 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised High-Fidelity Clothing Model Generation
Dec 14, 2021
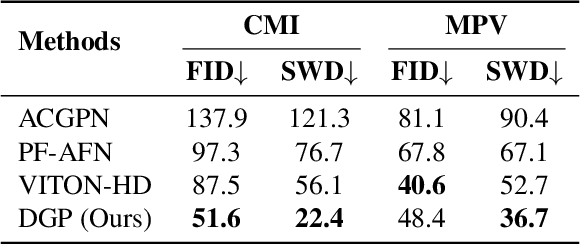
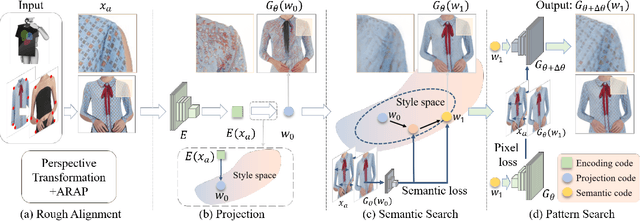

The development of online economics arouses the demand of generating images of models on product clothes, to display new clothes and promote sales. However, the expensive proprietary model images challenge the existing image virtual try-on methods in this scenario, as most of them need to be trained on considerable amounts of model images accompanied with paired clothes images. In this paper, we propose a cheap yet scalable weakly-supervised method called Deep Generative Projection (DGP) to address this specific scenario. Lying in the heart of the proposed method is to imitate the process of human predicting the wearing effect, which is an unsupervised imagination based on life experience rather than computation rules learned from supervisions. Here a pretrained StyleGAN is used to capture the practical experience of wearing. Experiments show that projecting the rough alignment of clothing and body onto the StyleGAN space can yield photo-realistic wearing results. Experiments on real scene proprietary model images demonstrate the superiority of DGP over several state-of-the-art supervised methods when generating clothing model images.
MViT: Mask Vision Transformer for Facial Expression Recognition in the wild
Jun 08, 2021


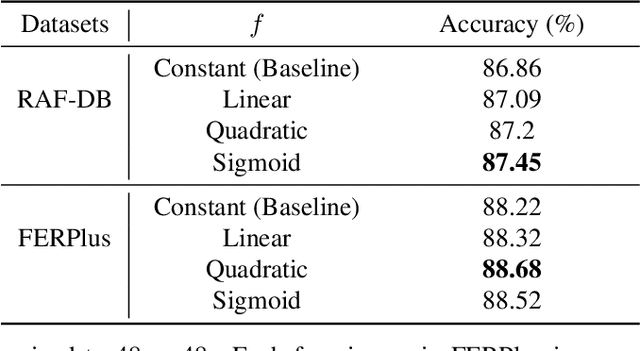
Facial Expression Recognition (FER) in the wild is an extremely challenging task in computer vision due to variant backgrounds, low-quality facial images, and the subjectiveness of annotators. These uncertainties make it difficult for neural networks to learn robust features on limited-scale datasets. Moreover, the networks can be easily distributed by the above factors and perform incorrect decisions. Recently, vision transformer (ViT) and data-efficient image transformers (DeiT) present their significant performance in traditional classification tasks. The self-attention mechanism makes transformers obtain a global receptive field in the first layer which dramatically enhances the feature extraction capability. In this work, we first propose a novel pure transformer-based mask vision transformer (MViT) for FER in the wild, which consists of two modules: a transformer-based mask generation network (MGN) to generate a mask that can filter out complex backgrounds and occlusion of face images, and a dynamic relabeling module to rectify incorrect labels in FER datasets in the wild. Extensive experimental results demonstrate that our MViT outperforms state-of-the-art methods on RAF-DB with 88.62%, FERPlus with 89.22%, and AffectNet-7 with 64.57%, respectively, and achieves a comparable result on AffectNet-8 with 61.40%.
