 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe AI Genie Phenomenon and Three Types of AI Chatbot Addiction: Escapist Roleplays, Pseudosocial Companions, and Epistemic Rabbit Holes
Jan 19, 2026Recent reports on generative AI chatbot use raise concerns about its addictive potential. An in-depth understanding is imperative to minimize risks, yet AI chatbot addiction remains poorly understood. This study examines how to characterize AI chatbot addiction--why users become addicted, the symptoms commonly reported, and the distinct types it comprises. We conducted a thematic analysis of Reddit entries (n=334) across 14 subreddits where users narrated their experiences with addictive AI chatbot use, followed by an exploratory data analysis. We found: (1) users' dependence tied to the "AI Genie" phenomenon--users can get exactly anything they want with minimal effort--and marked by symptoms that align with addiction literature, (2) three distinct addiction types: Escapist Roleplay, Pseudosocial Companion, and Epistemic Rabbit Hole, (3) sexual content involved in multiple cases, and (4) recovery strategies' perceived helpfulness differ between addiction types. Our work lays empirical groundwork to inform future strategies for prevention, diagnosis, and intervention.
PASTA: A Scalable Framework for Multi-Policy AI Compliance Evaluation
Jan 16, 2026AI compliance is becoming increasingly critical as AI systems grow more powerful and pervasive. Yet the rapid expansion of AI policies creates substantial burdens for resource-constrained practitioners lacking policy expertise. Existing approaches typically address one policy at a time, making multi-policy compliance costly. We present PASTA, a scalable compliance tool integrating four innovations: (1) a comprehensive model-card format supporting descriptive inputs across development stages; (2) a policy normalization scheme; (3) an efficient LLM-powered pairwise evaluation engine with cost-saving strategies; and (4) an interface delivering interpretable evaluations via compliance heatmaps and actionable recommendations. Expert evaluation shows PASTA's judgments closely align with human experts ($ρ\geq .626$). The system evaluates five major policies in under two minutes at approximately \$3. A user study (N = 12) confirms practitioners found outputs easy-to-understand and actionable, introducing a novel framework for scalable automated AI governance.
PLOT: Pseudo-Labeling via Video Object Tracking for Scalable Monocular 3D Object Detection
Jul 03, 2025Monocular 3D object detection (M3OD) has long faced challenges due to data scarcity caused by high annotation costs and inherent 2D-to-3D ambiguity. Although various weakly supervised methods and pseudo-labeling methods have been proposed to address these issues, they are mostly limited by domain-specific learning or rely solely on shape information from a single observation. In this paper, we propose a novel pseudo-labeling framework that uses only video data and is more robust to occlusion, without requiring a multi-view setup, additional sensors, camera poses, or domain-specific training. Specifically, we explore a technique for aggregating the pseudo-LiDARs of both static and dynamic objects across temporally adjacent frames using object point tracking, enabling 3D attribute extraction in scenarios where 3D data acquisition is infeasible. Extensive experiments demonstrate that our method ensures reliable accuracy and strong scalability, making it a practical and effective solution for M3OD.
Flashback: Memory-Driven Zero-shot, Real-time Video Anomaly Detection
May 21, 2025Video Anomaly Detection (VAD) automatically identifies anomalous events from video, mitigating the need for human operators in large-scale surveillance deployments. However, three fundamental obstacles hinder real-world adoption: domain dependency and real-time constraints -- requiring near-instantaneous processing of incoming video. To this end, we propose Flashback, a zero-shot and real-time video anomaly detection paradigm. Inspired by the human cognitive mechanism of instantly judging anomalies and reasoning in current scenes based on past experience, Flashback operates in two stages: Recall and Respond. In the offline recall stage, an off-the-shelf LLM builds a pseudo-scene memory of both normal and anomalous captions without any reliance on real anomaly data. In the online respond stage, incoming video segments are embedded and matched against this memory via similarity search. By eliminating all LLM calls at inference time, Flashback delivers real-time VAD even on a consumer-grade GPU. On two large datasets from real-world surveillance scenarios, UCF-Crime and XD-Violence, we achieve 87.3 AUC (+7.0 pp) and 75.1 AP (+13.1 pp), respectively, outperforming prior zero-shot VAD methods by large margins.
