 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDaily-Omni: Towards Audio-Visual Reasoning with Temporal Alignment across Modalities
May 23, 2025Recent Multimodal Large Language Models (MLLMs) achieve promising performance on visual and audio benchmarks independently. However, the ability of these models to process cross-modal information synchronously remains largely unexplored. In this paper, we introduce: 1) Daily-Omni, an Audio-Visual Questioning and Answering benchmark comprising 684 videos of daily life scenarios from diverse sources, rich in both audio and visual information, and featuring 1197 multiple-choice QA pairs across 6 major tasks; 2) Daily-Omni QA Generation Pipeline, which includes automatic annotation, QA generation and QA optimization, significantly improves efficiency for human evaluation and scalability of the benchmark; 3) Daily-Omni-Agent, a training-free agent utilizing open-source Visual Language Model (VLM), Audio Language Model (ALM) and Automatic Speech Recognition (ASR) model to establish a baseline for this benchmark. The results show that current MLLMs still struggle significantly with tasks requiring audio-visual integration, but combining VLMs and ALMs with simple temporal alignment techniques can achieve substantially better performance. Codes and benchmark are available at \href{https://github.com/Lliar-liar/Daily-Omni}{https://github.com/Lliar-liar/Daily-Omni}.
ViaRL: Adaptive Temporal Grounding via Visual Iterated Amplification Reinforcement Learning
May 21, 2025



Video understanding is inherently intention-driven-humans naturally focus on relevant frames based on their goals. Recent advancements in multimodal large language models (MLLMs) have enabled flexible query-driven reasoning; however, video-based frameworks like Video Chain-of-Thought lack direct training signals to effectively identify relevant frames. Current approaches often rely on heuristic methods or pseudo-label supervised annotations, which are both costly and limited in scalability across diverse scenarios. To overcome these challenges, we introduce ViaRL, the first framework to leverage rule-based reinforcement learning (RL) for optimizing frame selection in intention-driven video understanding. An iterated amplification strategy is adopted to perform alternating cyclic training in the video CoT system, where each component undergoes iterative cycles of refinement to improve its capabilities. ViaRL utilizes the answer accuracy of a downstream model as a reward signal to train a frame selector through trial-and-error, eliminating the need for expensive annotations while closely aligning with human-like learning processes. Comprehensive experiments across multiple benchmarks, including VideoMME, LVBench, and MLVU, demonstrate that ViaRL consistently delivers superior temporal grounding performance and robust generalization across diverse video understanding tasks, highlighting its effectiveness and scalability. Notably, ViaRL achieves a nearly 15\% improvement on Needle QA, a subset of MLVU, which is required to search a specific needle within a long video and regarded as one of the most suitable benchmarks for evaluating temporal grounding.
UniGen: Enhanced Training & Test-Time Strategies for Unified Multimodal Understanding and Generation
May 20, 2025We introduce UniGen, a unified multimodal large language model (MLLM) capable of image understanding and generation. We study the full training pipeline of UniGen from a data-centric perspective, including multi-stage pre-training, supervised fine-tuning, and direct preference optimization. More importantly, we propose a new Chain-of-Thought Verification (CoT-V) strategy for test-time scaling, which significantly boosts UniGen's image generation quality using a simple Best-of-N test-time strategy. Specifically, CoT-V enables UniGen to act as both image generator and verifier at test time, assessing the semantic alignment between a text prompt and its generated image in a step-by-step CoT manner. Trained entirely on open-source datasets across all stages, UniGen achieves state-of-the-art performance on a range of image understanding and generation benchmarks, with a final score of 0.78 on GenEval and 85.19 on DPG-Bench. Through extensive ablation studies, our work provides actionable insights and addresses key challenges in the full life cycle of building unified MLLMs, contributing meaningful directions to the future research.
Toward Generalizable Evaluation in the LLM Era: A Survey Beyond Benchmarks
Apr 26, 2025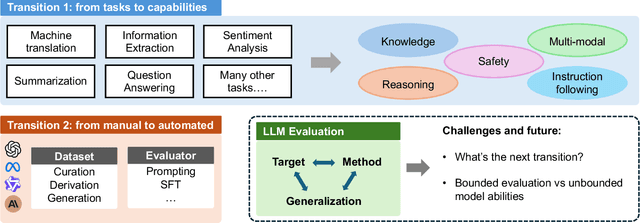
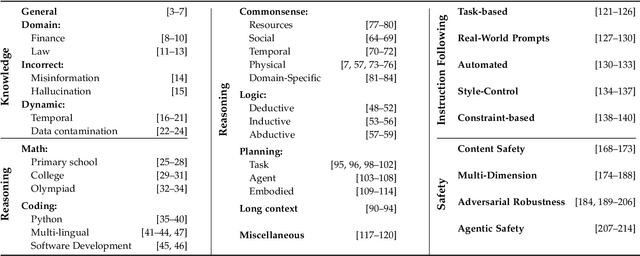
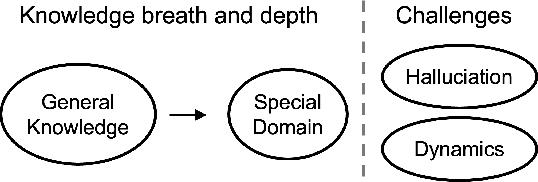
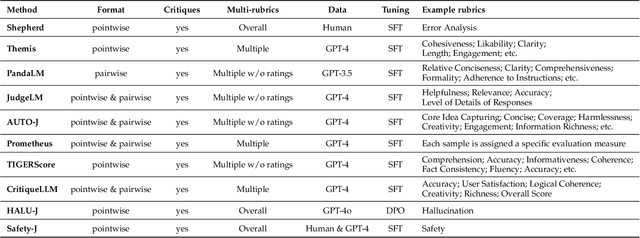
Large Language Models (LLMs) are advancing at an amazing speed and have become indispensable across academia, industry, and daily applications. To keep pace with the status quo, this survey probes the core challenges that the rise of LLMs poses for evaluation. We identify and analyze two pivotal transitions: (i) from task-specific to capability-based evaluation, which reorganizes benchmarks around core competencies such as knowledge, reasoning, instruction following, multi-modal understanding, and safety; and (ii) from manual to automated evaluation, encompassing dynamic dataset curation and "LLM-as-a-judge" scoring. Yet, even with these transitions, a crucial obstacle persists: the evaluation generalization issue. Bounded test sets cannot scale alongside models whose abilities grow seemingly without limit. We will dissect this issue, along with the core challenges of the above two transitions, from the perspectives of methods, datasets, evaluators, and metrics. Due to the fast evolving of this field, we will maintain a living GitHub repository (links are in each section) to crowd-source updates and corrections, and warmly invite contributors and collaborators.
SimpleAR: Pushing the Frontier of Autoregressive Visual Generation through Pretraining, SFT, and RL
Apr 15, 2025



