 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Object Detection for 3-D Point Clouds
May 04, 2020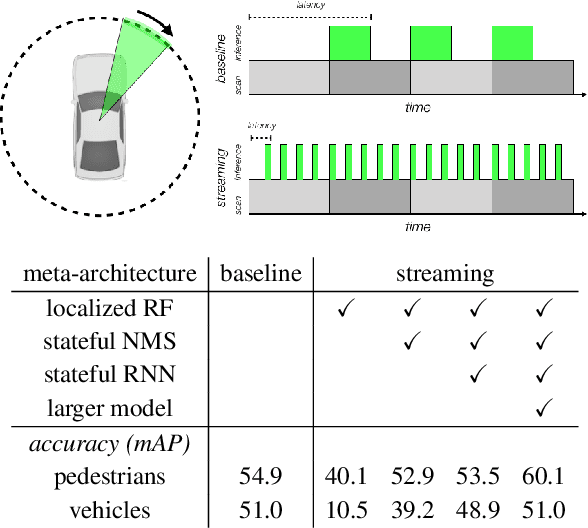
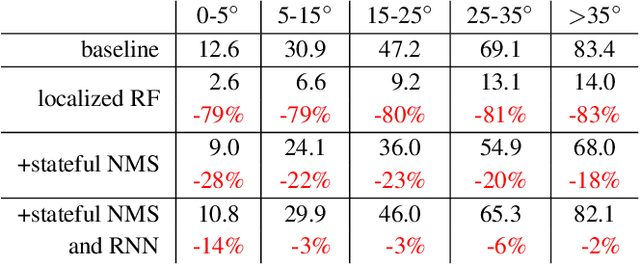
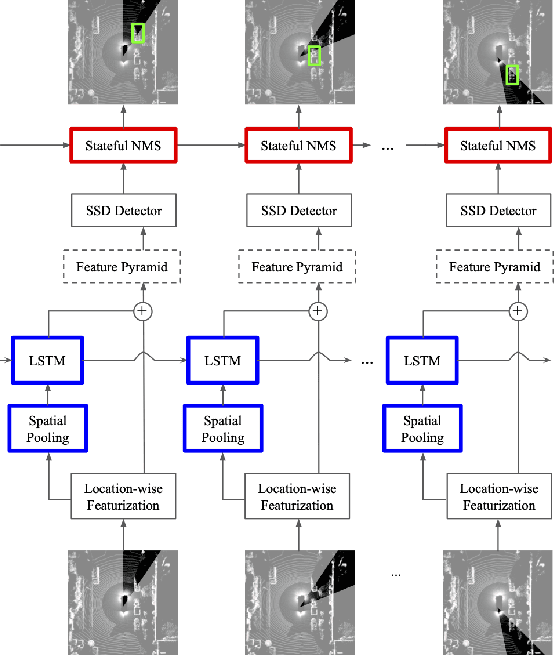
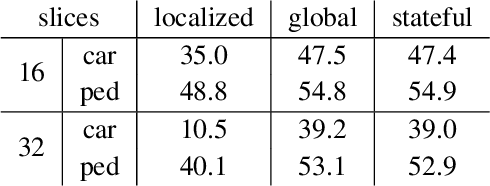
Autonomous vehicles operate in a dynamic environment, where the speed with which a vehicle can perceive and react impacts the safety and efficacy of the system. LiDAR provides a prominent sensory modality that informs many existing perceptual systems including object detection, segmentation, motion estimation, and action recognition. The latency for perceptual systems based on point cloud data can be dominated by the amount of time for a complete rotational scan (e.g. 100 ms). This built-in data capture latency is artificial, and based on treating the point cloud as a camera image in order to leverage camera-inspired architectures. However, unlike camera sensors, most LiDAR point cloud data is natively a streaming data source in which laser reflections are sequentially recorded based on the precession of the laser beam. In this work, we explore how to build an object detector that removes this artificial latency constraint, and instead operates on native streaming data in order to significantly reduce latency. This approach has the added benefit of reducing the peak computational burden on inference hardware by spreading the computation over the acquisition time for a scan. We demonstrate a family of streaming detection systems based on sequential modeling through a series of modifications to the traditional detection meta-architecture. We highlight how this model may achieve competitive if not superior predictive performance with state-of-the-art, traditional non-streaming detection systems while achieving significant latency gains (e.g. 1/15'th - 1/3'rd of peak latency). Our results show that operating on LiDAR data in its native streaming formulation offers several advantages for self driving object detection -- advantages that we hope will be useful for any LiDAR perception system where minimizing latency is critical for safe and efficient operation.