V-NAW: Video-based Noise-aware Adaptive Weighting for Facial Expression Recognition
Mar 20, 2025


Facial Expression Recognition (FER) plays a crucial role in human affective analysis and has been widely applied in computer vision tasks such as human-computer interaction and psychological assessment. The 8th Affective Behavior Analysis in-the-Wild (ABAW) Challenge aims to assess human emotions using the video-based Aff-Wild2 dataset. This challenge includes various tasks, including the video-based EXPR recognition track, which is our primary focus. In this paper, we demonstrate that addressing label ambiguity and class imbalance, which are known to cause performance degradation, can lead to meaningful performance improvements. Specifically, we propose Video-based Noise-aware Adaptive Weighting (V-NAW), which adaptively assigns importance to each frame in a clip to address label ambiguity and effectively capture temporal variations in facial expressions. Furthermore, we introduce a simple and effective augmentation strategy to reduce redundancy between consecutive frames, which is a primary cause of overfitting. Through extensive experiments, we validate the effectiveness of our approach, demonstrating significant improvements in video-based FER performance.
Channel-wise Noise Scheduled Diffusion for Inverse Rendering in Indoor Scenes
Mar 13, 2025We propose a diffusion-based inverse rendering framework that decomposes a single RGB image into geometry, material, and lighting. Inverse rendering is inherently ill-posed, making it difficult to predict a single accurate solution. To address this challenge, recent generative model-based methods aim to present a range of possible solutions. However, finding a single accurate solution and generating diverse solutions can be conflicting. In this paper, we propose a channel-wise noise scheduling approach that allows a single diffusion model architecture to achieve two conflicting objectives. The resulting two diffusion models, trained with different channel-wise noise schedules, can predict a single highly accurate solution and present multiple possible solutions. The experimental results demonstrate the superiority of our two models in terms of both diversity and accuracy, which translates to enhanced performance in downstream applications such as object insertion and material editing.
Effective SAM Combination for Open-Vocabulary Semantic Segmentation
Nov 22, 2024



Open-vocabulary semantic segmentation aims to assign pixel-level labels to images across an unlimited range of classes. Traditional methods address this by sequentially connecting a powerful mask proposal generator, such as the Segment Anything Model (SAM), with a pre-trained vision-language model like CLIP. But these two-stage approaches often suffer from high computational costs, memory inefficiencies. In this paper, we propose ESC-Net, a novel one-stage open-vocabulary segmentation model that leverages the SAM decoder blocks for class-agnostic segmentation within an efficient inference framework. By embedding pseudo prompts generated from image-text correlations into SAM's promptable segmentation framework, ESC-Net achieves refined spatial aggregation for accurate mask predictions. ESC-Net achieves superior performance on standard benchmarks, including ADE20K, PASCAL-VOC, and PASCAL-Context, outperforming prior methods in both efficiency and accuracy. Comprehensive ablation studies further demonstrate its robustness across challenging conditions.
MAIR++: Improving Multi-view Attention Inverse Rendering with Implicit Lighting Representation
Aug 13, 2024



In this paper, we propose a scene-level inverse rendering framework that uses multi-view images to decompose the scene into geometry, SVBRDF, and 3D spatially-varying lighting. While multi-view images have been widely used for object-level inverse rendering, scene-level inverse rendering has primarily been studied using single-view images due to the lack of a dataset containing high dynamic range multi-view images with ground-truth geometry, material, and spatially-varying lighting. To improve the quality of scene-level inverse rendering, a novel framework called Multi-view Attention Inverse Rendering (MAIR) was recently introduced. MAIR performs scene-level multi-view inverse rendering by expanding the OpenRooms dataset, designing efficient pipelines to handle multi-view images, and splitting spatially-varying lighting. Although MAIR showed impressive results, its lighting representation is fixed to spherical Gaussians, which limits its ability to render images realistically. Consequently, MAIR cannot be directly used in applications such as material editing. Moreover, its multi-view aggregation networks have difficulties extracting rich features because they only focus on the mean and variance between multi-view features. In this paper, we propose its extended version, called MAIR++. MAIR++ addresses the aforementioned limitations by introducing an implicit lighting representation that accurately captures the lighting conditions of an image while facilitating realistic rendering. Furthermore, we design a directional attention-based multi-view aggregation network to infer more intricate relationships between views. Experimental results show that MAIR++ not only achieves better performance than MAIR and single-view-based methods, but also displays robust performance on unseen real-world scenes.
