 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFakeVLM-R1: Internalizing Physical Laws via CoT for Synthetic Image Detection
May 28, 2026The development of generative artificial intelligence technologies has propelled the visual realism of synthetic images to an unprecedented level. Although current interpretable detection methods based on Large Multimodal Models (LMMs) have made certain progress, they still rely on imitation learning derived from massive volumes of forged data. Consequently, they lack genuine causal reasoning capabilities and are prone to explanatory hallucinations. To overcome this bottleneck, we propose FakeVLM-R1, aiming to endow the model with human-like critical thinking capabilities when performing synthetic detection tasks. Building upon Supervised Fine-Tuning (SFT), this framework integrates Group Relative Policy Optimization (GRPO) with a Critical Thinking Chain-of-Thought (CoT) mechanism. During the inference phase, the model executes a "bidirectional dialectical reasoning" process: while proposing a forgery hypothesis, it must simultaneously invoke physical commonsense to construct an authenticity counter-proof. Furthermore, we constructed the FakeClue++ dataset with high-quality samples, which extensively introduces annotations guided by the physical laws of authentic images, providing a unified authenticity anchor for the model. Experiments confirm that FakeVLM-R1 achieves SOTA performance the evaluated models across multiple benchmarks. It not only achieves high-precision, logically interpretable detection but also resolves the over-rejection bias of existing methods against real images, demonstrating generalization and robustness against perturbations.
Mind-Brush: Integrating Agentic Cognitive Search and Reasoning into Image Generation
Feb 02, 2026While text-to-image generation has achieved unprecedented fidelity, the vast majority of existing models function fundamentally as static text-to-pixel decoders. Consequently, they often fail to grasp implicit user intentions. Although emerging unified understanding-generation models have improved intent comprehension, they still struggle to accomplish tasks involving complex knowledge reasoning within a single model. Moreover, constrained by static internal priors, these models remain unable to adapt to the evolving dynamics of the real world. To bridge these gaps, we introduce Mind-Brush, a unified agentic framework that transforms generation into a dynamic, knowledge-driven workflow. Simulating a human-like 'think-research-create' paradigm, Mind-Brush actively retrieves multimodal evidence to ground out-of-distribution concepts and employs reasoning tools to resolve implicit visual constraints. To rigorously evaluate these capabilities, we propose Mind-Bench, a comprehensive benchmark comprising 500 distinct samples spanning real-time news, emerging concepts, and domains such as mathematical and Geo-Reasoning. Extensive experiments demonstrate that Mind-Brush significantly enhances the capabilities of unified models, realizing a zero-to-one capability leap for the Qwen-Image baseline on Mind-Bench, while achieving superior results on established benchmarks like WISE and RISE.
Echo-4o: Harnessing the Power of GPT-4o Synthetic Images for Improved Image Generation
Aug 13, 2025



Recently, GPT-4o has garnered significant attention for its strong performance in image generation, yet open-source models still lag behind. Several studies have explored distilling image data from GPT-4o to enhance open-source models, achieving notable progress. However, a key question remains: given that real-world image datasets already constitute a natural source of high-quality data, why should we use GPT-4o-generated synthetic data? In this work, we identify two key advantages of synthetic images. First, they can complement rare scenarios in real-world datasets, such as surreal fantasy or multi-reference image generation, which frequently occur in user queries. Second, they provide clean and controllable supervision. Real-world data often contains complex background noise and inherent misalignment between text descriptions and image content, whereas synthetic images offer pure backgrounds and long-tailed supervision signals, facilitating more accurate text-to-image alignment. Building on these insights, we introduce Echo-4o-Image, a 180K-scale synthetic dataset generated by GPT-4o, harnessing the power of synthetic image data to address blind spots in real-world coverage. Using this dataset, we fine-tune the unified multimodal generation baseline Bagel to obtain Echo-4o. In addition, we propose two new evaluation benchmarks for a more accurate and challenging assessment of image generation capabilities: GenEval++, which increases instruction complexity to mitigate score saturation, and Imagine-Bench, which focuses on evaluating both the understanding and generation of imaginative content. Echo-4o demonstrates strong performance across standard benchmarks. Moreover, applying Echo-4o-Image to other foundation models (e.g., OmniGen2, BLIP3-o) yields consistent performance gains across multiple metrics, highlighting the datasets strong transferability.
