 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRE-TRAC: REcursive TRAjectory Compression for Deep Search Agents
Feb 02, 2026LLM-based deep research agents are largely built on the ReAct framework. This linear design makes it difficult to revisit earlier states, branch into alternative search directions, or maintain global awareness under long contexts, often leading to local optima, redundant exploration, and inefficient search. We propose Re-TRAC, an agentic framework that performs cross-trajectory exploration by generating a structured state representation after each trajectory to summarize evidence, uncertainties, failures, and future plans, and conditioning subsequent trajectories on this state representation. This enables iterative reflection and globally informed planning, reframing research as a progressive process. Empirical results show that Re-TRAC consistently outperforms ReAct by 15-20% on BrowseComp with frontier LLMs. For smaller models, we introduce Re-TRAC-aware supervised fine-tuning, achieving state-of-the-art performance at comparable scales. Notably, Re-TRAC shows a monotonic reduction in tool calls and token usage across rounds, indicating progressively targeted exploration driven by cross-trajectory reflection rather than redundant search.
ProImage-Bench: Rubric-Based Evaluation for Professional Image Generation
Dec 13, 2025We study professional image generation, where a model must synthesize information-dense, scientifically precise illustrations from technical descriptions rather than merely produce visually plausible pictures. To quantify the progress, we introduce ProImage-Bench, a rubric-based benchmark that targets biology schematics, engineering/patent drawings, and general scientific diagrams. For 654 figures collected from real textbooks and technical reports, we construct detailed image instructions and a hierarchy of rubrics that decompose correctness into 6,076 criteria and 44,131 binary checks. Rubrics are derived from surrounding text and reference figures using large multimodal models, and are evaluated by an automated LMM-based judge with a principled penalty scheme that aggregates sub-question outcomes into interpretable criterion scores. We benchmark several representative text-to-image models on ProImage-Bench and find that, despite strong open-domain performance, the best base model reaches only 0.791 rubric accuracy and 0.553 criterion score overall, revealing substantial gaps in fine-grained scientific fidelity. Finally, we show that the same rubrics provide actionable supervision: feeding failed checks back into an editing model for iterative refinement boosts a strong generator from 0.653 to 0.865 in rubric accuracy and from 0.388 to 0.697 in criterion score. ProImage-Bench thus offers both a rigorous diagnostic for professional image generation and a scalable signal for improving specification-faithful scientific illustrations.
Computer-Use Agents as Judges for Generative User Interface
Nov 19, 2025Computer-Use Agents (CUA) are becoming increasingly capable of autonomously operating digital environments through Graphical User Interfaces (GUI). Yet, most GUI remain designed primarily for humans--prioritizing aesthetics and usability--forcing agents to adopt human-oriented behaviors that are unnecessary for efficient task execution. At the same time, rapid advances in coding-oriented language models (Coder) have transformed automatic GUI design. This raises a fundamental question: Can CUA as judges to assist Coder for automatic GUI design? To investigate, we introduce AUI-Gym, a benchmark for Automatic GUI development spanning 52 applications across diverse domains. Using language models, we synthesize 1560 tasks that simulate real-world scenarios. To ensure task reliability, we further develop a verifier that programmatically checks whether each task is executable within its environment. Building on this, we propose a Coder-CUA in Collaboration framework: the Coder acts as Designer, generating and revising websites, while the CUA serves as Judge, evaluating functionality and refining designs. Success is measured not by visual appearance, but by task solvability and CUA navigation success rate. To turn CUA feedback into usable guidance, we design a CUA Dashboard that compresses multi-step navigation histories into concise visual summaries, offering interpretable guidance for iterative redesign. By positioning agents as both designers and judges, our framework shifts interface design toward agent-native efficiency and reliability. Our work takes a step toward shifting agents from passive use toward active participation in digital environments. Our code and dataset are available at https://github.com/showlab/AUI.
