 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciCUEval: A Comprehensive Dataset for Evaluating Scientific Context Understanding in Large Language Models
May 21, 2025


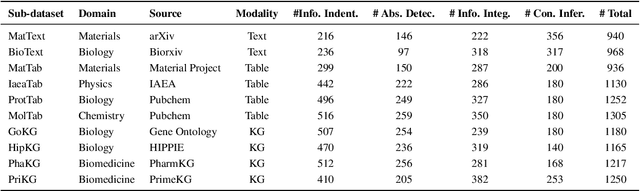
Large Language Models (LLMs) have shown impressive capabilities in contextual understanding and reasoning. However, evaluating their performance across diverse scientific domains remains underexplored, as existing benchmarks primarily focus on general domains and fail to capture the intricate complexity of scientific data. To bridge this gap, we construct SciCUEval, a comprehensive benchmark dataset tailored to assess the scientific context understanding capability of LLMs. It comprises ten domain-specific sub-datasets spanning biology, chemistry, physics, biomedicine, and materials science, integrating diverse data modalities including structured tables, knowledge graphs, and unstructured texts. SciCUEval systematically evaluates four core competencies: Relevant information identification, Information-absence detection, Multi-source information integration, and Context-aware inference, through a variety of question formats. We conduct extensive evaluations of state-of-the-art LLMs on SciCUEval, providing a fine-grained analysis of their strengths and limitations in scientific context understanding, and offering valuable insights for the future development of scientific-domain LLMs.
Relation-Aware Graph Foundation Model
May 17, 2025In recent years, large language models (LLMs) have demonstrated remarkable generalization capabilities across various natural language processing (NLP) tasks. Similarly, graph foundation models (GFMs) have emerged as a promising direction in graph learning, aiming to generalize across diverse datasets through large-scale pre-training. However, unlike language models that rely on explicit token representations, graphs lack a well-defined unit for generalization, making it challenging to design effective pre-training strategies. In this work, we propose REEF, a novel framework that leverages relation tokens as the basic units for GFMs. Inspired by the token vocabulary in LLMs, we construct a relation vocabulary of relation tokens to store relational information within graphs. To accommodate diverse relations, we introduce two hypernetworks that adaptively generate the parameters of aggregators and classifiers in graph neural networks based on relation tokens. In addition, we design another hypernetwork to construct dataset-specific projectors and incorporate a dataset-level feature bias into the initial node representations, enhancing flexibility across different datasets with the same relation. Further, we adopt graph data augmentation and a mixed-dataset pre-training strategy, allowing REEF to capture relational diversity more effectively and exhibit strong generalization capabilities. Extensive experiments show that REEF significantly outperforms existing methods on both pre-training and transfer learning tasks, underscoring its potential as a powerful foundation model for graph-based applications.
RV-Syn: Rational and Verifiable Mathematical Reasoning Data Synthesis based on Structured Function Library
Apr 29, 2025The advancement of reasoning capabilities in Large Language Models (LLMs) requires substantial amounts of high-quality reasoning data, particularly in mathematics. Existing data synthesis methods, such as data augmentation from annotated training sets or direct question generation based on relevant knowledge points and documents, have expanded datasets but face challenges in mastering the inner logic of the problem during generation and ensuring the verifiability of the solutions. To address these issues, we propose RV-Syn, a novel Rational and Verifiable mathematical Synthesis approach. RV-Syn constructs a structured mathematical operation function library based on initial seed problems and generates computational graphs as solutions by combining Python-formatted functions from this library. These graphs are then back-translated into complex problems. Based on the constructed computation graph, we achieve solution-guided logic-aware problem generation. Furthermore, the executability of the computational graph ensures the verifiability of the solving process. Experimental results show that RV-Syn surpasses existing synthesis methods, including those involving human-generated problems, achieving greater efficient data scaling. This approach provides a scalable framework for generating high-quality reasoning datasets.
POLYRAG: Integrating Polyviews into Retrieval-Augmented Generation for Medical Applications
Apr 21, 2025