Low-Rank Subspaces in GANs
Jun 08, 2021
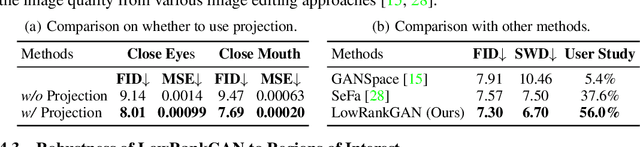


The latent space of a Generative Adversarial Network (GAN) has been shown to encode rich semantics within some subspaces. To identify these subspaces, researchers typically analyze the statistical information from a collection of synthesized data, and the identified subspaces tend to control image attributes globally (i.e., manipulating an attribute causes the change of an entire image). By contrast, this work introduces low-rank subspaces that enable more precise control of GAN generation. Concretely, given an arbitrary image and a region of interest (e.g., eyes of face images), we manage to relate the latent space to the image region with the Jacobian matrix and then use low-rank factorization to discover steerable latent subspaces. There are three distinguishable strengths of our approach that can be aptly called LowRankGAN. First, compared to analytic algorithms in prior work, our low-rank factorization of Jacobians is able to find the low-dimensional representation of attribute manifold, making image editing more precise and controllable. Second, low-rank factorization naturally yields a null space of attributes such that moving the latent code within it only affects the outer region of interest. Therefore, local image editing can be simply achieved by projecting an attribute vector into the null space without relying on a spatial mask as existing methods do. Third, our method can robustly work with a local region from one image for analysis yet well generalize to other images, making it much easy to use in practice. Extensive experiments on state-of-the-art GAN models (including StyleGAN2 and BigGAN) trained on various datasets demonstrate the effectiveness of our LowRankGAN.
BoundarySqueeze: Image Segmentation as Boundary Squeezing
May 25, 2021
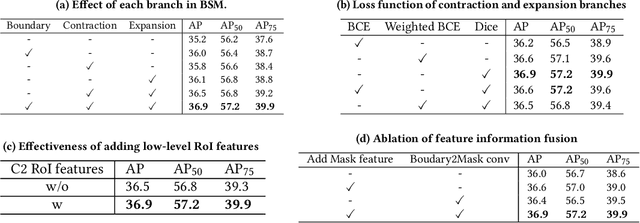

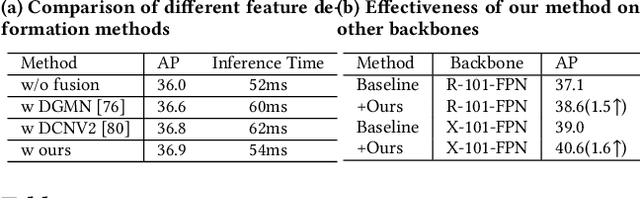
We propose a novel method for fine-grained high-quality image segmentation of both objects and scenes. Inspired by dilation and erosion from morphological image processing techniques, we treat the pixel level segmentation problems as squeezing object boundary. From this perspective, we propose \textbf{Boundary Squeeze} module: a novel and efficient module that squeezes the object boundary from both inner and outer directions which leads to precise mask representation. To generate such squeezed representation, we propose a new bidirectionally flow-based warping process and design specific loss signals to supervise the learning process. Boundary Squeeze Module can be easily applied to both instance and semantic segmentation tasks as a plug-and-play module by building on top of existing models. We show that our simple yet effective design can lead to high qualitative results on several different datasets and we also provide several different metrics on boundary to prove the effectiveness over previous work. Moreover, the proposed module is light-weighted and thus has potential for practical usage. Our method yields large gains on COCO, Cityscapes, for both instance and semantic segmentation and outperforms previous state-of-the-art PointRend in both accuracy and speed under the same setting. Code and model will be available.
