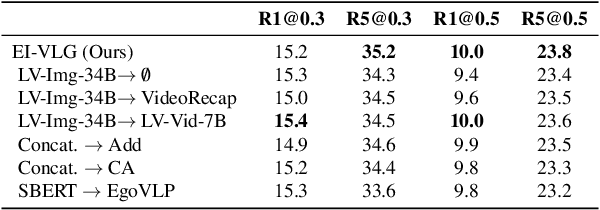
In this work, we tackle the problem of long-form video-language grounding (VLG). Given a long-form video and a natural language query, a model should temporally localize the precise moment that answers the query. Humans can easily solve VLG tasks, even with arbitrarily long videos, by discarding irrelevant moments using extensive and robust knowledge gained from experience. Unlike humans, existing VLG methods are prone to fall into superficial cues learned from small-scale datasets, even when they are within irrelevant frames. To overcome this challenge, we propose EI-VLG, a VLG method that leverages richer textual information provided by a Multi-modal Large Language Model (MLLM) as a proxy for human experiences, helping to effectively exclude irrelevant frames. We validate the effectiveness of the proposed method via extensive experiments on a challenging EgoNLQ benchmark.
GLAD: Global-Local View Alignment and Background Debiasing for Unsupervised Video Domain Adaptation with Large Domain Gap
Nov 22, 2023



In this work, we tackle the challenging problem of unsupervised video domain adaptation (UVDA) for action recognition. We specifically focus on scenarios with a substantial domain gap, in contrast to existing works primarily deal with small domain gaps between labeled source domains and unlabeled target domains. To establish a more realistic setting, we introduce a novel UVDA scenario, denoted as Kinetics->BABEL, with a more considerable domain gap in terms of both temporal dynamics and background shifts. To tackle the temporal shift, i.e., action duration difference between the source and target domains, we propose a global-local view alignment approach. To mitigate the background shift, we propose to learn temporal order sensitive representations by temporal order learning and background invariant representations by background augmentation. We empirically validate that the proposed method shows significant improvement over the existing methods on the Kinetics->BABEL dataset with a large domain gap. The code is available at https://github.com/KHUVLL/GLAD.