Large language models (LLMs) have become a disruptive force in the industry, introducing unprecedented capabilities in natural language processing, logical reasoning and so on. However, the challenges of knowledge updates and hallucination issues have limited the application of LLMs in medical scenarios, where retrieval-augmented generation (RAG) can offer significant assistance. Nevertheless, existing retrieve-then-read approaches generally digest the retrieved documents, without considering the timeliness, authoritativeness and commonality of retrieval. We argue that these approaches can be suboptimal, especially in real-world applications where information from different sources might conflict with each other and even information from the same source in different time scale might be different, and totally relying on this would deteriorate the performance of RAG approaches. We propose PolyRAG that carefully incorporate judges from different perspectives and finally integrate the polyviews for retrieval augmented generation in medical applications. Due to the scarcity of real-world benchmarks for evaluation, to bridge the gap we propose PolyEVAL, a benchmark consists of queries and documents collected from real-world medical scenarios (including medical policy, hospital & doctor inquiry and healthcare) with multiple tagging (e.g., timeliness, authoritativeness) on them. Extensive experiments and analysis on PolyEVAL have demonstrated the superiority of PolyRAG.
LookAhead Tuning: Safer Language Models via Partial Answer Previews
Mar 24, 2025



Fine-tuning enables large language models (LLMs) to adapt to specific domains, but often undermines their previously established safety alignment. To mitigate the degradation of model safety during fine-tuning, we introduce LookAhead Tuning, which comprises two simple, low-resource, and effective data-driven methods that modify training data by previewing partial answer prefixes. Both methods aim to preserve the model's inherent safety mechanisms by minimizing perturbations to initial token distributions. Comprehensive experiments demonstrate that LookAhead Tuning effectively maintains model safety without sacrificing robust performance on downstream tasks. Our findings position LookAhead Tuning as a reliable and efficient solution for the safe and effective adaptation of LLMs. Code is released at https://github.com/zjunlp/LookAheadTuning.
MASS: Mathematical Data Selection via Skill Graphs for Pretraining Large Language Models
Mar 19, 2025



High-quality data plays a critical role in the pretraining and fine-tuning of large language models (LLMs), even determining their performance ceiling to some degree. Consequently, numerous data selection methods have been proposed to identify subsets of data that can effectively and efficiently enhance model performance. However, most of these methods focus on general data selection and tend to overlook the specific nuances of domain-related data. In this paper, we introduce MASS, a \textbf{MA}thematical data \textbf{S}election framework using the \textbf{S}kill graph for pretraining LLMs in the mathematical reasoning domain. By taking into account the unique characteristics of mathematics and reasoning, we construct a skill graph that captures the mathematical skills and their interrelations from a reference dataset. This skill graph guides us in assigning quality scores to the target dataset, enabling us to select the top-ranked subset which is further used to pretrain LLMs. Experimental results demonstrate the efficiency and effectiveness of MASS across different model sizes (1B and 7B) and pretraining datasets (web data and synthetic data). Specifically, in terms of efficiency, models trained on subsets selected by MASS can achieve similar performance to models trained on the original datasets, with a significant reduction in the number of trained tokens - ranging from 50\% to 70\% fewer tokens. In terms of effectiveness, when trained on the same amount of tokens, models trained on the data selected by MASS outperform those trained on the original datasets by 3.3\% to 5.9\%. These results underscore the potential of MASS to improve both the efficiency and effectiveness of pretraining LLMs.
Unlocking General Long Chain-of-Thought Reasoning Capabilities of Large Language Models via Representation Engineering
Mar 14, 2025