A Streaming On-Device End-to-End Model Surpassing Server-Side Conventional Model Quality and Latency
Mar 28, 2020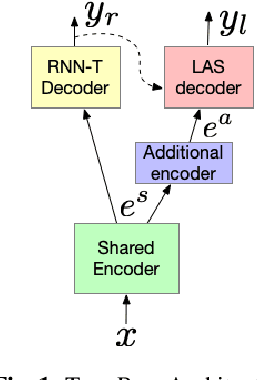
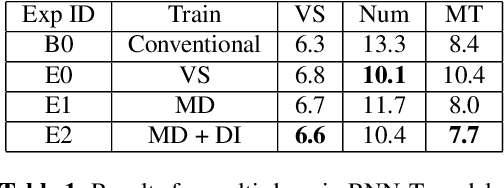
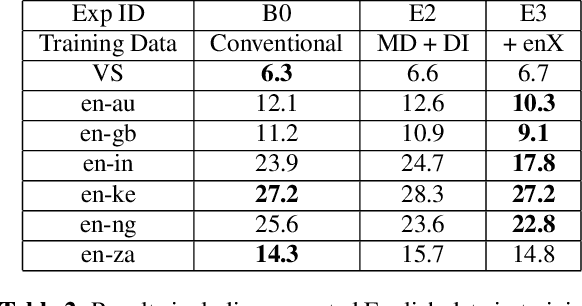
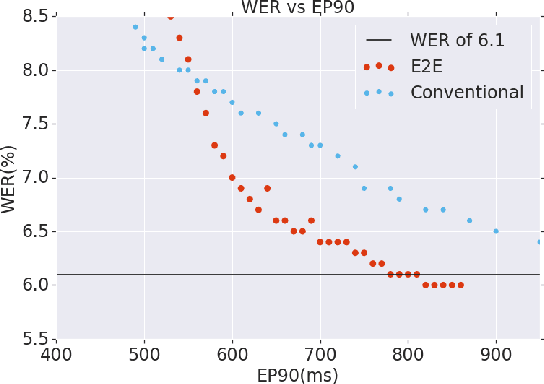
Thus far, end-to-end (E2E) models have not been shown to outperform state-of-the-art conventional models with respect to both quality, i.e., word error rate (WER), and latency, i.e., the time the hypothesis is finalized after the user stops speaking. In this paper, we develop a first-pass Recurrent Neural Network Transducer (RNN-T) model and a second-pass Listen, Attend, Spell (LAS) rescorer that surpasses a conventional model in both quality and latency. On the quality side, we incorporate a large number of utterances across varied domains to increase acoustic diversity and the vocabulary seen by the model. We also train with accented English speech to make the model more robust to different pronunciations. In addition, given the increased amount of training data, we explore a varied learning rate schedule. On the latency front, we explore using the end-of-sentence decision emitted by the RNN-T model to close the microphone, and also introduce various optimizations to improve the speed of LAS rescoring. Overall, we find that RNN-T+LAS offers a better WER and latency tradeoff compared to a conventional model. For example, for the same latency, RNN-T+LAS obtains a 8% relative improvement in WER, while being more than 400-times smaller in model size.
