 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Knowledge Representations for Large Language Model Editing
May 24, 2025Knowledge Editing has emerged as a promising solution for efficiently updating embedded knowledge in large language models (LLMs). While existing approaches demonstrate effectiveness in integrating new knowledge and preserving the original capabilities of LLMs, they fail to maintain fine-grained irrelevant knowledge facts that share the same subject as edited knowledge but differ in relation and object. This challenge arises because subject representations inherently encode multiple attributes, causing the target and fine-grained irrelevant knowledge to become entangled in the representation space, and thus vulnerable to unintended alterations during editing. To address this, we propose DiKE, a novel approach that Disentangles Knowledge representations for LLM Editing (DiKE). DiKE consists of two key components: a Knowledge Representation Disentanglement (KRD) module that decomposes the subject representation into target-knowledgerelated and -unrelated components, and a Disentanglement-based Knowledge Edit (DKE) module that updates only the target-related component while explicitly preserving the unrelated one. We further derive a closed-form, rank-one parameter update based on matrix theory to enable efficient and minimally invasive edits. To rigorously evaluate fine-grained irrelevant knowledge preservation, we construct FINE-KED, a new benchmark comprising fine-grained irrelevant knowledge at different levels of relational similarity to the edited knowledge. Extensive experiments across multiple LLMs demonstrate that DiKE substantially improves fine-grained irrelevant knowledge preservation while maintaining competitive general editing performance.
Joint Flashback Adaptation for Forgetting-Resistant Instruction Tuning
May 21, 2025Large language models have achieved remarkable success in various tasks. However, it is challenging for them to learn new tasks incrementally due to catastrophic forgetting. Existing approaches rely on experience replay, optimization constraints, or task differentiation, which encounter strict limitations in real-world scenarios. To address these issues, we propose Joint Flashback Adaptation. We first introduce flashbacks -- a limited number of prompts from old tasks -- when adapting to new tasks and constrain the deviations of the model outputs compared to the original one. We then interpolate latent tasks between flashbacks and new tasks to enable jointly learning relevant latent tasks, new tasks, and flashbacks, alleviating data sparsity in flashbacks and facilitating knowledge sharing for smooth adaptation. Our method requires only a limited number of flashbacks without access to the replay data and is task-agnostic. We conduct extensive experiments on state-of-the-art large language models across 1000+ instruction-following tasks, arithmetic reasoning tasks, and general reasoning tasks. The results demonstrate the superior performance of our method in improving generalization on new tasks and reducing forgetting in old tasks.
A Token is Worth over 1,000 Tokens: Efficient Knowledge Distillation through Low-Rank Clone
May 19, 2025
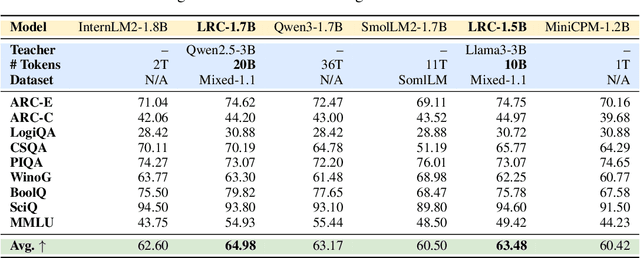
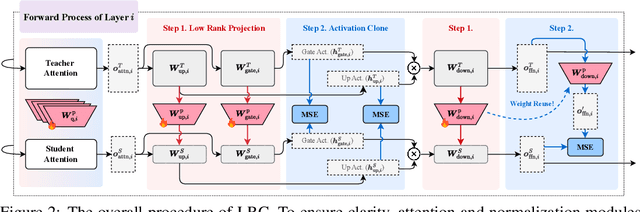
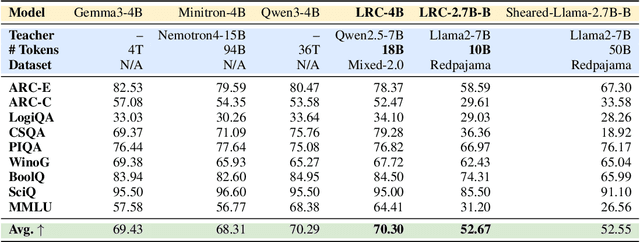
Training high-performing Small Language Models (SLMs) remains costly, even with knowledge distillation and pruning from larger teacher models. Existing work often faces three key challenges: (1) information loss from hard pruning, (2) inefficient alignment of representations, and (3) underutilization of informative activations, particularly from Feed-Forward Networks (FFNs). To address these challenges, we introduce Low-Rank Clone (LRC), an efficient pre-training method that constructs SLMs aspiring to behavioral equivalence with strong teacher models. LRC trains a set of low-rank projection matrices that jointly enable soft pruning by compressing teacher weights, and activation clone by aligning student activations, including FFN signals, with those of the teacher. This unified design maximizes knowledge transfer while removing the need for explicit alignment modules. Extensive experiments with open-source teachers (e.g., Llama-3.2-3B-Instruct, Qwen2.5-3B/7B-Instruct) show that LRC matches or surpasses state-of-the-art models trained on trillions of tokens--while using only 20B tokens, achieving over 1,000x training efficiency. Our codes and model checkpoints are available at https://github.com/CURRENTF/LowRankClone and https://huggingface.co/collections/JitaiHao/low-rank-clone-lrc-6828389e96a93f1d4219dfaf.