VIGFace: Virtual Identity Generation Model for Face Image Synthesis
Mar 13, 2024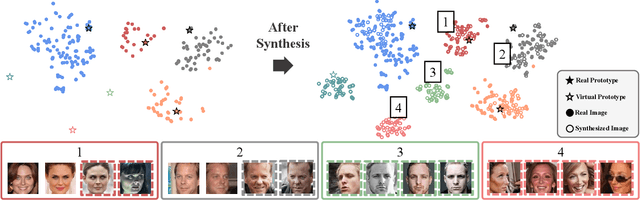
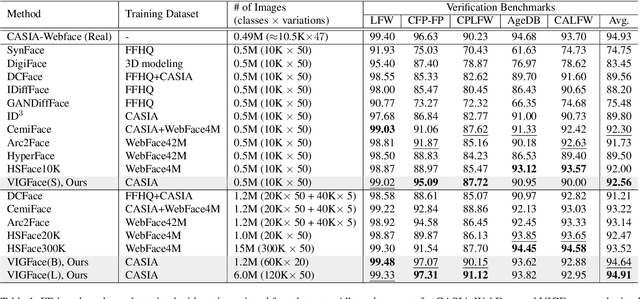
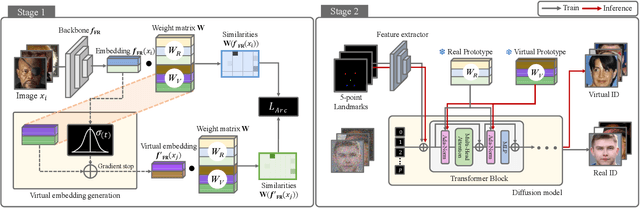
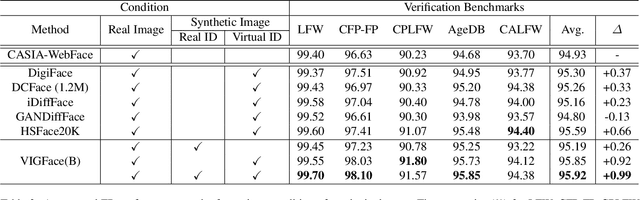
Deep learning-based face recognition continues to face challenges due to its reliance on huge datasets obtained from web crawling, which can be costly to gather and raise significant real-world privacy concerns. To address this issue, we propose VIGFace, a novel framework capable of generating synthetic facial images. Initially, we train the face recognition model using a real face dataset and create a feature space for both real and virtual IDs where virtual prototypes are orthogonal to other prototypes. Subsequently, we generate synthetic images by using the diffusion model based on the feature space. Our proposed framework provides two significant benefits. Firstly, it allows for creating virtual facial images without concerns about portrait rights, guaranteeing that the generated virtual face images are clearly differentiated from existing individuals. Secondly, it serves as an effective augmentation method by incorporating real existing images. Further experiments demonstrate the efficacy of our framework, achieving state-of-the-art results from both perspectives without any external data.
IG-FIQA: Improving Face Image Quality Assessment through Intra-class Variance Guidance robust to Inaccurate Pseudo-Labels
Mar 13, 2024In the realm of face image quality assesment (FIQA), method based on sample relative classification have shown impressive performance. However, the quality scores used as pseudo-labels assigned from images of classes with low intra-class variance could be unrelated to the actual quality in this method. To address this issue, we present IG-FIQA, a novel approach to guide FIQA training, introducing a weight parameter to alleviate the adverse impact of these classes. This method involves estimating sample intra-class variance at each iteration during training, ensuring minimal computational overhead and straightforward implementation. Furthermore, this paper proposes an on-the-fly data augmentation methodology for improved generalization performance in FIQA. On various benchmark datasets, our proposed method, IG-FIQA, achieved novel state-of-the-art (SOTA) performance.