Recent advancements in long chain-of-thoughts(long CoTs) have significantly improved the reasoning capabilities of large language models(LLMs). Existing work finds that the capability of long CoT reasoning can be efficiently elicited by tuning on only a few examples and can easily transfer to other tasks. This motivates us to investigate whether long CoT reasoning is a general capability for LLMs. In this work, we conduct an empirical analysis for this question from the perspective of representation. We find that LLMs do encode long CoT reasoning as a general capability, with a clear distinction from vanilla CoTs. Furthermore, domain-specific representations are also required for the effective transfer of long CoT reasoning. Inspired by these findings, we propose GLoRE, a novel representation engineering method to unleash the general long CoT reasoning capabilities of LLMs. Extensive experiments demonstrate the effectiveness and efficiency of GLoRE in both in-domain and cross-domain scenarios.
Stick to Facts: Towards Fidelity-oriented Product Description Generation
Mar 12, 2025Different from other text generation tasks, in product description generation, it is of vital importance to generate faithful descriptions that stick to the product attribute information. However, little attention has been paid to this problem. To bridge this gap, we propose a model named Fidelity-oriented Product Description Generator (FPDG). FPDG takes the entity label of each word into account, since the product attribute information is always conveyed by entity words. Specifically, we first propose a Recurrent Neural Network (RNN) decoder based on the Entity-label-guided Long Short-Term Memory (ELSTM) cell, taking both the embedding and the entity label of each word as input. Second, we establish a keyword memory that stores the entity labels as keys and keywords as values, allowing FPDG to attend to keywords by attending to their entity labels. Experiments conducted on a large-scale real-world product description dataset show that our model achieves state-of-the-art performance in terms of both traditional generation metrics and human evaluations. Specifically, FPDG increases the fidelity of the generated descriptions by 25%.
Every FLOP Counts: Scaling a 300B Mixture-of-Experts LING LLM without Premium GPUs
Mar 07, 2025



In this technical report, we tackle the challenges of training large-scale Mixture of Experts (MoE) models, focusing on overcoming cost inefficiency and resource limitations prevalent in such systems. To address these issues, we present two differently sized MoE large language models (LLMs), namely Ling-Lite and Ling-Plus (referred to as "Bailing" in Chinese, spelled B\v{a}il\'ing in Pinyin). Ling-Lite contains 16.8 billion parameters with 2.75 billion activated parameters, while Ling-Plus boasts 290 billion parameters with 28.8 billion activated parameters. Both models exhibit comparable performance to leading industry benchmarks. This report offers actionable insights to improve the efficiency and accessibility of AI development in resource-constrained settings, promoting more scalable and sustainable technologies. Specifically, to reduce training costs for large-scale MoE models, we propose innovative methods for (1) optimization of model architecture and training processes, (2) refinement of training anomaly handling, and (3) enhancement of model evaluation efficiency. Additionally, leveraging high-quality data generated from knowledge graphs, our models demonstrate superior capabilities in tool use compared to other models. Ultimately, our experimental findings demonstrate that a 300B MoE LLM can be effectively trained on lower-performance devices while achieving comparable performance to models of a similar scale, including dense and MoE models. Compared to high-performance devices, utilizing a lower-specification hardware system during the pre-training phase demonstrates significant cost savings, reducing computing costs by approximately 20%. The models can be accessed at https://huggingface.co/inclusionAI.
Bi'an: A Bilingual Benchmark and Model for Hallucination Detection in Retrieval-Augmented Generation
Feb 26, 2025Retrieval-Augmented Generation (RAG) effectively reduces hallucinations in Large Language Models (LLMs) but can still produce inconsistent or unsupported content. Although LLM-as-a-Judge is widely used for RAG hallucination detection due to its implementation simplicity, it faces two main challenges: the absence of comprehensive evaluation benchmarks and the lack of domain-optimized judge models. To bridge these gaps, we introduce \textbf{Bi'an}, a novel framework featuring a bilingual benchmark dataset and lightweight judge models. The dataset supports rigorous evaluation across multiple RAG scenarios, while the judge models are fine-tuned from compact open-source LLMs. Extensive experimental evaluations on Bi'anBench show our 14B model outperforms baseline models with over five times larger parameter scales and rivals state-of-the-art closed-source LLMs. We will release our data and models soon at https://github.com/OpenSPG/KAG.