 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Step Diffusion via Score identity Distillation
May 19, 2025Diffusion distillation has emerged as a promising strategy for accelerating text-to-image (T2I) diffusion models by distilling a pretrained score network into a one- or few-step generator. While existing methods have made notable progress, they often rely on real or teacher-synthesized images to perform well when distilling high-resolution T2I diffusion models such as Stable Diffusion XL (SDXL), and their use of classifier-free guidance (CFG) introduces a persistent trade-off between text-image alignment and generation diversity. We address these challenges by optimizing Score identity Distillation (SiD) -- a data-free, one-step distillation framework -- for few-step generation. Backed by theoretical analysis that justifies matching a uniform mixture of outputs from all generation steps to the data distribution, our few-step distillation algorithm avoids step-specific networks and integrates seamlessly into existing pipelines, achieving state-of-the-art performance on SDXL at 1024x1024 resolution. To mitigate the alignment-diversity trade-off when real text-image pairs are available, we introduce a Diffusion GAN-based adversarial loss applied to the uniform mixture and propose two new guidance strategies: Zero-CFG, which disables CFG in the teacher and removes text conditioning in the fake score network, and Anti-CFG, which applies negative CFG in the fake score network. This flexible setup improves diversity without sacrificing alignment. Comprehensive experiments on SD1.5 and SDXL demonstrate state-of-the-art performance in both one-step and few-step generation settings, along with robustness to the absence of real images. Our efficient PyTorch implementation, along with the resulting one- and few-step distilled generators, will be released publicly as a separate branch at https://github.com/mingyuanzhou/SiD-LSG.
Restoration Score Distillation: From Corrupted Diffusion Pretraining to One-Step High-Quality Generation
May 19, 2025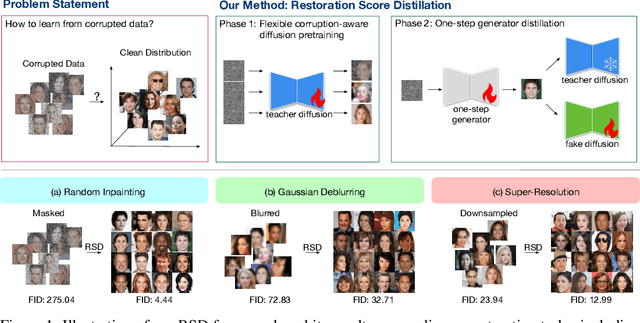


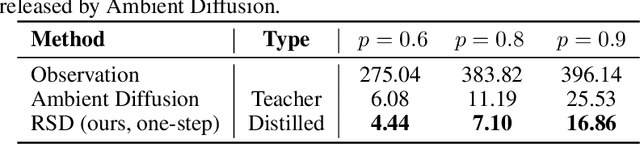
Learning generative models from corrupted data is a fundamental yet persistently challenging task across scientific disciplines, particularly when access to clean data is limited or expensive. Denoising Score Distillation (DSD) \cite{chen2025denoising} recently introduced a novel and surprisingly effective strategy that leverages score distillation to train high-fidelity generative models directly from noisy observations. Building upon this foundation, we propose \textit{Restoration Score Distillation} (RSD), a principled generalization of DSD that accommodates a broader range of corruption types, such as blurred, incomplete, or low-resolution images. RSD operates by first pretraining a teacher diffusion model solely on corrupted data and subsequently distilling it into a single-step generator that produces high-quality reconstructions. Empirically, RSD consistently surpasses its teacher model across diverse restoration tasks on both natural and scientific datasets. Moreover, beyond standard diffusion objectives, the RSD framework is compatible with several corruption-aware training techniques such as Ambient Tweedie, Ambient Diffusion, and its Fourier-space variant, enabling flexible integration with recent advances in diffusion modeling. Theoretically, we demonstrate that in a linear regime, RSD recovers the eigenspace of the clean data covariance matrix from linear measurements, thereby serving as an implicit regularizer. This interpretation recasts score distillation not only as a sampling acceleration technique but as a principled approach to enhancing generative performance in severely degraded data regimes.
GarmageNet: A Dataset and Scalable Representation for Generic Garment Modeling
Apr 02, 2025