Scalability in Perception for Autonomous Driving: Waymo Open Dataset
Dec 18, 2019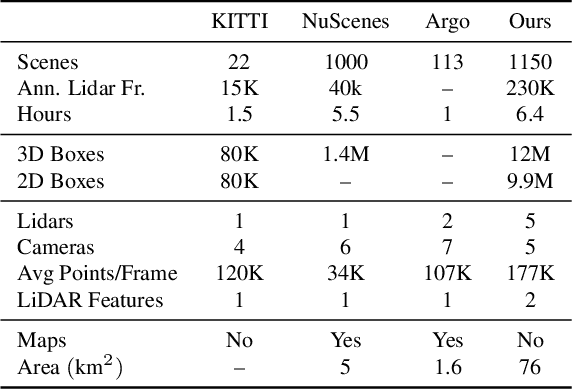
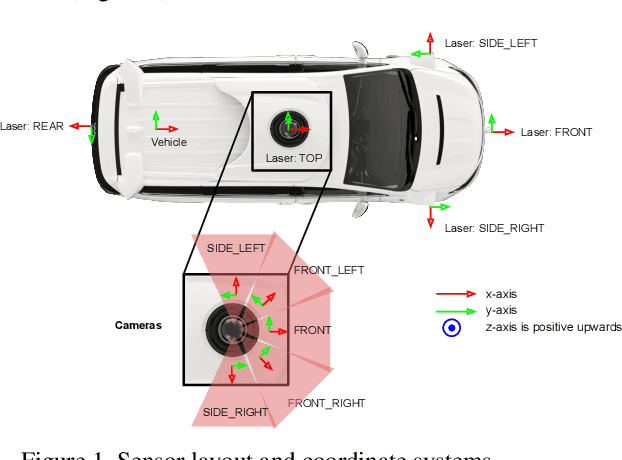

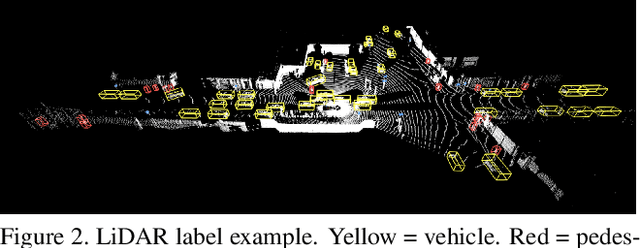
The research community has increasing interest in autonomous driving research, despite the resource intensity of obtaining representative real world data. Existing self-driving datasets are limited in the scale and variation of the environments they capture, even though generalization within and between operating regions is crucial to the overall viability of the technology. In an effort to help align the research community's contributions with real-world self-driving problems, we introduce a new large scale, high quality, diverse dataset. Our new dataset consists of 1150 scenes that each span 20 seconds, consisting of well synchronized and calibrated high quality LiDAR and camera data captured across a range of urban and suburban geographies. It is 15x more diverse than the largest camera+LiDAR dataset available based on our proposed diversity metric. We exhaustively annotated this data with 2D (camera image) and 3D (LiDAR) bounding boxes, with consistent identifiers across frames. Finally, we provide strong baselines for 2D as well as 3D detection and tracking tasks. We further study the effects of dataset size and generalization across geographies on 3D detection methods. Find data, code and more up-to-date information at http://www.waymo.com/open.
A comparison of end-to-end models for long-form speech recognition
Nov 06, 2019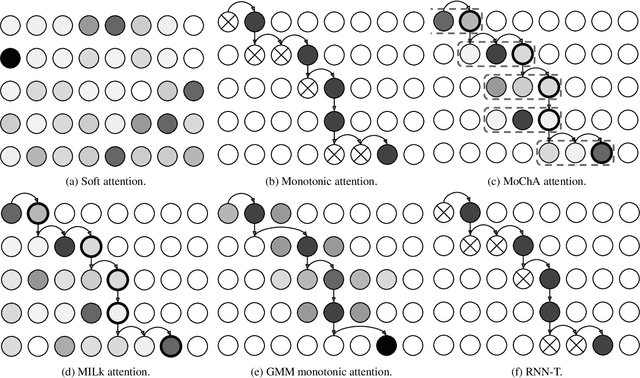

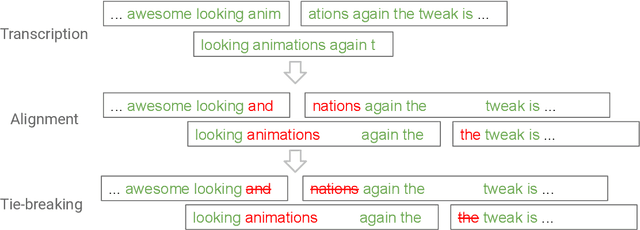
End-to-end automatic speech recognition (ASR) models, including both attention-based models and the recurrent neural network transducer (RNN-T), have shown superior performance compared to conventional systems. However, previous studies have focused primarily on short utterances that typically last for just a few seconds or, at most, a few tens of seconds. Whether such architectures are practical on long utterances that last from minutes to hours remains an open question. In this paper, we both investigate and improve the performance of end-to-end models on long-form transcription. We first present an empirical comparison of different end-to-end models on a real world long-form task and demonstrate that the RNN-T model is much more robust than attention-based systems in this regime. We next explore two improvements to attention-based systems that significantly improve its performance: restricting the attention to be monotonic, and applying a novel decoding algorithm that breaks long utterances into shorter overlapping segments. Combining these two improvements, we show that attention-based end-to-end models can be very competitive to RNN-T on long-form speech recognition.
