 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMATCHA: Matching Text via Contrastive Semantic Alignment
May 26, 2026Reliable evaluation is essential for understanding large language model (LLM) performance, yet today's go-to metrics, namely token-overlap scores (e.g., ROUGE) and embedding-based measures (e.g., BERTScore), often misjudge semantic similarity of documents. Our study shows that both token-overlap metrics and embedding-based metrics routinely assign nearly identical scores to texts that directly contradict each other, thereby potentially masking fundamental errors. We introduce MATCHA, an automatic metric that jointly rewards semantic agreement with a reference and penalizes contradictions. MATCHA employs a dual-view perspective that measures (i) proximity to the gold text and (ii) distance from an adversarially generated counterfactual contradiction. In eight public benchmarks, MATCHA outperforms popular metrics, compared with human annotations on question-answering, image caption generation, natural language inference, summarization, and semantic textual similarity tasks. On the TruthfulQA dataset (i.e., a dataset without a training set, where no embedding-based metrics could locally train on), this improvement in terms of matching texts with a reference reaches 18.38% over ROUGE-L and 20.82% over BERTScore. Both quantitative comparison and qualitative human assessments confirm the efficacy and validity of MATCHA and uncover fundamental weaknesses in pre-existing metrics. Compared with 23 embedding models, including top state-of-the-art ones, used as a metric similar to BERTScore, MATCHA remains the most accurate in distinguishing correct from incorrect statements solely based on a reference. Our code and metric are publicly available (https://github.com/Siran-Li/MATCHA).
Questions beyond Pixels: Integrating Commonsense Knowledge in Visual Question Generation for Remote Sensing
Feb 22, 2026With the rapid development of remote sensing image archives, asking questions about images has become an effective way of gathering specific information or performing semantic image retrieval. However, current automatically generated questions tend to be simplistic and template-based, which hinders the deployment of question answering or visual dialogue systems for real-world applications. To enrich and diversify the questions with both image content and commonsense knowledge, we propose a Knowledge-aware Remote Sensing Visual Question Generation model (KRSVQG). The proposed model incorporates related knowledge triplets from external knowledge sources to broaden the question content, while employing image captioning as an intermediary representation to ground questions to the corresponding images. Moreover, KRSVQG utilizes a vision-language pre-training and fine-tuning strategy, enabling the model's adaptation to low data regimes. To evaluate the proposed KRSVQG model, we construct two knowledge-aware remote sensing visual question generation datasets: the NWPU-300 dataset and the TextRS-300 dataset. Evaluations, including metrics and human assessment, demonstrate that KRSVQG outperforms existing methods and leads to rich questions, grounded in both image and domain knowledge. As a key practice in vision-language research, knowledge-aware visual question generation advances the understanding of image content beyond pixels, facilitating the development of knowledge-enriched vision-language systems with vision-grounded human commonsense.
Knowledge-aware Visual Question Generation for Remote Sensing Images
Feb 22, 2026With the rapid development of remote sensing image archives, asking questions about images has become an effective way of gathering specific information or performing image retrieval. However, automatically generated image-based questions tend to be simplistic and template-based, which hinders the real deployment of question answering or visual dialogue systems. To enrich and diversify the questions, we propose a knowledge-aware remote sensing visual question generation model, KRSVQG, that incorporates external knowledge related to the image content to improve the quality and contextual understanding of the generated questions. The model takes an image and a related knowledge triplet from external knowledge sources as inputs and leverages image captioning as an intermediary representation to enhance the image grounding of the generated questions. To assess the performance of KRSVQG, we utilized two datasets that we manually annotated: NWPU-300 and TextRS-300. Results on these two datasets demonstrate that KRSVQG outperforms existing methods and leads to knowledge-enriched questions, grounded in both image and domain knowledge.
