 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Causal-Driven Representation Learning for Generalizable Medical Image Segmentation
Aug 07, 2025Vision-Language Models (VLMs), such as CLIP, have demonstrated remarkable zero-shot capabilities in various computer vision tasks. However, their application to medical imaging remains challenging due to the high variability and complexity of medical data. Specifically, medical images often exhibit significant domain shifts caused by various confounders, including equipment differences, procedure artifacts, and imaging modes, which can lead to poor generalization when models are applied to unseen domains. To address this limitation, we propose Multimodal Causal-Driven Representation Learning (MCDRL), a novel framework that integrates causal inference with the VLM to tackle domain generalization in medical image segmentation. MCDRL is implemented in two steps: first, it leverages CLIP's cross-modal capabilities to identify candidate lesion regions and construct a confounder dictionary through text prompts, specifically designed to represent domain-specific variations; second, it trains a causal intervention network that utilizes this dictionary to identify and eliminate the influence of these domain-specific variations while preserving the anatomical structural information critical for segmentation tasks. Extensive experiments demonstrate that MCDRL consistently outperforms competing methods, yielding superior segmentation accuracy and exhibiting robust generalizability.
MM2CT: MR-to-CT translation for multi-modal image fusion with mamba
Aug 07, 2025Magnetic resonance (MR)-to-computed tomography (CT) translation offers significant advantages, including the elimination of radiation exposure associated with CT scans and the mitigation of imaging artifacts caused by patient motion. The existing approaches are based on single-modality MR-to-CT translation, with limited research exploring multimodal fusion. To address this limitation, we introduce Multi-modal MR to CT (MM2CT) translation method by leveraging multimodal T1- and T2-weighted MRI data, an innovative Mamba-based framework for multi-modal medical image synthesis. Mamba effectively overcomes the limited local receptive field in CNNs and the high computational complexity issues in Transformers. MM2CT leverages this advantage to maintain long-range dependencies modeling capabilities while achieving multi-modal MR feature integration. Additionally, we incorporate a dynamic local convolution module and a dynamic enhancement module to improve MRI-to-CT synthesis. The experiments on a public pelvis dataset demonstrate that MM2CT achieves state-of-the-art performance in terms of Structural Similarity Index Measure (SSIM) and Peak Signal-to-Noise Ratio (PSNR). Our code is publicly available at https://github.com/Gots-ch/MM2CT.
Unleashing the Potential of Consistency Learning for Detecting and Grounding Multi-Modal Media Manipulation
Jun 06, 2025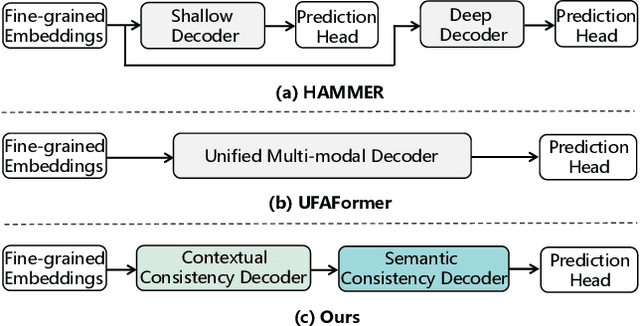
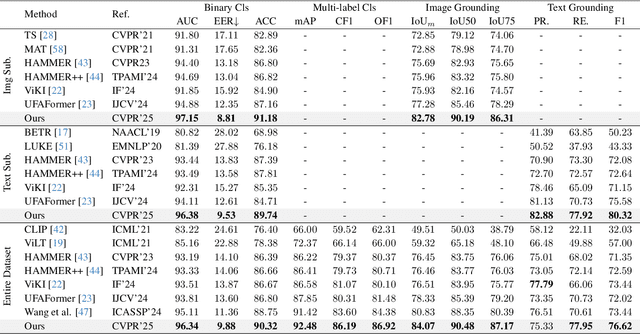
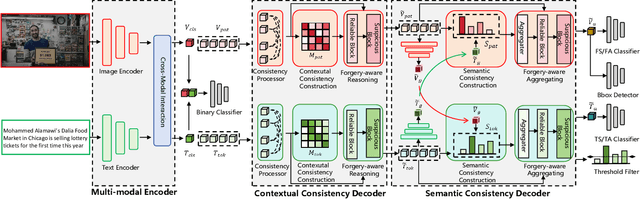
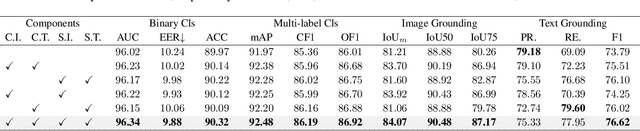
To tackle the threat of fake news, the task of detecting and grounding multi-modal media manipulation DGM4 has received increasing attention. However, most state-of-the-art methods fail to explore the fine-grained consistency within local content, usually resulting in an inadequate perception of detailed forgery and unreliable results. In this paper, we propose a novel approach named Contextual-Semantic Consistency Learning (CSCL) to enhance the fine-grained perception ability of forgery for DGM4. Two branches for image and text modalities are established, each of which contains two cascaded decoders, i.e., Contextual Consistency Decoder (CCD) and Semantic Consistency Decoder (SCD), to capture within-modality contextual consistency and across-modality semantic consistency, respectively. Both CCD and SCD adhere to the same criteria for capturing fine-grained forgery details. To be specific, each module first constructs consistency features by leveraging additional supervision from the heterogeneous information of each token pair. Then, the forgery-aware reasoning or aggregating is adopted to deeply seek forgery cues based on the consistency features. Extensive experiments on DGM4 datasets prove that CSCL achieves new state-of-the-art performance, especially for the results of grounding manipulated content. Codes and weights are avaliable at https://github.com/liyih/CSCL.