This work presents SimpleAR, a vanilla autoregressive visual generation framework without complex architecure modifications. Through careful exploration of training and inference optimization, we demonstrate that: 1) with only 0.5B parameters, our model can generate 1024x1024 resolution images with high fidelity, and achieve competitive results on challenging text-to-image benchmarks, e.g., 0.59 on GenEval and 79.66 on DPG; 2) both supervised fine-tuning (SFT) and Group Relative Policy Optimization (GRPO) training could lead to significant improvements on generation aesthectics and prompt alignment; and 3) when optimized with inference acceleraton techniques like vLLM, the time for SimpleAR to generate an 1024x1024 image could be reduced to around 14 seconds. By sharing these findings and open-sourcing the code, we hope to reveal the potential of autoregressive visual generation and encourage more participation in this research field. Code is available at https://github.com/wdrink/SimpleAR.
Aligning Anime Video Generation with Human Feedback
Apr 14, 2025



Anime video generation faces significant challenges due to the scarcity of anime data and unusual motion patterns, leading to issues such as motion distortion and flickering artifacts, which result in misalignment with human preferences. Existing reward models, designed primarily for real-world videos, fail to capture the unique appearance and consistency requirements of anime. In this work, we propose a pipeline to enhance anime video generation by leveraging human feedback for better alignment. Specifically, we construct the first multi-dimensional reward dataset for anime videos, comprising 30k human-annotated samples that incorporating human preferences for both visual appearance and visual consistency. Based on this, we develop AnimeReward, a powerful reward model that employs specialized vision-language models for different evaluation dimensions to guide preference alignment. Furthermore, we introduce Gap-Aware Preference Optimization (GAPO), a novel training method that explicitly incorporates preference gaps into the optimization process, enhancing alignment performance and efficiency. Extensive experiment results show that AnimeReward outperforms existing reward models, and the inclusion of GAPO leads to superior alignment in both quantitative benchmarks and human evaluations, demonstrating the effectiveness of our pipeline in enhancing anime video quality. Our dataset and code will be publicly available.
DynamiCtrl: Rethinking the Basic Structure and the Role of Text for High-quality Human Image Animation
Mar 27, 2025