SHANKS: Simultaneous Hearing and Thinking for Spoken Language Models
Oct 08, 2025



Current large language models (LLMs) and spoken language models (SLMs) begin thinking and taking actions only after the user has finished their turn. This prevents the model from interacting during the user's turn and can lead to high response latency while it waits to think. Consequently, thinking after receiving the full input is not suitable for speech-to-speech interaction, where real-time, low-latency exchange is important. We address this by noting that humans naturally "think while listening." In this paper, we propose SHANKS, a general inference framework that enables SLMs to generate unspoken chain-of-thought reasoning while listening to the user input. SHANKS streams the input speech in fixed-duration chunks and, as soon as a chunk is received, generates unspoken reasoning based on all previous speech and reasoning, while the user continues speaking. SHANKS uses this unspoken reasoning to decide whether to interrupt the user and to make tool calls to complete the task. We demonstrate that SHANKS enhances real-time user-SLM interaction in two scenarios: (1) when the user is presenting a step-by-step solution to a math problem, SHANKS can listen, reason, and interrupt when the user makes a mistake, achieving 37.1% higher interruption accuracy than a baseline that interrupts without thinking; and (2) in a tool-augmented dialogue, SHANKS can complete 56.9% of the tool calls before the user finishes their turn. Overall, SHANKS moves toward models that keep thinking throughout the conversation, not only after a turn ends. Animated illustrations of Shanks can be found at https://d223302.github.io/SHANKS/
ViCrit: A Verifiable Reinforcement Learning Proxy Task for Visual Perception in VLMs
Jun 11, 2025Reinforcement learning (RL) has shown great effectiveness for fine-tuning large language models (LLMs) using tasks that are challenging yet easily verifiable, such as math reasoning or code generation. However, extending this success to visual perception in vision-language models (VLMs) has been impeded by the scarcity of vision-centric tasks that are simultaneously challenging and unambiguously verifiable. To this end, we introduce ViCrit (Visual Caption Hallucination Critic), an RL proxy task that trains VLMs to localize a subtle, synthetic visual hallucination injected into paragraphs of human-written image captions. Starting from a 200-word captions, we inject a single, subtle visual description error-altering a few words on objects, attributes, counts, or spatial relations-and task the model to pinpoint the corrupted span given the image and the modified caption. This formulation preserves the full perceptual difficulty while providing a binary, exact-match reward that is easy to compute and unambiguous. Models trained with the ViCrit Task exhibit substantial gains across a variety of VL benchmarks. Crucially, the improvements transfer beyond natural-image training data to abstract image reasoning and visual math, showing promises of learning to perceive rather than barely memorizing seen objects. To facilitate evaluation, we further introduce ViCrit-Bench, a category-balanced diagnostic benchmark that systematically probes perception errors across diverse image domains and error types. Together, our results demonstrate that fine-grained hallucination criticism is an effective and generalizable objective for enhancing visual perception in VLMs.
What makes Reasoning Models Different? Follow the Reasoning Leader for Efficient Decoding
Jun 08, 2025Large reasoning models (LRMs) achieve strong reasoning performance by emitting long chains of thought. Yet, these verbose traces slow down inference and often drift into unnecessary detail, known as the overthinking phenomenon. To better understand LRMs' behavior, we systematically analyze the token-level misalignment between reasoning and non-reasoning models. While it is expected that their primary difference lies in the stylistic "thinking cues", LRMs uniquely exhibit two pivotal, previously under-explored phenomena: a Global Misalignment Rebound, where their divergence from non-reasoning models persists or even grows as response length increases, and more critically, a Local Misalignment Diminish, where the misalignment concentrates at the "thinking cues" each sentence starts with but rapidly declines in the remaining of the sentence. Motivated by the Local Misalignment Diminish, we propose FoReaL-Decoding, a collaborative fast-slow thinking decoding method for cost-quality trade-off. In FoReaL-Decoding, a Leading model leads the first few tokens for each sentence, and then a weaker draft model completes the following tokens to the end of each sentence. FoReaL-Decoding adopts a stochastic gate to smoothly interpolate between the small and the large model. On four popular math-reasoning benchmarks (AIME24, GPQA-Diamond, MATH500, AMC23), FoReaL-Decoding reduces theoretical FLOPs by 30 to 50% and trims CoT length by up to 40%, while preserving 86 to 100% of model performance. These results establish FoReaL-Decoding as a simple, plug-and-play route to controllable cost-quality trade-offs in reasoning-centric tasks.
Audio-Aware Large Language Models as Judges for Speaking Styles
Jun 06, 2025Audio-aware large language models (ALLMs) can understand the textual and non-textual information in the audio input. In this paper, we explore using ALLMs as an automatic judge to assess the speaking styles of speeches. We use ALLM judges to evaluate the speeches generated by SLMs on two tasks: voice style instruction following and role-playing. The speaking style we consider includes emotion, volume, speaking pace, word emphasis, pitch control, and non-verbal elements. We use four spoken language models (SLMs) to complete the two tasks and use humans and ALLMs to judge the SLMs' responses. We compare two ALLM judges, GPT-4o-audio and Gemini-2.5-pro, with human evaluation results and show that the agreement between Gemini and human judges is comparable to the agreement between human evaluators. These promising results show that ALLMs can be used as a judge to evaluate SLMs. Our results also reveal that current SLMs, even GPT-4o-audio, still have room for improvement in controlling the speaking style and generating natural dialogues.
Are Unified Vision-Language Models Necessary: Generalization Across Understanding and Generation
May 29, 2025Recent advancements in unified vision-language models (VLMs), which integrate both visual understanding and generation capabilities, have attracted significant attention. The underlying hypothesis is that a unified architecture with mixed training on both understanding and generation tasks can enable mutual enhancement between understanding and generation. However, this hypothesis remains underexplored in prior works on unified VLMs. To address this gap, this paper systematically investigates the generalization across understanding and generation tasks in unified VLMs. Specifically, we design a dataset closely aligned with real-world scenarios to facilitate extensive experiments and quantitative evaluations. We evaluate multiple unified VLM architectures to validate our findings. Our key findings are as follows. First, unified VLMs trained with mixed data exhibit mutual benefits in understanding and generation tasks across various architectures, and this mutual benefits can scale up with increased data. Second, better alignment between multimodal input and output spaces will lead to better generalization. Third, the knowledge acquired during generation tasks can transfer to understanding tasks, and this cross-task generalization occurs within the base language model, beyond modality adapters. Our findings underscore the critical necessity of unifying understanding and generation in VLMs, offering valuable insights for the design and optimization of unified VLMs.