On Noise Injection in Generative Adversarial Networks
Jun 11, 2020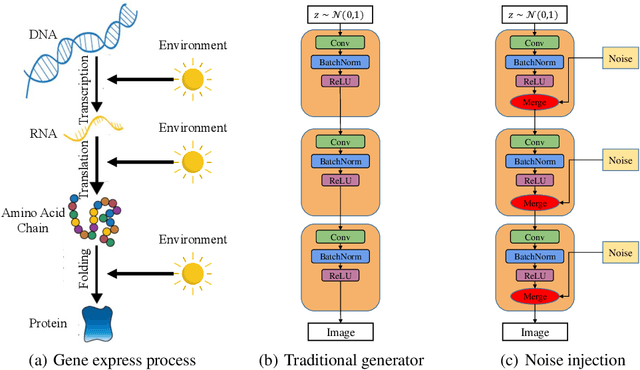
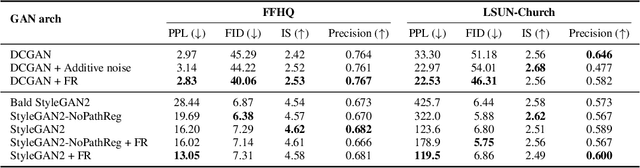
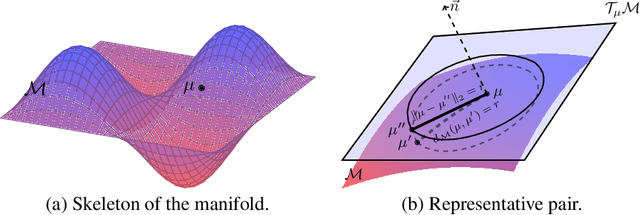
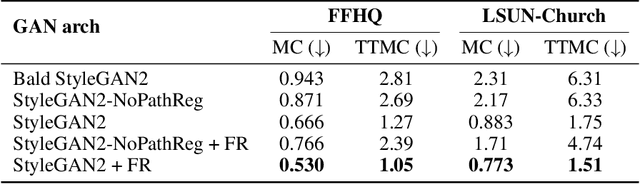
Noise injection has been proved to be one of the key technique advances in generating high-fidelity images. Despite its successful usage in GANs, the mechanism of its validity is still unclear. In this paper, we propose a geometric framework to theoretically analyze the role of noise injection in GANs. Based on Riemannian geometry, we successfully model the noise injection framework as fuzzy equivalence on the geodesic normal coordinates. Guided by our theories, we find that the existing method is incomplete and a new strategy for noise injection is devised. Experiments on image generation and GAN inversion demonstrate the superiority of our method.
Memory-Augmented Relation Network for Few-Shot Learning
May 13, 2020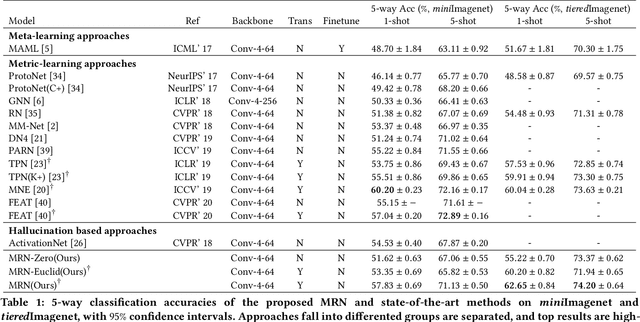
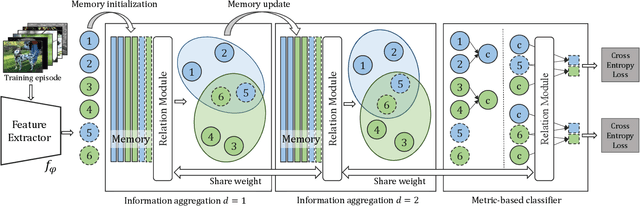
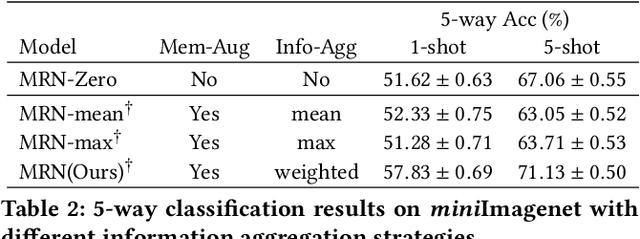

Metric-based few-shot learning methods concentrate on learning transferable feature embedding that generalizes well from seen categories to unseen categories under the supervision of limited number of labelled instances. However, most of them treat each individual instance in the working context separately without considering its relationships with the others. In this work, we investigate a new metric-learning method, Memory-Augmented Relation Network (MRN), to explicitly exploit these relationships. In particular, for an instance, we choose the samples that are visually similar from the working context, and perform weighted information propagation to attentively aggregate helpful information from the chosen ones to enhance its representation. In MRN, we also formulate the distance metric as a learnable relation module which learns to compare for similarity measurement, and augment the working context with memory slots, both contributing to its generality. We empirically demonstrate that MRN yields significant improvement over its ancestor and achieves competitive or even better performance when compared with other few-shot learning approaches on the two major benchmark datasets, i.e. miniImagenet and tieredImagenet.