Large-Scale Multilingual Speech Recognition with a Streaming End-to-End Model
Sep 11, 2019
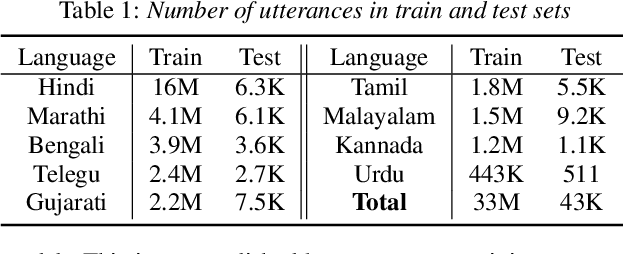
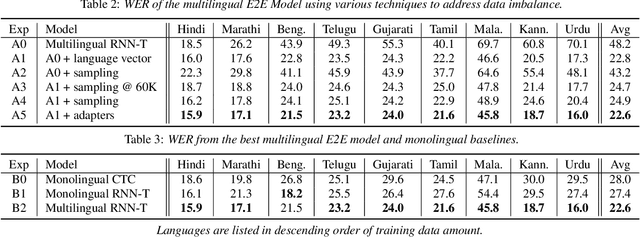
Multilingual end-to-end (E2E) models have shown great promise in expansion of automatic speech recognition (ASR) coverage of the world's languages. They have shown improvement over monolingual systems, and have simplified training and serving by eliminating language-specific acoustic, pronunciation, and language models. This work presents an E2E multilingual system which is equipped to operate in low-latency interactive applications, as well as handle a key challenge of real world data: the imbalance in training data across languages. Using nine Indic languages, we compare a variety of techniques, and find that a combination of conditioning on a language vector and training language-specific adapter layers produces the best model. The resulting E2E multilingual model achieves a lower word error rate (WER) than both monolingual E2E models (eight of nine languages) and monolingual conventional systems (all nine languages).
StarNet: Targeted Computation for Object Detection in Point Clouds
Aug 29, 2019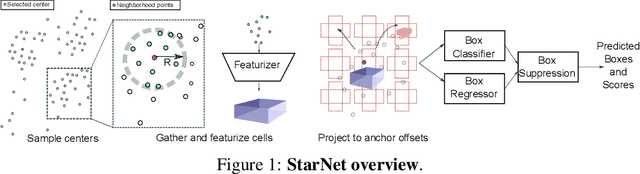
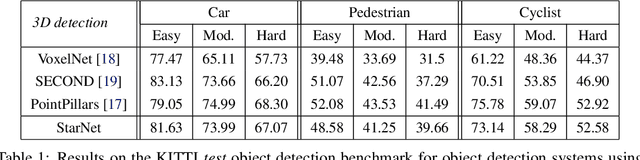
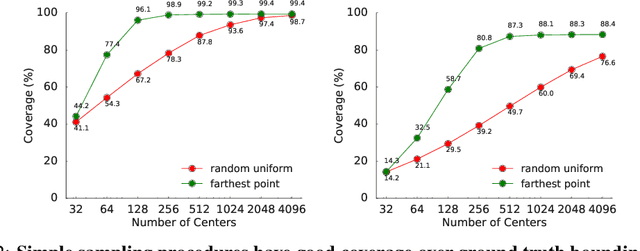
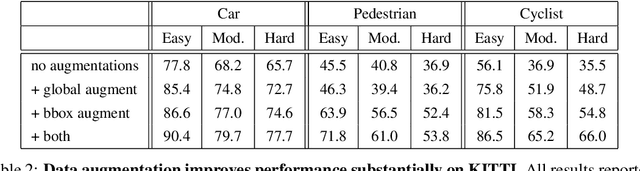
LiDAR sensor systems provide high resolution spatial information about the environment for self-driving cars. Therefore, detecting objects from point clouds derived from LiDAR represents a critical problem. Previous work on object detection from LiDAR has emphasized re-purposing convolutional approaches from traditional camera imagery. In this work, we present an object detection system designed specifically for point cloud data blending aspects