Point-RFT: Improving Multimodal Reasoning with Visually Grounded Reinforcement Finetuning
May 26, 2025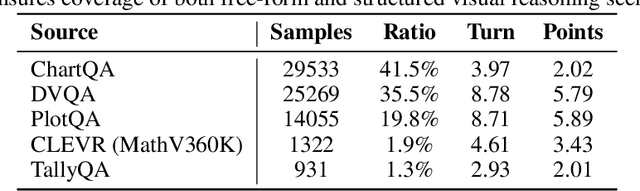
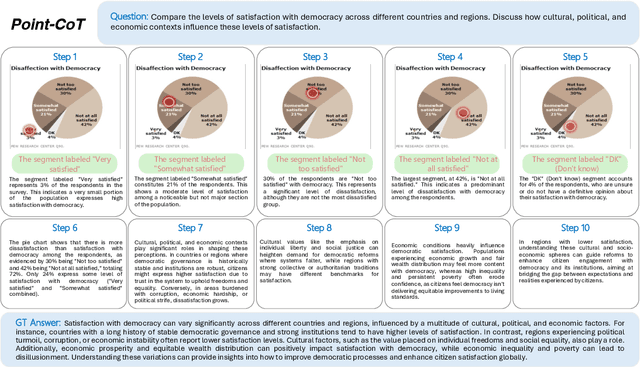

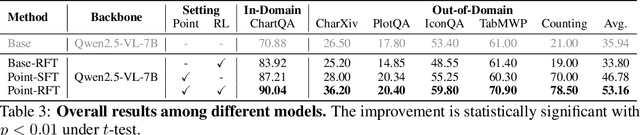
Recent advances in large language models have significantly improved textual reasoning through the effective use of Chain-of-Thought (CoT) and reinforcement learning. However, extending these successes to vision-language tasks remains challenging due to inherent limitations in text-only CoT, such as visual hallucinations and insufficient multimodal integration. In this paper, we introduce Point-RFT, a multimodal reasoning framework explicitly designed to leverage visually grounded CoT reasoning for visual document understanding. Our approach consists of two stages: First, we conduct format finetuning using a curated dataset of 71K diverse visual reasoning problems, each annotated with detailed, step-by-step rationales explicitly grounded to corresponding visual elements. Second, we employ reinforcement finetuning targeting visual document understanding. On ChartQA, our approach improves accuracy from 70.88% (format-finetuned baseline) to 90.04%, surpassing the 83.92% accuracy achieved by reinforcement finetuning relying solely on text-based CoT. The result shows that our grounded CoT is more effective for multimodal reasoning compared with the text-only CoT. Moreover, Point-RFT exhibits superior generalization capability across several out-of-domain visual document reasoning benchmarks, including CharXiv, PlotQA, IconQA, TabMWP, etc., and highlights its potential in complex real-world scenarios.
OpenThinkIMG: Learning to Think with Images via Visual Tool Reinforcement Learning
May 13, 2025



While humans can flexibly leverage interactive visual cognition for complex problem-solving, enabling Large Vision-Language Models (LVLMs) to learn similarly adaptive behaviors with visual tools remains challenging. A significant hurdle is the current lack of standardized infrastructure, which hinders integrating diverse tools, generating rich interaction data, and training robust agents effectively. To address these gaps, we introduce OpenThinkIMG, the first open-source, comprehensive end-to-end framework for tool-augmented LVLMs. It features standardized vision tool interfaces, scalable trajectory generation for policy initialization, and a flexible training environment. Furthermore, considering supervised fine-tuning (SFT) on static demonstrations offers limited policy generalization for dynamic tool invocation, we propose a novel reinforcement learning (RL) framework V-ToolRL to train LVLMs to learn adaptive policies for invoking external vision tools. V-ToolRL enables LVLMs to autonomously discover optimal tool-usage strategies by directly optimizing for task success using feedback from tool interactions. We empirically validate V-ToolRL on challenging chart reasoning tasks. Our RL-trained agent, built upon a Qwen2-VL-2B, significantly outperforms its SFT-initialized counterpart (+28.83 points) and surpasses established supervised tool-learning baselines like Taco and CogCom by an average of +12.7 points. Notably, it also surpasses prominent closed-source models like GPT-4.1 by +8.68 accuracy points. We hope OpenThinkIMG can serve as a foundational framework for advancing dynamic, tool-augmented visual reasoning, helping the community develop AI agents that can genuinely "think with images".