SA-Person: Text-Based Person Retrieval with Scene-aware Re-ranking
May 30, 2025Text-based person retrieval aims to identify a target individual from a gallery of images based on a natural language description. It presents a significant challenge due to the complexity of real-world scenes and the ambiguity of appearance-related descriptions. Existing methods primarily emphasize appearance-based cross-modal retrieval, often neglecting the contextual information embedded within the scene, which can offer valuable complementary insights for retrieval. To address this, we introduce SCENEPERSON-13W, a large-scale dataset featuring over 100,000 scenes with rich annotations covering both pedestrian appearance and environmental cues. Based on this, we propose SA-Person, a two-stage retrieval framework. In the first stage, it performs discriminative appearance grounding by aligning textual cues with pedestrian-specific regions. In the second stage, it introduces SceneRanker, a training-free, scene-aware re-ranking method leveraging multimodal large language models to jointly reason over pedestrian appearance and the global scene context. Experiments on SCENEPERSON-13W validate the effectiveness of our framework in challenging scene-level retrieval scenarios. The code and dataset will be made publicly available.
From Data to Modeling: Fully Open-vocabulary Scene Graph Generation
May 26, 2025We present OvSGTR, a novel transformer-based framework for fully open-vocabulary scene graph generation that overcomes the limitations of traditional closed-set models. Conventional methods restrict both object and relationship recognition to a fixed vocabulary, hindering their applicability to real-world scenarios where novel concepts frequently emerge. In contrast, our approach jointly predicts objects (nodes) and their inter-relationships (edges) beyond predefined categories. OvSGTR leverages a DETR-like architecture featuring a frozen image backbone and text encoder to extract high-quality visual and semantic features, which are then fused via a transformer decoder for end-to-end scene graph prediction. To enrich the model's understanding of complex visual relations, we propose a relation-aware pre-training strategy that synthesizes scene graph annotations in a weakly supervised manner. Specifically, we investigate three pipelines--scene parser-based, LLM-based, and multimodal LLM-based--to generate transferable supervision signals with minimal manual annotation. Furthermore, we address the common issue of catastrophic forgetting in open-vocabulary settings by incorporating a visual-concept retention mechanism coupled with a knowledge distillation strategy, ensuring that the model retains rich semantic cues during fine-tuning. Extensive experiments on the VG150 benchmark demonstrate that OvSGTR achieves state-of-the-art performance across multiple settings, including closed-set, open-vocabulary object detection-based, relation-based, and fully open-vocabulary scenarios. Our results highlight the promise of large-scale relation-aware pre-training and transformer architectures for advancing scene graph generation towards more generalized and reliable visual understanding.
Benchmarking Unified Face Attack Detection via Hierarchical Prompt Tuning
May 19, 2025Presentation Attack Detection and Face Forgery Detection are designed to protect face data from physical media-based Presentation Attacks and digital editing-based DeepFakes respectively. But separate training of these two models makes them vulnerable to unknown attacks and burdens deployment environments. The lack of a Unified Face Attack Detection model to handle both types of attacks is mainly due to two factors. First, there's a lack of adequate benchmarks for models to explore. Existing UAD datasets have limited attack types and samples, restricting the model's ability to address advanced threats. To address this, we propose UniAttackDataPlus (UniAttackData+), the most extensive and sophisticated collection of forgery techniques to date. It includes 2,875 identities and their 54 kinds of falsified samples, totaling 697,347 videos. Second, there's a lack of a reliable classification criterion. Current methods try to find an arbitrary criterion within the same semantic space, which fails when encountering diverse attacks. So, we present a novel Visual-Language Model-based Hierarchical Prompt Tuning Framework (HiPTune) that adaptively explores multiple classification criteria from different semantic spaces. We build a Visual Prompt Tree to explore various classification rules hierarchically. Then, by adaptively pruning the prompts, the model can select the most suitable prompts to guide the encoder to extract discriminative features at different levels in a coarse-to-fine way. Finally, to help the model understand the classification criteria in visual space, we propose a Dynamically Prompt Integration module to project the visual prompts to the text encoder for more accurate semantics. Experiments on 12 datasets have shown the potential to inspire further innovations in the UAD field.