of one-stage and two-stage systems. We observe that objects in point clouds are quite distinct from traditional camera images: objects are sparse and vary widely in location, but do not exhibit scale distortions observed in single camera perspective. These two observations suggest that simple and cheap data-driven object proposals to maximize spatial coverage or match the observed densities of point cloud data may suffice. This recognition paired with a local, non-convolutional, point-based network permits building an object detector for point clouds that may be trained only once, but adapted to different computational settings -- targeted to different predictive priorities or spatial regions. We demonstrate this flexibility and the targeted detection strategies on both the KITTI detection dataset as well as on the large-scale Waymo Open Dataset. Furthermore, we find that a single network is competitive with other point cloud detectors across a range of computational budgets, while being more flexible to adapt to contextual priorities.
Learning to Speak Fluently in a Foreign Language: Multilingual Speech Synthesis and Cross-Language Voice Cloning
Jul 24, 2019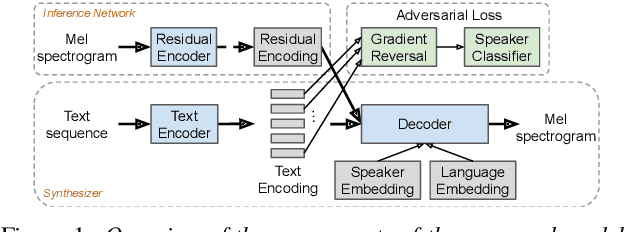
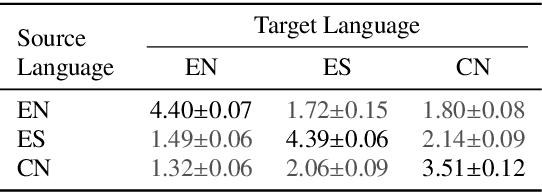
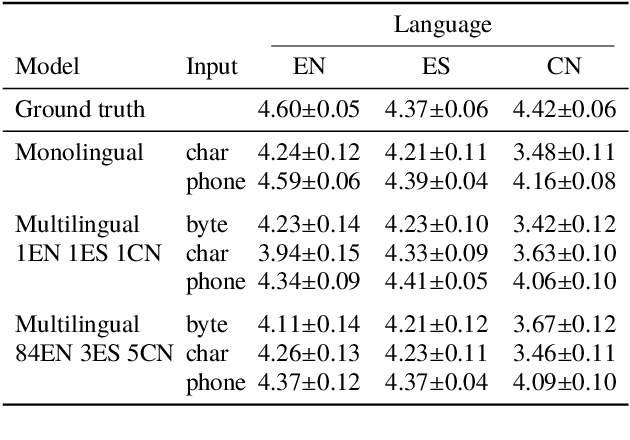
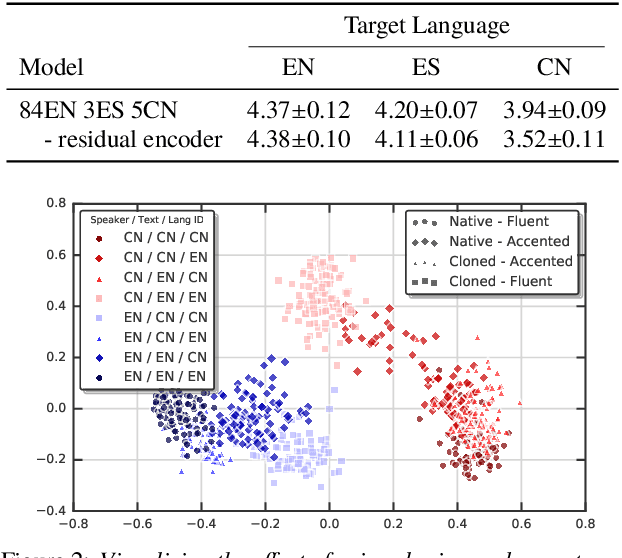
We present a multispeaker, multilingual text-to-speech (TTS) synthesis model based on Tacotron that is able to produce high quality speech in multiple languages. Moreover, the model is able to transfer voices across languages, e.g. synthesize fluent Spanish speech using an English speaker's voice, without training on any bilingual or parallel examples. Such transfer works across distantly related languages, e.g. English and Mandarin. Critical to achieving