SPDEBench: An Extensive Benchmark for Learning Regular and Singular Stochastic PDEs
May 24, 2025



Stochastic Partial Differential Equations (SPDEs) driven by random noise play a central role in modelling physical processes whose spatio-temporal dynamics can be rough, such as turbulence flows, superconductors, and quantum dynamics. To efficiently model these processes and make predictions, machine learning (ML)-based surrogate models are proposed, with their network architectures incorporating the spatio-temporal roughness in their design. However, it lacks an extensive and unified datasets for SPDE learning; especially, existing datasets do not account for the computational error introduced by noise sampling and the necessary renormalization required for handling singular SPDEs. We thus introduce SPDEBench, which is designed to solve typical SPDEs of physical significance (e.g., the $\Phi^4_d$, wave, incompressible Navier--Stokes, and KdV equations) on 1D or 2D tori driven by white noise via ML methods. New datasets for singular SPDEs based on the renormalization process have been constructed, and novel ML models achieving the best results to date have been proposed. In particular, we investigate the impact of computational error introduced by noise sampling and renormalization on the performance comparison of ML models and highlight the importance of selecting high-quality test data for accurate evaluation. Results are benchmarked with traditional numerical solvers and ML-based models, including FNO, NSPDE and DLR-Net, etc. It is shown that, for singular SPDEs, naively applying ML models on data without specifying the numerical schemes can lead to significant errors and misleading conclusions. Our SPDEBench provides an open-source codebase that ensures full reproducibility of benchmarking across a variety of SPDE datasets while offering the flexibility to incorporate new datasets and machine learning baselines, making it a valuable resource for the community.
GarmageNet: A Dataset and Scalable Representation for Generic Garment Modeling
Apr 02, 2025



High-fidelity garment modeling remains challenging due to the lack of large-scale, high-quality datasets and efficient representations capable of handling non-watertight, multi-layer geometries. In this work, we introduce Garmage, a neural-network-and-CG-friendly garment representation that seamlessly encodes the accurate geometry and sewing pattern of complex multi-layered garments as a structured set of per-panel geometry images. As a dual-2D-3D representation, Garmage achieves an unprecedented integration of 2D image-based algorithms with 3D modeling workflows, enabling high fidelity, non-watertight, multi-layered garment geometries with direct compatibility for industrial-grade simulations.Built upon this representation, we present GarmageNet, a novel generation framework capable of producing detailed multi-layered garments with body-conforming initial geometries and intricate sewing patterns, based on user prompts or existing in-the-wild sewing patterns. Furthermore, we introduce a robust stitching algorithm that recovers per-vertex stitches, ensuring seamless integration into flexible simulation pipelines for downstream editing of sewing patterns, material properties, and dynamic simulations. Finally, we release an industrial-standard, large-scale, high-fidelity garment dataset featuring detailed annotations, vertex-wise correspondences, and a robust pipeline for converting unstructured production sewing patterns into GarmageNet standard structural assets, paving the way for large-scale, industrial-grade garment generation systems.
Enhancing Retrieval-Augmented Generation: A Study of Best Practices
Jan 13, 2025



Retrieval-Augmented Generation (RAG) systems have recently shown remarkable advancements by integrating retrieval mechanisms into language models, enhancing their ability to produce more accurate and contextually relevant responses. However, the influence of various components and configurations within RAG systems remains underexplored. A comprehensive understanding of these elements is essential for tailoring RAG systems to complex retrieval tasks and ensuring optimal performance across diverse applications. In this paper, we develop several advanced RAG system designs that incorporate query expansion, various novel retrieval strategies, and a novel Contrastive In-Context Learning RAG. Our study systematically investigates key factors, including language model size, prompt design, document chunk size, knowledge base size, retrieval stride, query expansion techniques, Contrastive In-Context Learning knowledge bases, multilingual knowledge bases, and Focus Mode retrieving relevant context at sentence-level. Through extensive experimentation, we provide a detailed analysis of how these factors influence response quality. Our findings offer actionable insights for developing RAG systems, striking a balance between contextual richness and retrieval-generation efficiency, thereby paving the way for more adaptable and high-performing RAG frameworks in diverse real-world scenarios. Our code and implementation details are publicly available.
PCF-GAN: generating sequential data via the characteristic function of measures on the path space
May 21, 2023



Generating high-fidelity time series data using generative adversarial networks (GANs) remains a challenging task, as it is difficult to capture the temporal dependence of joint probability distributions induced by time-series data. Towards this goal, a key step is the development of an effective discriminator to distinguish between time series distributions. We propose the so-called PCF-GAN, a novel GAN that incorporates the path characteristic function (PCF) as the principled representation of time series distribution into the discriminator to enhance its generative performance. On the one hand, we establish theoretical foundations of the PCF distance by proving its characteristicity, boundedness, differentiability with respect to generator parameters, and weak continuity, which ensure the stability and feasibility of training the PCF-GAN. On the other hand, we design efficient initialisation and optimisation schemes for PCFs to strengthen the discriminative power and accelerate training efficiency. To further boost the capabilities of complex time series generation, we integrate the auto-encoder structure via sequential embedding into the PCF-GAN, which provides additional reconstruction functionality. Extensive numerical experiments on various datasets demonstrate the consistently superior performance of PCF-GAN over state-of-the-art baselines, in both generation and reconstruction quality. Code is available at https://github.com/DeepIntoStreams/PCF-GAN.