Human image animation has recently gained significant attention due to advancements in generative models. However, existing methods still face two major challenges: (1) architectural limitations, most models rely on U-Net, which underperforms compared to the MM-DiT; and (2) the neglect of textual information, which can enhance controllability. In this work, we introduce DynamiCtrl, a novel framework that not only explores different pose-guided control structures in MM-DiT, but also reemphasizes the crucial role of text in this task. Specifically, we employ a Shared VAE encoder for both reference images and driving pose videos, eliminating the need for an additional pose encoder and simplifying the overall framework. To incorporate pose features into the full attention blocks, we propose Pose-adaptive Layer Norm (PadaLN), which utilizes adaptive layer normalization to encode sparse pose features. The encoded features are directly added to the visual input, preserving the spatiotemporal consistency of the backbone while effectively introducing pose control into MM-DiT. Furthermore, within the full attention mechanism, we align textual and visual features to enhance controllability. By leveraging text, we not only enable fine-grained control over the generated content, but also, for the first time, achieve simultaneous control over both background and motion. Experimental results verify the superiority of DynamiCtrl on benchmark datasets, demonstrating its strong identity preservation, heterogeneous character driving, background controllability, and high-quality synthesis. The project page is available at https://gulucaptain.github.io/DynamiCtrl/.
CoMP: Continual Multimodal Pre-training for Vision Foundation Models
Mar 24, 2025Pre-trained Vision Foundation Models (VFMs) provide strong visual representations for a wide range of applications. In this paper, we continually pre-train prevailing VFMs in a multimodal manner such that they can effortlessly process visual inputs of varying sizes and produce visual representations that are more aligned with language representations, regardless of their original pre-training process. To this end, we introduce CoMP, a carefully designed multimodal pre-training pipeline. CoMP uses a Continual Rotary Position Embedding to support native resolution continual pre-training, and an Alignment Loss between visual and textual features through language prototypes to align multimodal representations. By three-stage training, our VFMs achieve remarkable improvements not only in multimodal understanding but also in other downstream tasks such as classification and segmentation. Remarkably, CoMP-SigLIP achieves scores of 66.7 on ChartQA and 75.9 on DocVQA with a 0.5B LLM, while maintaining an 87.4% accuracy on ImageNet-1K and a 49.5 mIoU on ADE20K under frozen chunk evaluation.
EDEN: Enhanced Diffusion for High-quality Large-motion Video Frame Interpolation
Mar 20, 2025



Handling complex or nonlinear motion patterns has long posed challenges for video frame interpolation. Although recent advances in diffusion-based methods offer improvements over traditional optical flow-based approaches, they still struggle to generate sharp, temporally consistent frames in scenarios with large motion. To address this limitation, we introduce EDEN, an Enhanced Diffusion for high-quality large-motion vidEo frame iNterpolation. Our approach first utilizes a transformer-based tokenizer to produce refined latent representations of the intermediate frames for diffusion models. We then enhance the diffusion transformer with temporal attention across the process and incorporate a start-end frame difference embedding to guide the generation of dynamic motion. Extensive experiments demonstrate that EDEN achieves state-of-the-art results across popular benchmarks, including nearly a 10% LPIPS reduction on DAVIS and SNU-FILM, and an 8% improvement on DAIN-HD.
BlockDance: Reuse Structurally Similar Spatio-Temporal Features to Accelerate Diffusion Transformers
Mar 20, 2025Diffusion models have demonstrated impressive generation capabilities, particularly with recent advancements leveraging transformer architectures to improve both visual and artistic quality. However, Diffusion Transformers (DiTs) continue to encounter challenges related to low inference speed, primarily due to the iterative denoising process. To address this issue, we propose BlockDance, a training-free approach that explores feature similarities at adjacent time steps to accelerate DiTs. Unlike previous feature-reuse methods that lack tailored reuse strategies for features at different scales, BlockDance prioritizes the identification of the most structurally similar features, referred to as Structurally Similar Spatio-Temporal (STSS) features. These features are primarily located within the structure-focused blocks of the transformer during the later stages of denoising. BlockDance caches and reuses these highly similar features to mitigate redundant computation, thereby accelerating DiTs while maximizing consistency with the generated results of the original model. Furthermore, considering the diversity of generated content and the varying distributions of redundant features, we introduce BlockDance-Ada, a lightweight decision-making network tailored for instance-specific acceleration. BlockDance-Ada dynamically allocates resources and provides superior content quality. Both BlockDance and BlockDance-Ada have proven effective across various generation tasks and models, achieving accelerations between 25% and 50% while maintaining generation quality.