this result are: 1. using a phonemic input representation to encourage sharing of model capacity across languages, and 2. incorporating an adversarial loss term to encourage the model to disentangle its representation of speaker identity (which is perfectly correlated with language in the training data) from the speech content. Further scaling up the model by training on multiple speakers of each language, and incorporating an autoencoding input to help stabilize attention during training, results in a model which can be used to consistently synthesize intelligible speech for training speakers in all languages seen during training, and in native or foreign accents.
Massively Multilingual Neural Machine Translation in the Wild: Findings and Challenges
Jul 11, 2019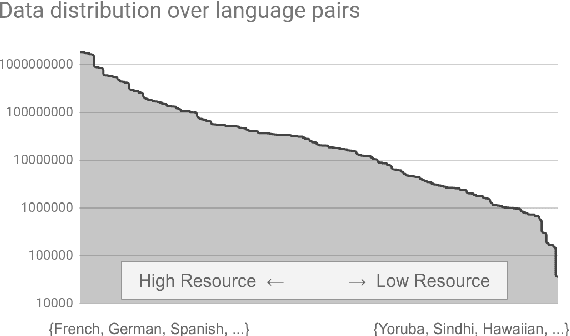
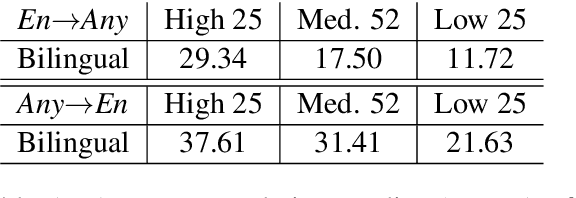
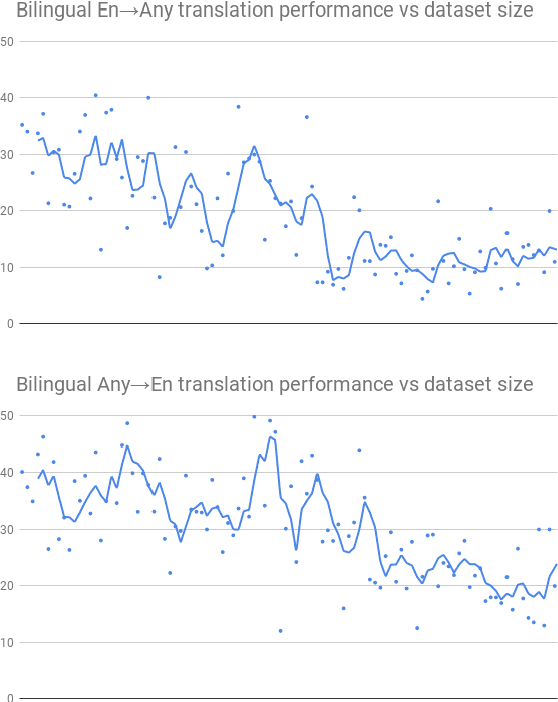
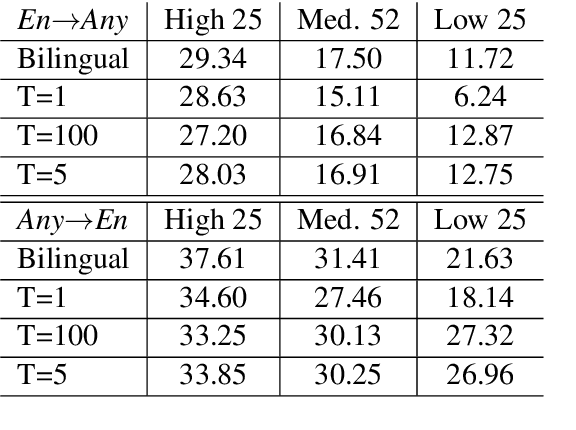
We introduce our efforts towards building a universal neural machine translation (NMT) system capable of translating between any language pair. We set a milestone towards this goal by building a single massively multilingual NMT model handling 103 languages trained on over 25 billion examples. Our system demonstrates effective transfer learning ability, significantly improving translation quality of low-resource languages, while keeping high-resource language translation quality on-par with competitive bilingual baselines. We provide in-depth analysis of various aspects of model building that are crucial to achieving quality and practicality in universal NMT. While we prototype a high-quality universal translation system, our extensive empirical analysis exposes issues that need to be further addressed, and we suggest directions for future research.