Knock-Knock: Acoustic Object Recognition by using Stacked Denoising Autoencoders
Aug 15, 2017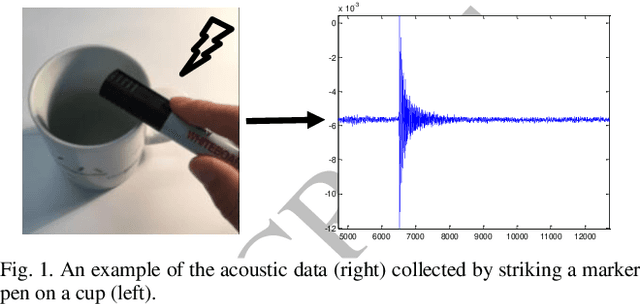
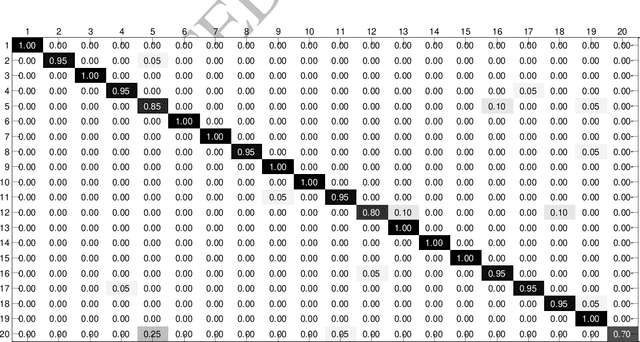
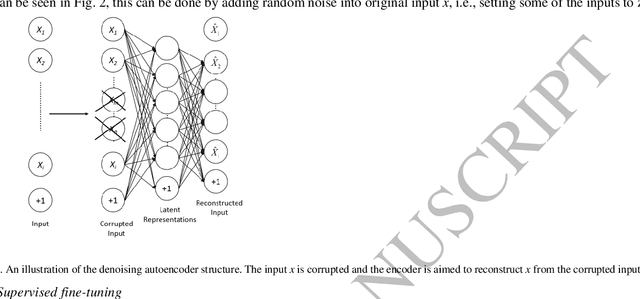
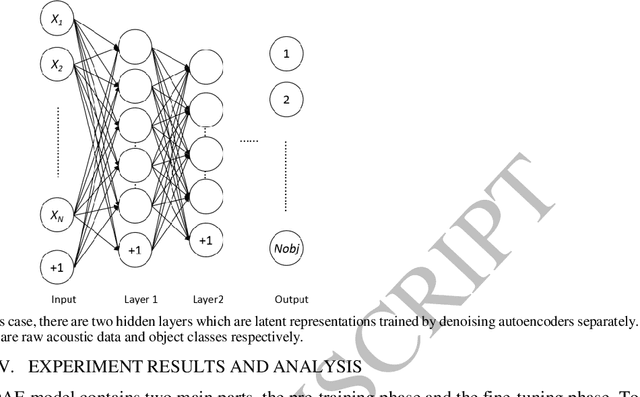
This paper presents a successful application of deep learning for object recognition based on acoustic data. The shortcomings of previously employed approaches where handcrafted features describing the acoustic data are being used, include limiting the capability of the found representation to be widely applicable and facing the risk of capturing only insignificant characteristics for a task. In contrast, there is no need to define the feature representation format when using multilayer/deep learning architecture methods: features can be learned from raw sensor data without defining discriminative characteristics a-priori. In this paper, stacked denoising autoencoders are applied to train a deep learning model. Knocking each object in our test set 120 times with a marker pen to obtain the auditory data, thirty different objects were successfully classified in our experiment and each object was knocked 120 times by a marker pen to obtain the auditory data. By employing the proposed deep learning framework, a high accuracy of 91.50% was achieved. A traditional method using handcrafted features with a shallow classifier was taken as a benchmark and the attained recognition rate was only 58.22%. Interestingly, a recognition rate of 82.00% was achieved when using a shallow classifier with raw acoustic data as input. In addition, we could show that the time taken to classify one object using deep learning was far less (by a factor of more than 6) than utilizing the traditional method. It was also explored how different model parameters in our deep architecture affect the recognition performance.