High-fidelity garment modeling remains challenging due to the lack of large-scale, high-quality datasets and efficient representations capable of handling non-watertight, multi-layer geometries. In this work, we introduce Garmage, a neural-network-and-CG-friendly garment representation that seamlessly encodes the accurate geometry and sewing pattern of complex multi-layered garments as a structured set of per-panel geometry images. As a dual-2D-3D representation, Garmage achieves an unprecedented integration of 2D image-based algorithms with 3D modeling workflows, enabling high fidelity, non-watertight, multi-layered garment geometries with direct compatibility for industrial-grade simulations.Built upon this representation, we present GarmageNet, a novel generation framework capable of producing detailed multi-layered garments with body-conforming initial geometries and intricate sewing patterns, based on user prompts or existing in-the-wild sewing patterns. Furthermore, we introduce a robust stitching algorithm that recovers per-vertex stitches, ensuring seamless integration into flexible simulation pipelines for downstream editing of sewing patterns, material properties, and dynamic simulations. Finally, we release an industrial-standard, large-scale, high-fidelity garment dataset featuring detailed annotations, vertex-wise correspondences, and a robust pipeline for converting unstructured production sewing patterns into GarmageNet standard structural assets, paving the way for large-scale, industrial-grade garment generation systems.
Denoising Score Distillation: From Noisy Diffusion Pretraining to One-Step High-Quality Generation
Mar 10, 2025Diffusion models have achieved remarkable success in generating high-resolution, realistic images across diverse natural distributions. However, their performance heavily relies on high-quality training data, making it challenging to learn meaningful distributions from corrupted samples. This limitation restricts their applicability in scientific domains where clean data is scarce or costly to obtain. In this work, we introduce denoising score distillation (DSD), a surprisingly effective and novel approach for training high-quality generative models from low-quality data. DSD first pretrains a diffusion model exclusively on noisy, corrupted samples and then distills it into a one-step generator capable of producing refined, clean outputs. While score distillation is traditionally viewed as a method to accelerate diffusion models, we show that it can also significantly enhance sample quality, particularly when starting from a degraded teacher model. Across varying noise levels and datasets, DSD consistently improves generative performancewe summarize our empirical evidence in Fig. 1. Furthermore, we provide theoretical insights showing that, in a linear model setting, DSD identifies the eigenspace of the clean data distributions covariance matrix, implicitly regularizing the generator. This perspective reframes score distillation as not only a tool for efficiency but also a mechanism for improving generative models, particularly in low-quality data settings.
DesignDiffusion: High-Quality Text-to-Design Image Generation with Diffusion Models
Mar 03, 2025



In this paper, we present DesignDiffusion, a simple yet effective framework for the novel task of synthesizing design images from textual descriptions. A primary challenge lies in generating accurate and style-consistent textual and visual content. Existing works in a related task of visual text generation often focus on generating text within given specific regions, which limits the creativity of generation models, resulting in style or color inconsistencies between textual and visual elements if applied to design image generation. To address this issue, we propose an end-to-end, one-stage diffusion-based framework that avoids intricate components like position and layout modeling. Specifically, the proposed framework directly synthesizes textual and visual design elements from user prompts. It utilizes a distinctive character embedding derived from the visual text to enhance the input prompt, along with a character localization loss for enhanced supervision during text generation. Furthermore, we employ a self-play Direct Preference Optimization fine-tuning strategy to improve the quality and accuracy of the synthesized visual text. Extensive experiments demonstrate that DesignDiffusion achieves state-of-the-art performance in design image generation.
SmartEraser: Remove Anything from Images using Masked-Region Guidance
Jan 14, 2025



Object removal has so far been dominated by the mask-and-inpaint paradigm, where the masked region is excluded from the input, leaving models relying on unmasked areas to inpaint the missing region. However, this approach lacks contextual information for the masked area, often resulting in unstable performance. In this work, we introduce SmartEraser, built with a new removing paradigm called Masked-Region Guidance. This paradigm retains the masked region in the input, using it as guidance for the removal process. It offers several distinct advantages: (a) it guides the model to accurately identify the object to be removed, preventing its regeneration in the output; (b) since the user mask often extends beyond the object itself, it aids in preserving the surrounding context in the final result. Leveraging this new paradigm, we present Syn4Removal, a large-scale object removal dataset, where instance segmentation data is used to copy and paste objects onto images as removal targets, with the original images serving as ground truths. Experimental results demonstrate that SmartEraser significantly outperforms existing methods, achieving superior performance in object removal, especially in complex scenes with intricate compositions.
Enhancing and Accelerating Diffusion-Based Inverse Problem Solving through Measurements Optimization
Dec 05, 2024Diffusion models have recently demonstrated notable success in solving inverse problems. However, current diffusion model-based solutions typically require a large number of function evaluations (NFEs) to generate high-quality images conditioned on measurements, as they incorporate only limited information at each step. To accelerate the diffusion-based inverse problem-solving process, we introduce \textbf{M}easurements \textbf{O}ptimization (MO), a more efficient plug-and-play module for integrating measurement information at each step of the inverse problem-solving process. This method is comprehensively evaluated across eight diverse linear and nonlinear tasks on the FFHQ and ImageNet datasets. By using MO, we establish state-of-the-art (SOTA) performance across multiple tasks, with key advantages: (1) it operates with no more than 100 NFEs, with phase retrieval on ImageNet being the sole exception; (2) it achieves SOTA or near-SOTA results even at low NFE counts; and (3) it can be seamlessly integrated into existing diffusion model-based solutions for inverse problems, such as DPS \cite{chung2022diffusion} and Red-diff \cite{mardani2023variational}. For example, DPS-MO attains a peak signal-to-noise ratio (PSNR) of 28.71 dB on the FFHQ 256 dataset for high dynamic range imaging, setting a new SOTA benchmark with only 100 NFEs, whereas current methods require between 1000 and 4000 NFEs for comparable performance.
Effort: Efficient Orthogonal Modeling for Generalizable AI-Generated Image Detection
Nov 23, 2024