Gmail Smart Compose: Real-Time Assisted Writing
May 17, 2019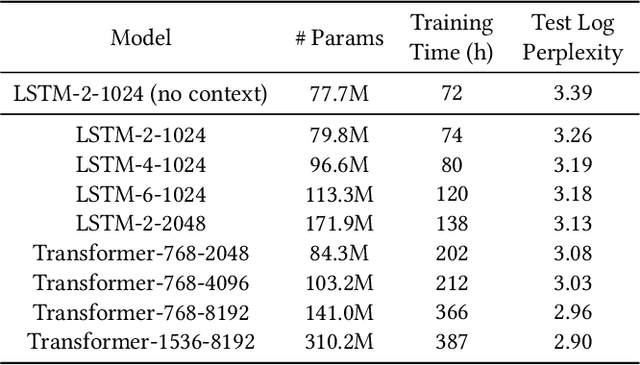
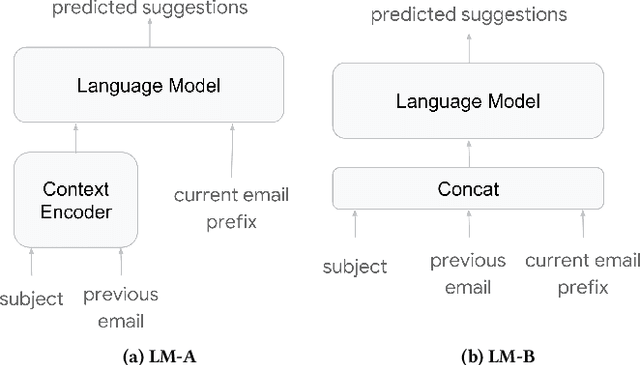
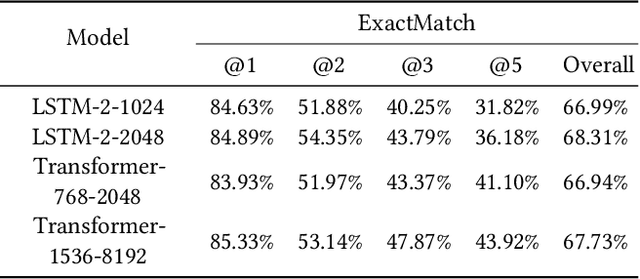
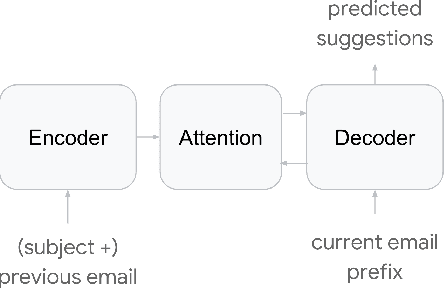
In this paper, we present Smart Compose, a novel system for generating interactive, real-time suggestions in Gmail that assists users in writing mails by reducing repetitive typing. In the design and deployment of such a large-scale and complicated system, we faced several challenges including model selection, performance evaluation, serving and other practical issues. At the core of Smart Compose is a large-scale neural language model. We leveraged state-of-the-art machine learning techniques for language model training which enabled high-quality suggestion prediction, and constructed novel serving infrastructure for high-throughput and real-time inference. Experimental results show the effectiveness of our proposed system design and deployment approach. This system is currently being served in Gmail.