MLLM-Enhanced Face Forgery Detection: A Vision-Language Fusion Solution
May 04, 2025Reliable face forgery detection algorithms are crucial for countering the growing threat of deepfake-driven disinformation. Previous research has demonstrated the potential of Multimodal Large Language Models (MLLMs) in identifying manipulated faces. However, existing methods typically depend on either the Large Language Model (LLM) alone or an external detector to generate classification results, which often leads to sub-optimal integration of visual and textual modalities. In this paper, we propose VLF-FFD, a novel Vision-Language Fusion solution for MLLM-enhanced Face Forgery Detection. Our key contributions are twofold. First, we present EFF++, a frame-level, explainability-driven extension of the widely used FaceForensics++ (FF++) dataset. In EFF++, each manipulated video frame is paired with a textual annotation that describes both the forgery artifacts and the specific manipulation technique applied, enabling more effective and informative MLLM training. Second, we design a Vision-Language Fusion Network (VLF-Net) that promotes bidirectional interaction between visual and textual features, supported by a three-stage training pipeline to fully leverage its potential. VLF-FFD achieves state-of-the-art (SOTA) performance in both cross-dataset and intra-dataset evaluations, underscoring its exceptional effectiveness in face forgery detection.
Compile Scene Graphs with Reinforcement Learning
Apr 18, 2025Next token prediction is the fundamental principle for training large language models (LLMs), and reinforcement learning (RL) further enhances their reasoning performance. As an effective way to model language, image, video, and other modalities, the use of LLMs for end-to-end extraction of structured visual representations, such as scene graphs, remains underexplored. It requires the model to accurately produce a set of objects and relationship triplets, rather than generating text token by token. To achieve this, we introduce R1-SGG, a multimodal LLM (M-LLM) initially trained via supervised fine-tuning (SFT) on the scene graph dataset and subsequently refined using reinforcement learning to enhance its ability to generate scene graphs in an end-to-end manner. The SFT follows a conventional prompt-response paradigm, while RL requires the design of effective reward signals. Given the structured nature of scene graphs, we design a graph-centric reward function that integrates node-level rewards, edge-level rewards, and a format consistency reward. Our experiments demonstrate that rule-based RL substantially enhances model performance in the SGG task, achieving a zero failure rate--unlike supervised fine-tuning (SFT), which struggles to generalize effectively. Our code is available at https://github.com/gpt4vision/R1-SGG.
Mixture-of-Attack-Experts with Class Regularization for Unified Physical-Digital Face Attack Detection
Apr 01, 2025Facial recognition systems in real-world scenarios are susceptible to both digital and physical attacks. Previous methods have attempted to achieve classification by learning a comprehensive feature space. However, these methods have not adequately accounted for the inherent characteristics of physical and digital attack data, particularly the large intra class variation in attacks and the small inter-class variation between live and fake faces. To address these limitations, we propose the Fine-Grained MoE with Class-Aware Regularization CLIP framework (FG-MoE-CLIP-CAR), incorporating key improvements at both the feature and loss levels. At the feature level, we employ a Soft Mixture of Experts (Soft MoE) architecture to leverage different experts for specialized feature processing. Additionally, we refine the Soft MoE to capture more subtle differences among various types of fake faces. At the loss level, we introduce two constraint modules: the Disentanglement Module (DM) and the Cluster Distillation Module (CDM). The DM enhances class separability by increasing the distance between the centers of live and fake face classes. However, center-to-center constraints alone are insufficient to ensure distinctive representations for individual features. Thus, we propose the CDM to further cluster features around their respective class centers while maintaining separation from other classes. Moreover, specific attacks that significantly deviate from common attack patterns are often overlooked. To address this issue, our distance calculation prioritizes more distant features. Experimental results on two unified physical-digital attack datasets demonstrate that the proposed method achieves state-of-the-art (SOTA) performance.
MergeVQ: A Unified Framework for Visual Generation and Representation with Disentangled Token Merging and Quantization
Apr 01, 2025Masked Image Modeling (MIM) with Vector Quantization (VQ) has achieved great success in both self-supervised pre-training and image generation. However, most existing methods struggle to address the trade-off in shared latent space for generation quality vs. representation learning and efficiency. To push the limits of this paradigm, we propose MergeVQ, which incorporates token merging techniques into VQ-based generative models to bridge the gap between image generation and visual representation learning in a unified architecture. During pre-training, MergeVQ decouples top-k semantics from latent space with the token merge module after self-attention blocks in the encoder for subsequent Look-up Free Quantization (LFQ) and global alignment and recovers their fine-grained details through cross-attention in the decoder for reconstruction. As for the second-stage generation, we introduce MergeAR, which performs KV Cache compression for efficient raster-order prediction. Extensive experiments on ImageNet verify that MergeVQ as an AR generative model achieves competitive performance in both visual representation learning and image generation tasks while maintaining favorable token efficiency and inference speed. The code and model will be available at https://apexgen-x.github.io/MergeVQ.