Direct Retrieval-augmented Optimization: Synergizing Knowledge Selection and Language Models
May 05, 2025Retrieval-augmented generation (RAG) integrates large language models ( LLM s) with retrievers to access external knowledge, improving the factuality of LLM generation in knowledge-grounded tasks. To optimize the RAG performance, most previous work independently fine-tunes the retriever to adapt to frozen LLM s or trains the LLMs to use documents retrieved by off-the-shelf retrievers, lacking end-to-end training supervision. Recent work addresses this limitation by jointly training these two components but relies on overly simplifying assumptions of document independence, which has been criticized for being far from real-world scenarios. Thus, effectively optimizing the overall RAG performance remains a critical challenge. We propose a direct retrieval-augmented optimization framework, named DRO, that enables end-to-end training of two key components: (i) a generative knowledge selection model and (ii) an LLM generator. DRO alternates between two phases: (i) document permutation estimation and (ii) re-weighted maximization, progressively improving RAG components through a variational approach. In the estimation step, we treat document permutation as a latent variable and directly estimate its distribution from the selection model by applying an importance sampling strategy. In the maximization step, we calibrate the optimization expectation using importance weights and jointly train the selection model and LLM generator. Our theoretical analysis reveals that DRO is analogous to policy-gradient methods in reinforcement learning. Extensive experiments conducted on five datasets illustrate that DRO outperforms the best baseline with 5%-15% improvements in EM and F1. We also provide in-depth experiments to qualitatively analyze the stability, convergence, and variance of DRO.
Replication and Exploration of Generative Retrieval over Dynamic Corpora
Apr 24, 2025Generative retrieval (GR) has emerged as a promising paradigm in information retrieval (IR). However, most existing GR models are developed and evaluated using a static document collection, and their performance in dynamic corpora where document collections evolve continuously is rarely studied. In this paper, we first reproduce and systematically evaluate various representative GR approaches over dynamic corpora. Through extensive experiments, we reveal that existing GR models with \textit{text-based} docids show superior generalization to unseen documents. We observe that the more fine-grained the docid design in the GR model, the better its performance over dynamic corpora, surpassing BM25 and even being comparable to dense retrieval methods. While GR models with \textit{numeric-based} docids show high efficiency, their performance drops significantly over dynamic corpora. Furthermore, our experiments find that the underperformance of numeric-based docids is partly due to their excessive tendency toward the initial document set, which likely results from overfitting on the training set. We then conduct an in-depth analysis of the best-performing GR methods. We identify three critical advantages of text-based docids in dynamic corpora: (i) Semantic alignment with language models' pretrained knowledge, (ii) Fine-grained docid design, and (iii) High lexical diversity. Building on these insights, we finally propose a novel multi-docid design that leverages both the efficiency of numeric-based docids and the effectiveness of text-based docids, achieving improved performance in dynamic corpus without requiring additional retraining. Our work offers empirical evidence for advancing GR methods over dynamic corpora and paves the way for developing more generalized yet efficient GR models in real-world search engines.