Direct speech-to-speech translation with a sequence-to-sequence model
Apr 12, 2019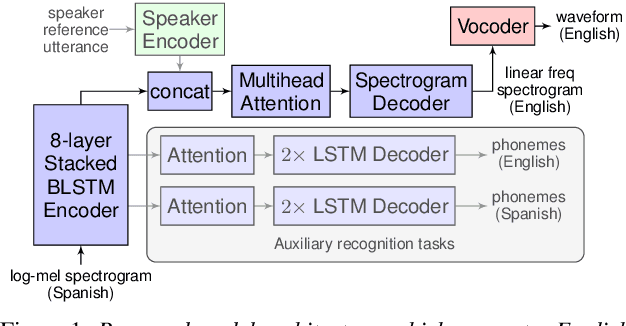
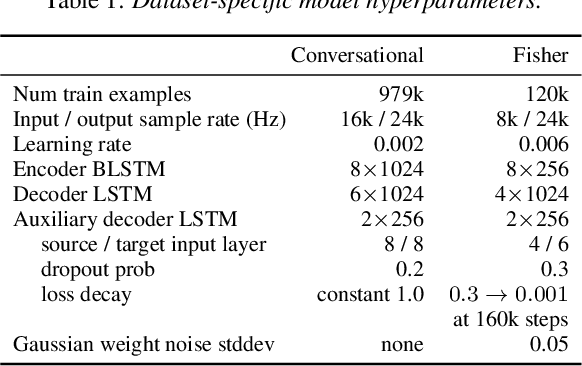
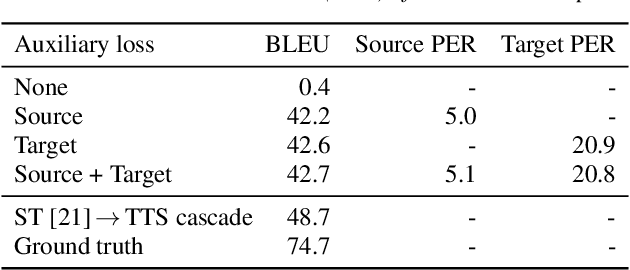
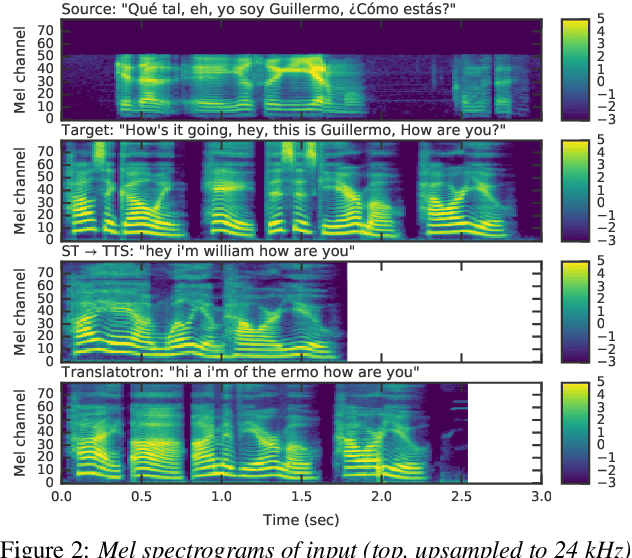
We present an attention-based sequence-to-sequence neural network which can directly translate speech from one language into speech in another language, without relying on an intermediate text representation. The network is trained end-to-end, learning to map speech spectrograms into target spectrograms in another language, corresponding to the translated content (in a different canonical voice). We further demonstrate the ability to synthesize translated speech using the voice of the source speaker. We conduct experiments on two Spanish-to-English speech translation datasets, and find that the proposed model slightly underperforms a baseline cascade of a direct speech-to-text translation model and a text-to-speech synthesis model, demonstrating the feasibility of the approach on this very challenging task.