 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudCast: Audio-Driven Human Video Generation by Cascaded Diffusion Transformers
Mar 25, 2025



Despite the recent progress of audio-driven video generation, existing methods mostly focus on driving facial movements, leading to non-coherent head and body dynamics. Moving forward, it is desirable yet challenging to generate holistic human videos with both accurate lip-sync and delicate co-speech gestures w.r.t. given audio. In this work, we propose AudCast, a generalized audio-driven human video generation framework adopting a cascade Diffusion-Transformers (DiTs) paradigm, which synthesizes holistic human videos based on a reference image and a given audio. 1) Firstly, an audio-conditioned Holistic Human DiT architecture is proposed to directly drive the movements of any human body with vivid gesture dynamics. 2) Then to enhance hand and face details that are well-knownly difficult to handle, a Regional Refinement DiT leverages regional 3D fitting as the bridge to reform the signals, producing the final results. Extensive experiments demonstrate that our framework generates high-fidelity audio-driven holistic human videos with temporal coherence and fine facial and hand details. Resources can be found at https://guanjz20.github.io/projects/AudCast.
Cosh-DiT: Co-Speech Gesture Video Synthesis via Hybrid Audio-Visual Diffusion Transformers
Mar 13, 2025Co-speech gesture video synthesis is a challenging task that requires both probabilistic modeling of human gestures and the synthesis of realistic images that align with the rhythmic nuances of speech. To address these challenges, we propose Cosh-DiT, a Co-speech gesture video system with hybrid Diffusion Transformers that perform audio-to-motion and motion-to-video synthesis using discrete and continuous diffusion modeling, respectively. First, we introduce an audio Diffusion Transformer (Cosh-DiT-A) to synthesize expressive gesture dynamics synchronized with speech rhythms. To capture upper body, facial, and hand movement priors, we employ vector-quantized variational autoencoders (VQ-VAEs) to jointly learn their dependencies within a discrete latent space. Then, for realistic video synthesis conditioned on the generated speech-driven motion, we design a visual Diffusion Transformer (Cosh-DiT-V) that effectively integrates spatial and temporal contexts. Extensive experiments demonstrate that our framework consistently generates lifelike videos with expressive facial expressions and natural, smooth gestures that align seamlessly with speech.
TALK-Act: Enhance Textural-Awareness for 2D Speaking Avatar Reenactment with Diffusion Model
Oct 14, 2024



Recently, 2D speaking avatars have increasingly participated in everyday scenarios due to the fast development of facial animation techniques. However, most existing works neglect the explicit control of human bodies. In this paper, we propose to drive not only the faces but also the torso and gesture movements of a speaking figure. Inspired by recent advances in diffusion models, we propose the Motion-Enhanced Textural-Aware ModeLing for SpeaKing Avatar Reenactment (TALK-Act) framework, which enables high-fidelity avatar reenactment from only short footage of monocular video. Our key idea is to enhance the textural awareness with explicit motion guidance in diffusion modeling. Specifically, we carefully construct 2D and 3D structural information as intermediate guidance. While recent diffusion models adopt a side network for control information injection, they fail to synthesize temporally stable results even with person-specific fine-tuning. We propose a Motion-Enhanced Textural Alignment module to enhance the bond between driving and target signals. Moreover, we build a Memory-based Hand-Recovering module to help with the difficulties in hand-shape preserving. After pre-training, our model can achieve high-fidelity 2D avatar reenactment with only 30 seconds of person-specific data. Extensive experiments demonstrate the effectiveness and superiority of our proposed framework. Resources can be found at https://guanjz20.github.io/projects/TALK-Act.
ReSyncer: Rewiring Style-based Generator for Unified Audio-Visually Synced Facial Performer
Aug 06, 2024



Lip-syncing videos with given audio is the foundation for various applications including the creation of virtual presenters or performers. While recent studies explore high-fidelity lip-sync with different techniques, their task-orientated models either require long-term videos for clip-specific training or retain visible artifacts. In this paper, we propose a unified and effective framework ReSyncer, that synchronizes generalized audio-visual facial information. The key design is revisiting and rewiring the Style-based generator to efficiently adopt 3D facial dynamics predicted by a principled style-injected Transformer. By simply re-configuring the information insertion mechanisms within the noise and style space, our framework fuses motion and appearance with unified training. Extensive experiments demonstrate that ReSyncer not only produces high-fidelity lip-synced videos according to audio, but also supports multiple appealing properties that are suitable for creating virtual presenters and performers, including fast personalized fine-tuning, video-driven lip-syncing, the transfer of speaking styles, and even face swapping. Resources can be found at https://guanjz20.github.io/projects/ReSyncer.