Existing AI-generated image (AIGI) detection methods often suffer from limited generalization performance. In this paper, we identify a crucial yet previously overlooked asymmetry phenomenon in AIGI detection: during training, models tend to quickly overfit to specific fake patterns in the training set, while other information is not adequately captured, leading to poor generalization when faced with new fake methods. A key insight is to incorporate the rich semantic knowledge embedded within large-scale vision foundation models (VFMs) to expand the previous discriminative space (based on forgery patterns only), such that the discrimination is decided by both forgery and semantic cues, thereby reducing the overfitting to specific forgery patterns. A straightforward solution is to fully fine-tune VFMs, but it risks distorting the well-learned semantic knowledge, pushing the model back toward overfitting. To this end, we design a novel approach called Effort: Efficient orthogonal modeling for generalizable AIGI detection. Specifically, we employ Singular Value Decomposition (SVD) to construct the orthogonal semantic and forgery subspaces. By freezing the principal components and adapting the residual components ($\sim$0.19M parameters), we preserve the original semantic subspace and use its orthogonal subspace for learning forgeries. Extensive experiments on AIGI detection benchmarks demonstrate the superior effectiveness of our approach.
One-Step Diffusion Policy: Fast Visuomotor Policies via Diffusion Distillation
Oct 28, 2024



Diffusion models, praised for their success in generative tasks, are increasingly being applied to robotics, demonstrating exceptional performance in behavior cloning. However, their slow generation process stemming from iterative denoising steps poses a challenge for real-time applications in resource-constrained robotics setups and dynamically changing environments. In this paper, we introduce the One-Step Diffusion Policy (OneDP), a novel approach that distills knowledge from pre-trained diffusion policies into a single-step action generator, significantly accelerating response times for robotic control tasks. We ensure the distilled generator closely aligns with the original policy distribution by minimizing the Kullback-Leibler (KL) divergence along the diffusion chain, requiring only $2\%$-$10\%$ additional pre-training cost for convergence. We evaluated OneDP on 6 challenging simulation tasks as well as 4 self-designed real-world tasks using the Franka robot. The results demonstrate that OneDP not only achieves state-of-the-art success rates but also delivers an order-of-magnitude improvement in inference speed, boosting action prediction frequency from 1.5 Hz to 62 Hz, establishing its potential for dynamic and computationally constrained robotic applications. We share the project page at https://research.nvidia.com/labs/dir/onedp/.
Adversarial Score identity Distillation: Rapidly Surpassing the Teacher in One Step
Oct 19, 2024



Score identity Distillation (SiD) is a data-free method that has achieved state-of-the-art performance in image generation by leveraging only a pretrained diffusion model, without requiring any training data. However, the ultimate performance of SiD is constrained by the accuracy with which the pretrained model captures the true data scores at different stages of the diffusion process. In this paper, we introduce SiDA (SiD with Adversarial Loss), which not only enhances generation quality but also improves distillation efficiency by incorporating real images and adversarial loss. SiDA utilizes the encoder from the generator's score network as a discriminator, boosting its ability to distinguish between real images and those generated by SiD. The adversarial loss is batch-normalized within each GPU and then combined with the original SiD loss. This integration effectively incorporates the average "fakeness" per GPU batch into the pixel-based SiD loss, enabling SiDA to distill a single-step generator either from scratch or by fine-tuning an existing one. SiDA converges significantly faster than its predecessor when trained from scratch, and swiftly improves upon the original model's performance after an initial warmup period during fine-tuning from a pre-distilled SiD generator. This one-step adversarial distillation method has set new benchmarks for generation performance when distilling EDM diffusion models pretrained on CIFAR-10 (32x32) and ImageNet (64x64), achieving FID scores of $\mathbf{1.499}$ on CIFAR-10 unconditional, $\mathbf{1.396}$ on CIFAR-10 conditional, and $\mathbf{1.110}$ on ImageNet 64x64. Our open-source code will be integrated into the SiD codebase on GitHub.