 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategic priorities for transformative progress in advancing biology with proteomics and artificial intelligence
Feb 21, 2025

Artificial intelligence (AI) is transforming scientific research, including proteomics. Advances in mass spectrometry (MS)-based proteomics data quality, diversity, and scale, combined with groundbreaking AI techniques, are unlocking new challenges and opportunities in biological discovery. Here, we highlight key areas where AI is driving innovation, from data analysis to new biological insights. These include developing an AI-friendly ecosystem for proteomics data generation, sharing, and analysis; improving peptide and protein identification and quantification; characterizing protein-protein interactions and protein complexes; advancing spatial and perturbation proteomics; integrating multi-omics data; and ultimately enabling AI-empowered virtual cells.
Rumor Detection by Multi-task Suffix Learning based on Time-series Dual Sentiments
Feb 20, 2025



The widespread dissemination of rumors on social media has a significant impact on people's lives, potentially leading to public panic and fear. Rumors often evoke specific sentiments, resonating with readers and prompting sharing. To effectively detect and track rumors, it is essential to observe the fine-grained sentiments of both source and response message pairs as the rumor evolves over time. However, current rumor detection methods fail to account for this aspect. In this paper, we propose MSuf, the first multi-task suffix learning framework for rumor detection and tracking using time series dual (coupled) sentiments. MSuf includes three modules: (1) an LLM to extract sentiment intensity features and sort them chronologically; (2) a module that fuses the sorted sentiment features with their source text word embeddings to obtain an aligned embedding; (3) two hard prompts are combined with the aligned vector to perform rumor detection and sentiment analysis using one frozen LLM. MSuf effectively enhances the performance of LLMs for rumor detection with only minimal parameter fine-tuning. Evaluating MSuf on four rumor detection benchmarks, we find significant improvements compared to other emotion-based methods.
TACO: Learning Multi-modal Action Models with Synthetic Chains-of-Thought-and-Action
Dec 10, 2024



While open-source multi-modal language models perform well on simple question answering tasks, they often fail on complex questions that require multiple capabilities, such as fine-grained recognition, visual grounding, and reasoning, and that demand multi-step solutions. We present TACO, a family of multi-modal large action models designed to improve performance on such complex, multi-step, and multi-modal tasks. During inference, TACO produces chains-of-thought-and-action (CoTA), executes intermediate steps by invoking external tools such as OCR, depth estimation and calculator, then integrates both the thoughts and action outputs to produce coherent responses. To train TACO, we create a large dataset of over 1M synthetic CoTA traces generated with GPT-4o and Python programs. We then experiment with various data filtering and mixing techniques and obtain a final subset of 293K high-quality CoTA examples. This dataset enables TACO to learn complex reasoning and action paths, surpassing existing models trained on instruction tuning data with only direct answers. Our model TACO outperforms the instruction-tuned baseline across 8 benchmarks, achieving a 3.6% improvement on average, with gains of up to 15% in MMVet tasks involving OCR, mathematical reasoning, and spatial reasoning. Training on high-quality CoTA traces sets a new standard for complex multi-modal reasoning, highlighting the need for structured, multi-step instruction tuning in advancing open-source mutli-modal models' capabilities.
Graph-Sequential Alignment and Uniformity: Toward Enhanced Recommendation Systems
Dec 05, 2024



Graph-based and sequential methods are two popular recommendation paradigms, each excelling in its domain but lacking the ability to leverage signals from the other. To address this, we propose a novel method that integrates both approaches for enhanced performance. Our framework uses Graph Neural Network (GNN)-based and sequential recommenders as separate submodules while sharing a unified embedding space optimized jointly. To enable positive knowledge transfer, we design a loss function that enforces alignment and uniformity both within and across submodules. Experiments on three real-world datasets demonstrate that the proposed method significantly outperforms using either approach alone and achieves state-of-the-art results. Our implementations are publicly available at https://github.com/YuweiCao-UIC/GSAU.git.
SpecTool: A Benchmark for Characterizing Errors in Tool-Use LLMs
Nov 20, 2024