Learning in a Single Domain for Non-Stationary Multi-Texture Synthesis
May 10, 2023This paper aims for a new generation task: non-stationary multi-texture synthesis, which unifies synthesizing multiple non-stationary textures in a single model. Most non-stationary textures have large scale variance and can hardly be synthesized through one model. To combat this, we propose a multi-scale generator to capture structural patterns of various scales and effectively synthesize textures with a minor cost. However, it is still hard to handle textures of different categories with different texture patterns. Therefore, we present a category-specific training strategy to focus on learning texture pattern of a specific domain. Interestingly, once trained, our model is able to produce multi-pattern generations with dynamic variations without the need to finetune the model for different styles. Moreover, an objective evaluation metric is designed for evaluating the quality of texture expansion and global structure consistency. To our knowledge, ours is the first scheme for this challenging task, including model, training, and evaluation. Experimental results demonstrate the proposed method achieves superior performance and time efficiency. The code will be available after the publication.
StyleSwap: Style-Based Generator Empowers Robust Face Swapping
Sep 27, 2022
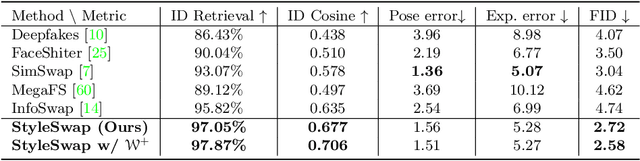
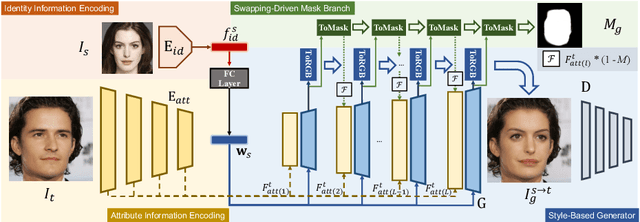

Numerous attempts have been made to the task of person-agnostic face swapping given its wide applications. While existing methods mostly rely on tedious network and loss designs, they still struggle in the information balancing between the source and target faces, and tend to produce visible artifacts. In this work, we introduce a concise and effective framework named StyleSwap. Our core idea is to leverage a style-based generator to empower high-fidelity and robust face swapping, thus the generator's advantage can be adopted for optimizing identity similarity. We identify that with only minimal modifications, a StyleGAN2 architecture can successfully handle the desired information from both source and target. Additionally, inspired by the ToRGB layers, a Swapping-Driven Mask Branch is further devised to improve information blending. Furthermore, the advantage of StyleGAN inversion can be adopted. Particularly, a Swapping-Guided ID Inversion strategy is proposed to optimize identity similarity. Extensive experiments validate that our framework generates high-quality face swapping results that outperform state-of-the-art methods both qualitatively and quantitatively.
MobileFaceSwap: A Lightweight Framework for Video Face Swapping
Jan 11, 2022
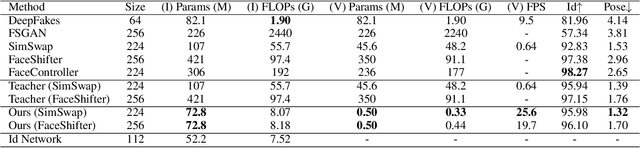
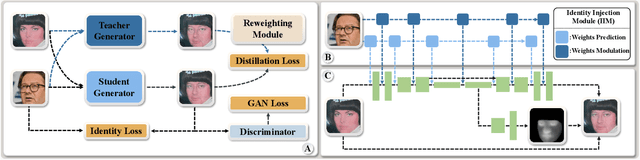
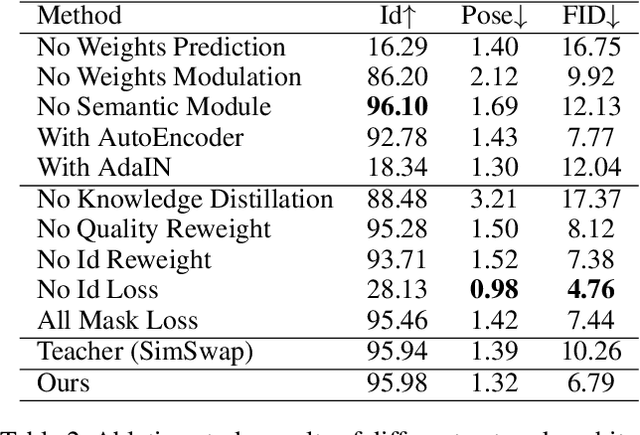
Advanced face swapping methods have achieved appealing results. However, most of these methods have many parameters and computations, which makes it challenging to apply them in real-time applications or deploy them on edge devices like mobile phones. In this work, we propose a lightweight Identity-aware Dynamic Network (IDN) for subject-agnostic face swapping by dynamically adjusting the model parameters according to the identity information. In particular, we design an efficient Identity Injection Module (IIM) by introducing two dynamic neural network techniques, including the weights prediction and weights modulation. Once the IDN is updated, it can be applied to swap faces given any target image or video. The presented IDN contains only 0.50M parameters and needs 0.33G FLOPs per frame, making it capable for real-time video face swapping on mobile phones. In addition, we introduce a knowledge distillation-based method for stable training, and a loss reweighting module is employed to obtain better synthesized results. Finally, our method achieves comparable results with the teacher models and other state-of-the-art methods.