Parsing-based View-aware Embedding Network for Vehicle Re-Identification
Apr 10, 2020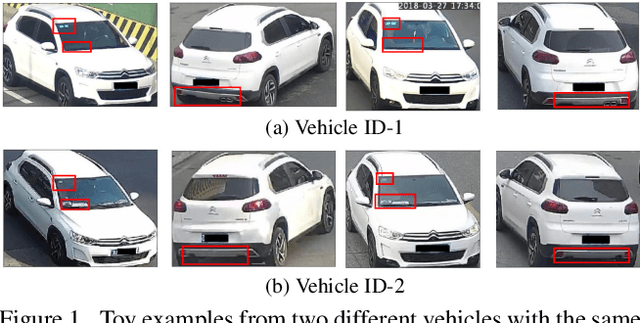
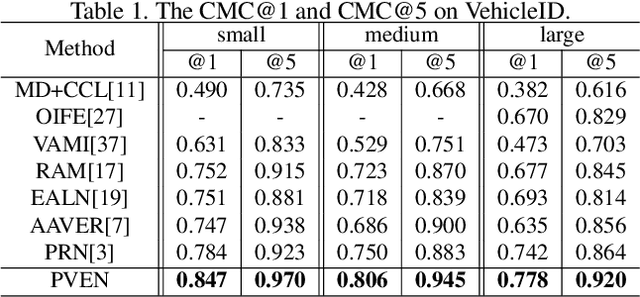
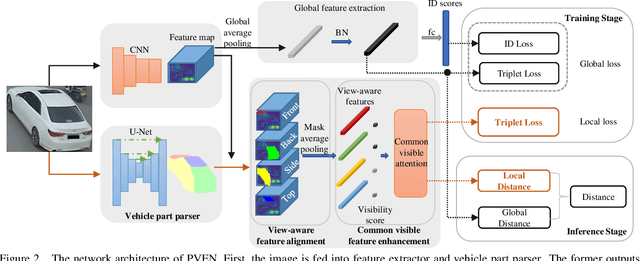
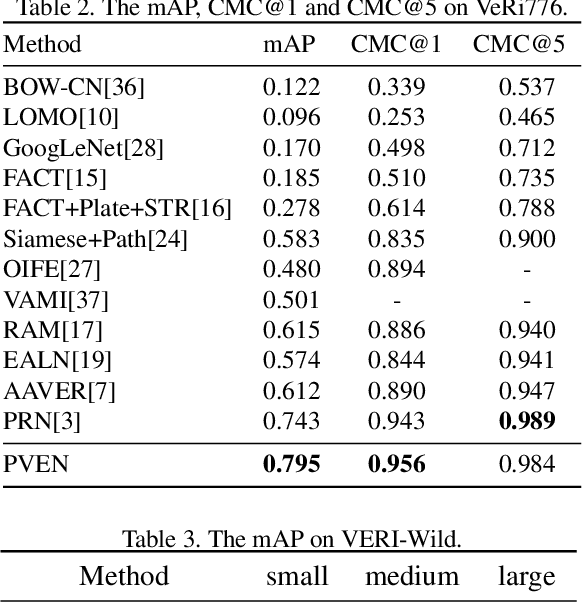
Vehicle Re-Identification is to find images of the same vehicle from various views in the cross-camera scenario. The main challenges of this task are the large intra-instance distance caused by different views and the subtle inter-instance discrepancy caused by similar vehicles. In this paper, we propose a parsing-based view-aware embedding network (PVEN) to achieve the view-aware feature alignment and enhancement for vehicle ReID. First, we introduce a parsing network to parse a vehicle into four different views, and then align the features by mask average pooling. Such alignment provides a fine-grained representation of the vehicle. Second, in order to enhance the view-aware features, we design a common-visible attention to focus on the common visible views, which not only shortens the distance among intra-instances, but also enlarges the discrepancy of inter-instances. The PVEN helps capture the stable discriminative information of vehicle under different views. The experiments conducted on three datasets show that our model outperforms state-of-the-art methods by a large margin.