Evaluating the output of Large Language Models (LLMs) is one of the most critical aspects of building a performant compound AI system. Since the output from LLMs propagate to downstream steps, identifying LLM errors is crucial to system performance. A common task for LLMs in AI systems is tool use. While there are several benchmark environments for evaluating LLMs on this task, they typically only give a success rate without any explanation of the failure cases. To solve this problem, we introduce SpecTool, a new benchmark to identify error patterns in LLM output on tool-use tasks. Our benchmark data set comprises of queries from diverse environments that can be used to test for the presence of seven newly characterized error patterns. Using SPECTOOL , we show that even the most prominent LLMs exhibit these error patterns in their outputs. Researchers can use the analysis and insights from SPECTOOL to guide their error mitigation strategies.
MonoRollBot: 3-DOF Spherical Robot with Underactuated Single Compliant Actuator Design
Nov 06, 2024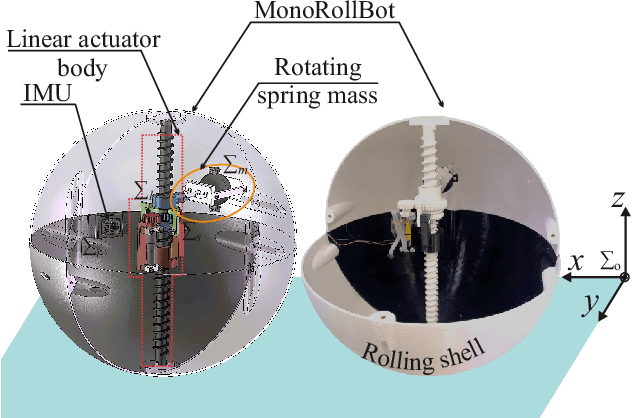
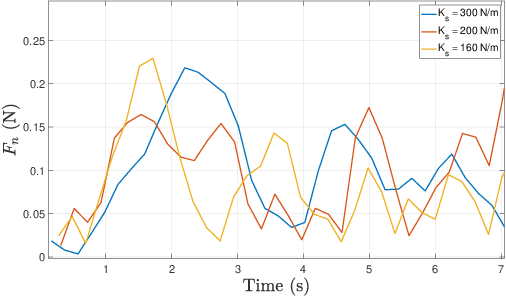
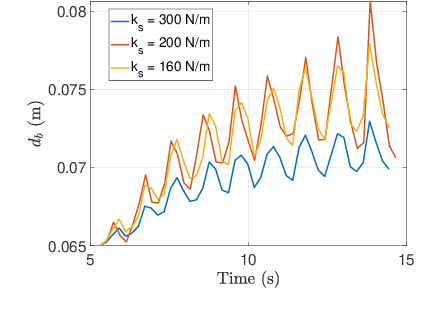
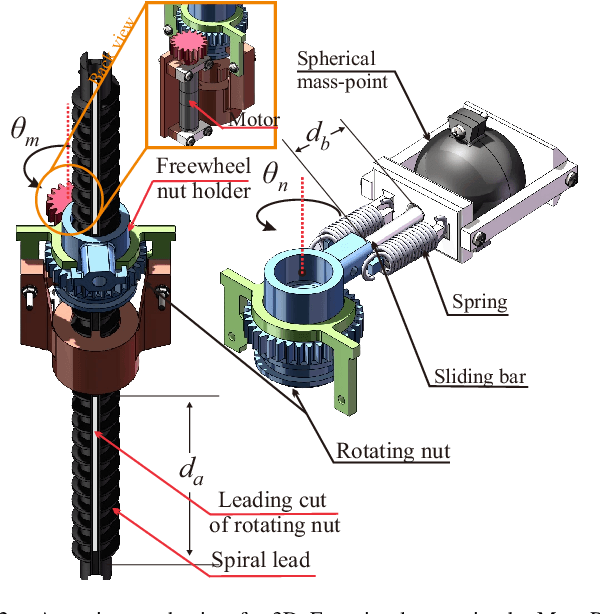
Spherical rolling robots have garnered significant attention in the field of mobile robotics for applications such as inspection and space exploration. Designing underactuated rolling robots poses challenges in achieving multi-directional propulsion with high degrees of freedom while utilizing a limited number of actuators. This paper presents the MonoRollBot, a novel 3-degree-of-freedom (DOF) spherical robot that utilizes an underactuated mechanism driven by only a single spring-motor system. Unlike conventional spherical robots, MonoRollBot employs a minimalist actuation approach, relying on only one motor and a passive spring to control its locomotion. The robot achieves 3-DOF motion through an innovative coupling of spring dynamics and motor control. In this work, we detail the design of the MonoRollBot and evaluate its motion capabilities through design studies. We also do studies on its locomotion behaviours based on changes in rotating mass and stiffness properties.
PRACT: Optimizing Principled Reasoning and Acting of LLM Agent
Oct 24, 2024