DFGC 2021: A DeepFake Game Competition
Jun 02, 2021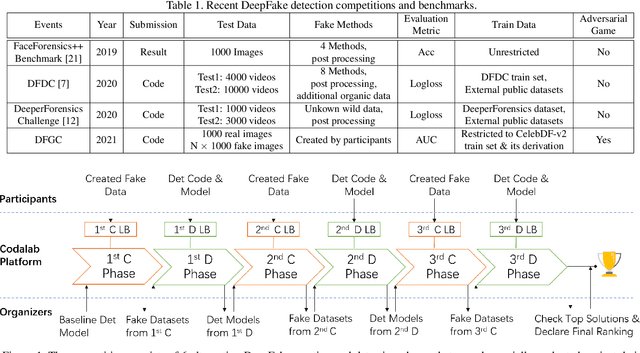
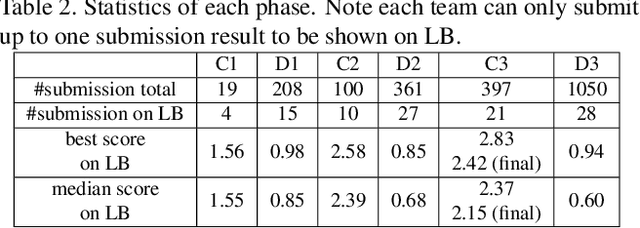
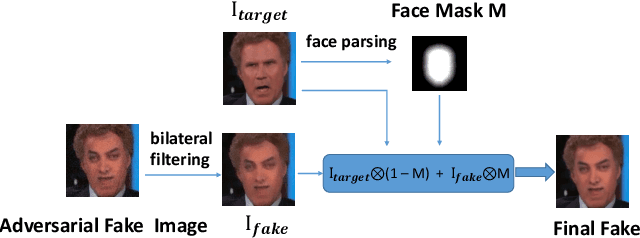
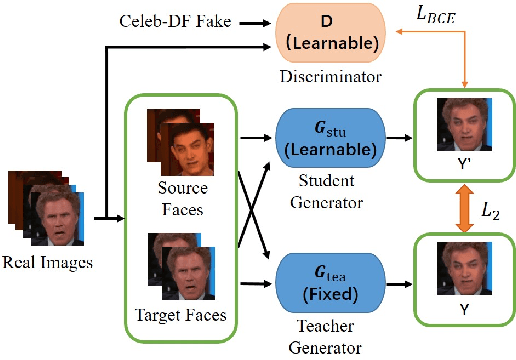
This paper presents a summary of the DFGC 2021 competition. DeepFake technology is developing fast, and realistic face-swaps are increasingly deceiving and hard to detect. At the same time, DeepFake detection methods are also improving. There is a two-party game between DeepFake creators and detectors. This competition provides a common platform for benchmarking the adversarial game between current state-of-the-art DeepFake creation and detection methods. In this paper, we present the organization, results and top solutions of this competition and also share our insights obtained during this event. We also release the DFGC-21 testing dataset collected from our participants to further benefit the research community.