ContourNet: Taking a Further Step toward Accurate Arbitrary-shaped Scene Text Detection
Apr 10, 2020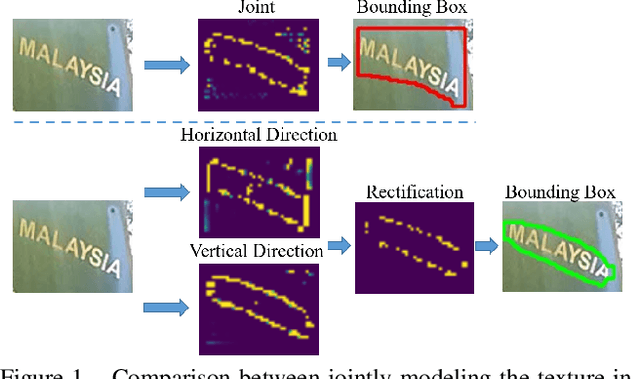
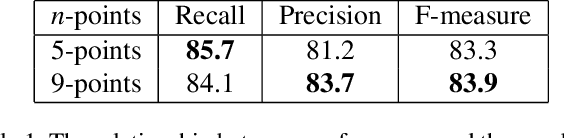
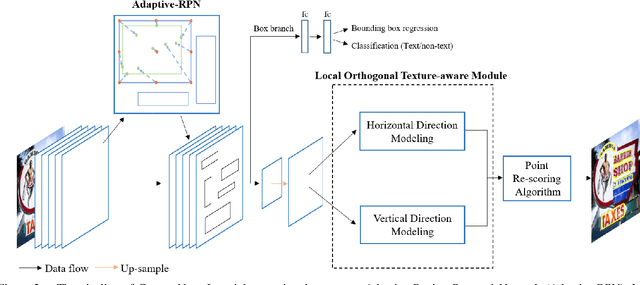
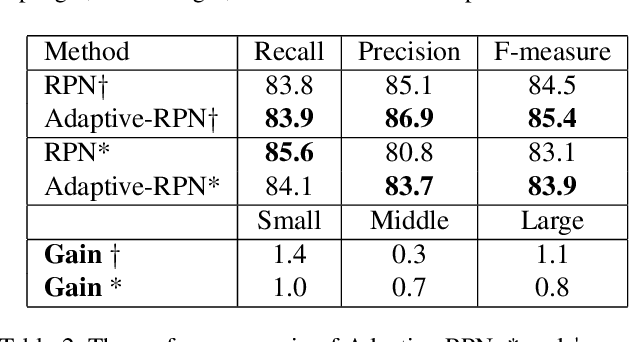
Scene text detection has witnessed rapid development in recent years. However, there still exists two main challenges: 1) many methods suffer from false positives in their text representations; 2) the large scale variance of scene texts makes it hard for network to learn samples. In this paper, we propose the ContourNet, which effectively handles these two problems taking a further step toward accurate arbitrary-shaped text detection. At first, a scale-insensitive Adaptive Region Proposal Network (Adaptive-RPN) is proposed to generate text proposals by only focusing on the Intersection over Union (IoU) values between predicted and ground-truth bounding boxes. Then a novel Local Orthogonal Texture-aware Module (LOTM) models the local texture information of proposal features in two orthogonal directions and represents text region with a set of contour points. Considering that the strong unidirectional or weakly orthogonal activation is usually caused by the monotonous texture characteristic of false-positive patterns (e.g. streaks.), our method effectively suppresses these false positives by only outputting predictions with high response value in both orthogonal directions. This gives more accurate description of text regions. Extensive experiments on three challenging datasets (Total-Text, CTW1500 and ICDAR2015) verify that our method achieves the state-of-the-art performance. Code is available at https://github.com/wangyuxin87/ContourNet.
Object Relational Graph with Teacher-Recommended Learning for Video Captioning
Feb 26, 2020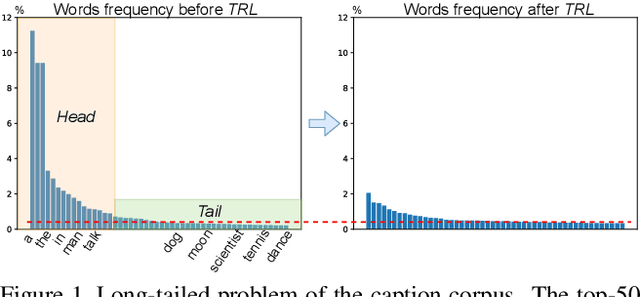

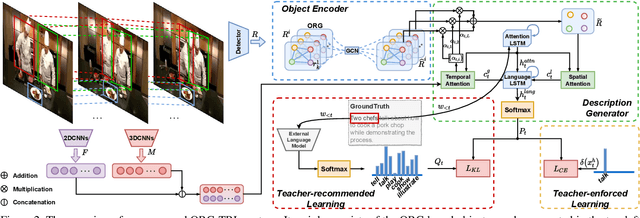
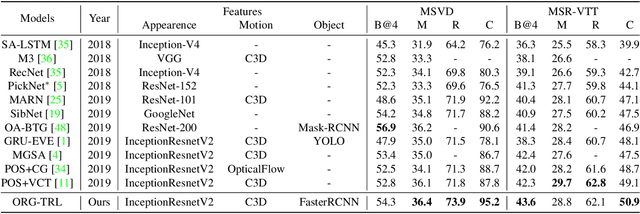
Taking full advantage of the information from both vision and language is critical for the video captioning task. Existing models lack adequate visual representation due to the neglect of interaction between object, and sufficient training for content-related words due to long-tailed problems. In this paper, we propose a complete video captioning system including both a novel model and an effective training strategy. Specifically, we propose an object relational graph (ORG) based encoder, which captures more detailed interaction features to enrich visual representation. Meanwhile, we design a teacher-recommended learning (TRL) method to make full use of the successful external language model (ELM) to integrate the abundant linguistic knowledge into the caption model. The ELM generates more semantically similar word proposals which extend the ground-truth words used for training to deal with the long-tailed problem. Experimental evaluations on three benchmarks: MSVD, MSR-VTT and VATEX show the proposed ORG-TRL system achieves state-of-the-art performance. Extensive ablation studies and visualizations illustrate the effectiveness of our system.