We introduce the Principled Reasoning and Acting (PRAct) framework, a novel method for learning and enforcing action principles from trajectory data. Central to our approach is the use of text gradients from a reflection and optimization engine to derive these action principles. To adapt action principles to specific task requirements, we propose a new optimization framework, Reflective Principle Optimization (RPO). After execution, RPO employs a reflector to critique current action principles and an optimizer to update them accordingly. We develop the RPO framework under two scenarios: Reward-RPO, which uses environmental rewards for reflection, and Self-RPO, which conducts self-reflection without external rewards. Additionally, two RPO methods, RPO-Traj and RPO-Batch, is introduced to adapt to different settings. Experimental results across four environments demonstrate that the PRAct agent, leveraging the RPO framework, effectively learns and applies action principles to enhance performance.
CoMAL: Collaborative Multi-Agent Large Language Models for Mixed-Autonomy Traffic
Oct 18, 2024



The integration of autonomous vehicles into urban traffic has great potential to improve efficiency by reducing congestion and optimizing traffic flow systematically. In this paper, we introduce CoMAL (Collaborative Multi-Agent LLMs), a framework designed to address the mixed-autonomy traffic problem by collaboration among autonomous vehicles to optimize traffic flow. CoMAL is built upon large language models, operating in an interactive traffic simulation environment. It utilizes a Perception Module to observe surrounding agents and a Memory Module to store strategies for each agent. The overall workflow includes a Collaboration Module that encourages autonomous vehicles to discuss the effective strategy and allocate roles, a reasoning engine to determine optimal behaviors based on assigned roles, and an Execution Module that controls vehicle actions using a hybrid approach combining rule-based models. Experimental results demonstrate that CoMAL achieves superior performance on the Flow benchmark. Additionally, we evaluate the impact of different language models and compare our framework with reinforcement learning approaches. It highlights the strong cooperative capability of LLM agents and presents a promising solution to the mixed-autonomy traffic challenge. The code is available at https://github.com/Hyan-Yao/CoMAL.
FMDLlama: Financial Misinformation Detection based on Large Language Models
Sep 24, 2024The emergence of social media has made the spread of misinformation easier. In the financial domain, the accuracy of information is crucial for various aspects of financial market, which has made financial misinformation detection (FMD) an urgent problem that needs to be addressed. Large language models (LLMs) have demonstrated outstanding performance in various fields. However, current studies mostly rely on traditional methods and have not explored the application of LLMs in the field of FMD. The main reason is the lack of FMD instruction tuning datasets and evaluation benchmarks. In this paper, we propose FMDLlama, the first open-sourced instruction-following LLMs for FMD task based on fine-tuning Llama3.1 with instruction data, the first multi-task FMD instruction dataset (FMDID) to support LLM instruction tuning, and a comprehensive FMD evaluation benchmark (FMD-B) with classification and explanation generation tasks to test the FMD ability of LLMs. We compare our models with a variety of LLMs on FMD-B, where our model outperforms all other open-sourced LLMs as well as ChatGPT.
xLAM: A Family of Large Action Models to Empower AI Agent Systems
Sep 05, 2024



Autonomous agents powered by large language models (LLMs) have attracted significant research interest. However, the open-source community faces many challenges in developing specialized models for agent tasks, driven by the scarcity of high-quality agent datasets and the absence of standard protocols in this area. We introduce and publicly release xLAM, a series of large action models designed for AI agent tasks. The xLAM series includes five models with both dense and mixture-of-expert architectures, ranging from 1B to 8x22B parameters, trained using a scalable, flexible pipeline that unifies, augments, and synthesizes diverse datasets to enhance AI agents' generalizability and performance across varied environments. Our experimental results demonstrate that xLAM consistently delivers exceptional performance across multiple agent ability benchmarks, notably securing the 1st position on the Berkeley Function-Calling Leaderboard, outperforming GPT-4, Claude-3, and many other models in terms of tool use. By releasing the xLAM series, we aim to advance the performance of open-source LLMs for autonomous AI agents, potentially accelerating progress and democratizing access to high-performance models for agent tasks. Models are available at https://huggingface.co/collections/Salesforce/xlam-models-65f00e2a0a63bbcd1c2dade4