FaceController: Controllable Attribute Editing for Face in the Wild
Feb 23, 2021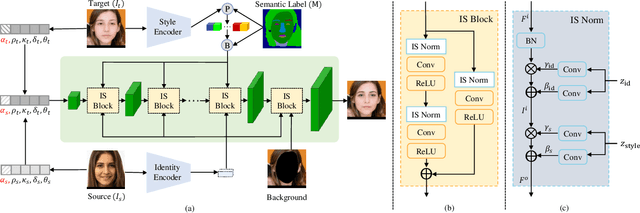
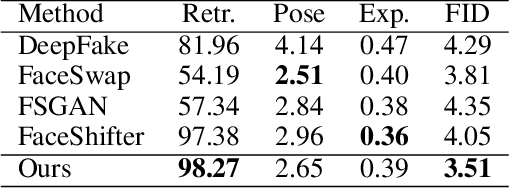
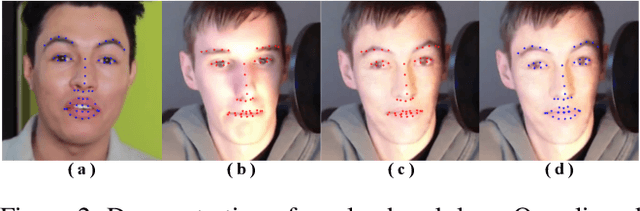
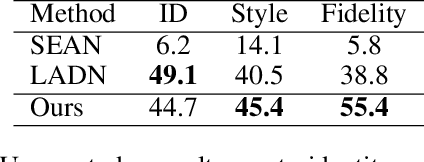
Face attribute editing aims to generate faces with one or multiple desired face attributes manipulated while other details are preserved. Unlike prior works such as GAN inversion, which has an expensive reverse mapping process, we propose a simple feed-forward network to generate high-fidelity manipulated faces. By simply employing some existing and easy-obtainable prior information, our method can control, transfer, and edit diverse attributes of faces in the wild. The proposed method can consequently be applied to various applications such as face swapping, face relighting, and makeup transfer. In our method, we decouple identity, expression, pose, and illumination using 3D priors; separate texture and colors by using region-wise style codes. All the information is embedded into adversarial learning by our identity-style normalization module. Disentanglement losses are proposed to enhance the generator to extract information independently from each attribute. Comprehensive quantitative and qualitative evaluations have been conducted. In a single framework, our method achieves the best or competitive scores on a variety of face applications.
Neural Time-Dependent Partial Differential Equation
Sep 08, 2020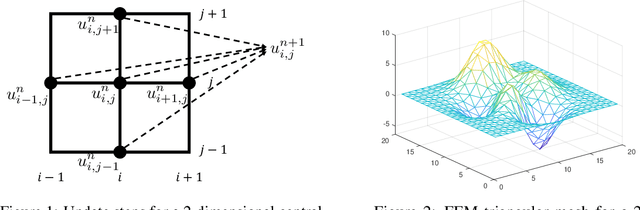
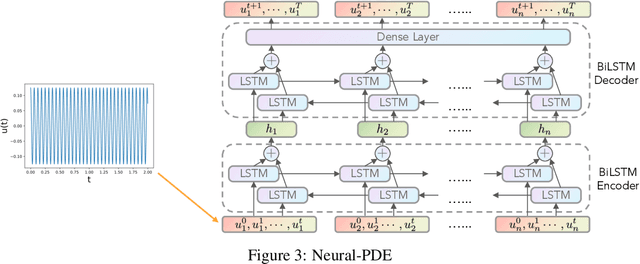
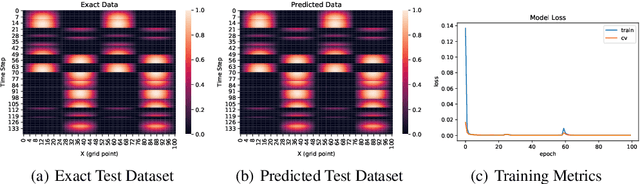
Partial differential equations (PDEs) play a crucial role in studying a vast number of problems in science and engineering. Numerically solving nonlinear and/or high-dimensional PDEs is often a challenging task. Inspired by the traditional finite difference and finite elements methods and emerging advancements in machine learning, we propose a sequence deep learning framework called Neural-PDE, which allows to automatically learn governing rules of any time-dependent PDE system from existing data by using a bidirectional LSTM encoder, and predict the next n time steps data. One critical feature of our proposed framework is that the Neural-PDE is able to simultaneously learn and simulate the multiscale variables.We test the Neural-PDE by a range of examples from one-dimensional PDEs to a high-dimensional and nonlinear complex fluids model. The results show that the Neural-PDE is capable of learning the initial conditions, boundary conditions and differential operators without the knowledge of the specific form of a PDE system.In our experiments the Neural-PDE can efficiently extract the dynamics within 20 epochs training, and produces accurate predictions. Furthermore, unlike the traditional machine learning approaches in learning PDE such as CNN and MLP which require vast parameters for model precision, Neural-PDE shares parameters across all time steps, thus considerably reduces the computational complexity and leads to a fast learning algorithm.