Convolutional Dictionary Pair Learning Network for Image Representation Learning
Jan 15, 2020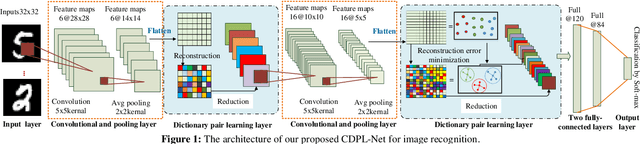
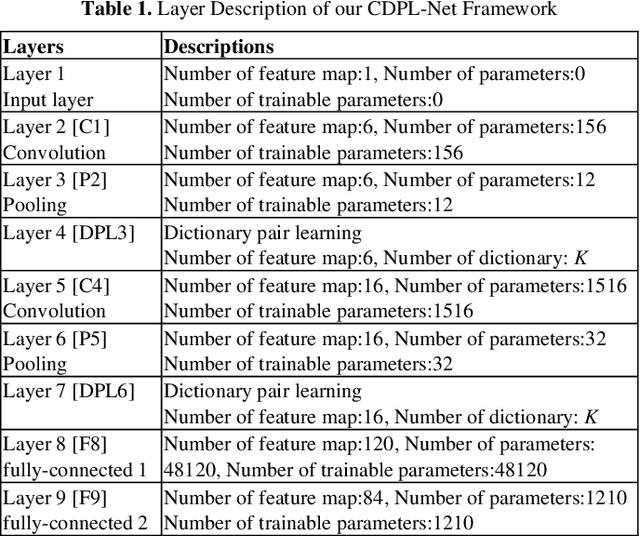
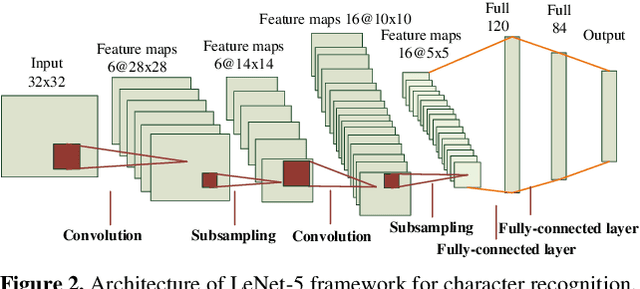
Both the Dictionary Learning (DL) and Convolutional Neural Networks (CNN) are powerful image representation learning systems based on different mechanisms and principles, however whether we can seamlessly integrate them to improve the per-formance is noteworthy exploring. To address this issue, we propose a novel generalized end-to-end representation learning architecture, dubbed Convolutional Dictionary Pair Learning Network (CDPL-Net) in this paper, which integrates the learning schemes of the CNN and dictionary pair learning into a unified framework. Generally, the architecture of CDPL-Net includes two convolutional/pooling layers and two dictionary pair learn-ing (DPL) layers in the representation learning module. Besides, it uses two fully-connected layers as the multi-layer perception layer in the nonlinear classification module. In particular, the DPL layer can jointly formulate the discriminative synthesis and analysis representations driven by minimizing the batch based reconstruction error over the flatted feature maps from the convolution/pooling layer. Moreover, DPL layer uses l1-norm on the analysis dictionary so that sparse representation can be delivered, and the embedding process will also be robust to noise. To speed up the training process of DPL layer, the efficient stochastic gradient descent is used. Extensive simulations on real databases show that our CDPL-Net can deliver enhanced performance over other state-of-the-art methods.