Gaussian kernels on non-simply-connected closed Riemannian manifolds are never positive definite
Mar 12, 2023We show that the Gaussian kernel $\exp\left\{-\lambda d_g^2(\bullet, \bullet)\right\}$ on any non-simply-connected closed Riemannian manifold $(\mathcal{M},g)$, where $d_g$ is the geodesic distance, is not positive definite for any $\lambda > 0$, combining analyses in the recent preprint~[9] by Da Costa--Mostajeran--Ortega and classical comparison theorems in Riemannian geometry.
Path Development Network with Finite-dimensional Lie Group Representation
Apr 02, 2022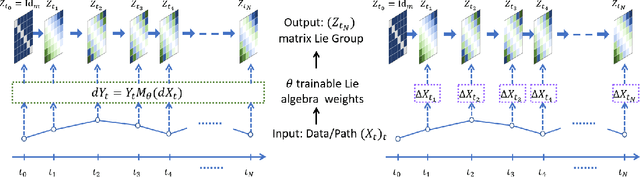
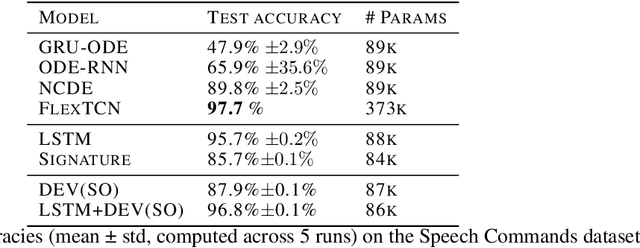
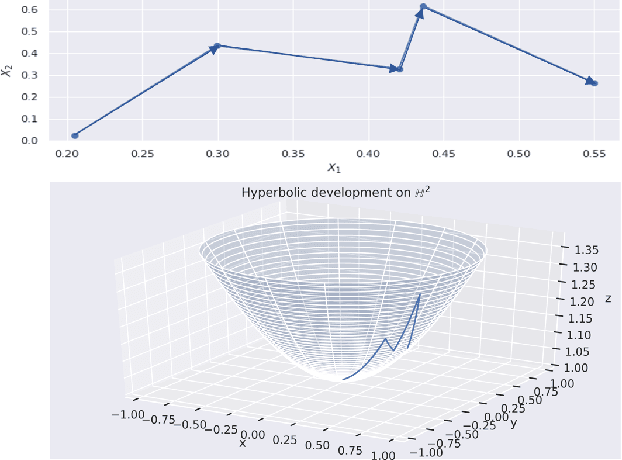
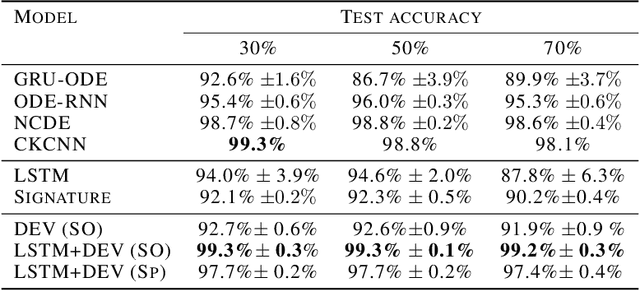
The path signature, a mathematically principled and universal feature of sequential data, leads to a performance boost of deep learning-based models in various sequential data tasks as a complimentary feature. However, it suffers from the curse of dimensionality when the path dimension is high. To tackle this problem, we propose a novel, trainable path development layer, which exploits representations of sequential data with the help of finite-dimensional matrix Lie groups. We also design the backpropagation algorithm of the development layer via an optimisation method on manifolds known as trivialisation. Numerical experiments demonstrate that the path development consistently and significantly outperforms, in terms of accuracy and dimensionality, signature features on several empirical datasets. Moreover, stacking the LSTM with the development layer with a suitable matrix Lie group is empirically proven to alleviate the gradient issues of LSTMs and the resulting hybrid model achieves the state-of-the-art performance.