Improving Sequential Recommenders through Counterfactual Augmentation of System Exposure
Apr 18, 2025In sequential recommendation (SR), system exposure refers to items that are exposed to the user. Typically, only a few of the exposed items would be interacted with by the user. Although SR has achieved great success in predicting future user interests, existing SR methods still fail to fully exploit system exposure data. Most methods only model items that have been interacted with, while the large volume of exposed but non-interacted items is overlooked. Even methods that consider the whole system exposure typically train the recommender using only the logged historical system exposure, without exploring unseen user interests. In this paper, we propose counterfactual augmentation over system exposure for sequential recommendation (CaseRec). To better model historical system exposure, CaseRec introduces reinforcement learning to account for different exposure rewards. CaseRec uses a decision transformer-based sequential model to take an exposure sequence as input and assigns different rewards according to the user feedback. To further explore unseen user interests, CaseRec proposes to perform counterfactual augmentation, where exposed original items are replaced with counterfactual items. Then, a transformer-based user simulator is proposed to predict the user feedback reward for the augmented items. Augmentation, together with the user simulator, constructs counterfactual exposure sequences to uncover new user interests. Finally, CaseRec jointly uses the logged exposure sequences with the counterfactual exposure sequences to train a decision transformer-based sequential model for generating recommendation. Experiments on three real-world benchmarks show the effectiveness of CaseRec. Our code is available at https://github.com/ZiqiZhao1/CaseRec.
Constrained Auto-Regressive Decoding Constrains Generative Retrieval
Apr 14, 2025
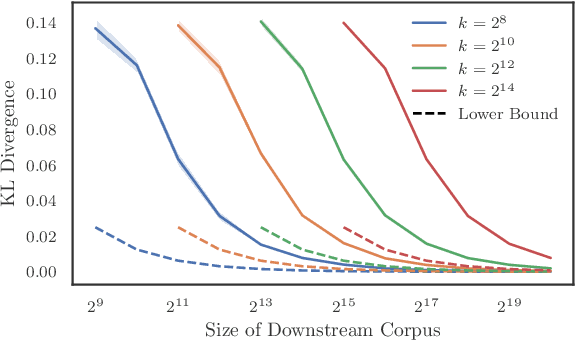
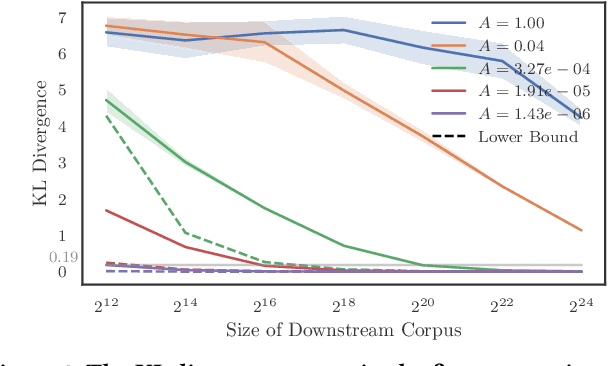
Generative retrieval seeks to replace traditional search index data structures with a single large-scale neural network, offering the potential for improved efficiency and seamless integration with generative large language models. As an end-to-end paradigm, generative retrieval adopts a learned differentiable search index to conduct retrieval by directly generating document identifiers through corpus-specific constrained decoding. The generalization capabilities of generative retrieval on out-of-distribution corpora have gathered significant attention. In this paper, we examine the inherent limitations of constrained auto-regressive generation from two essential perspectives: constraints and beam search. We begin with the Bayes-optimal setting where the generative retrieval model exactly captures the underlying relevance distribution of all possible documents. Then we apply the model to specific corpora by simply adding corpus-specific constraints. Our main findings are two-fold: (i) For the effect of constraints, we derive a lower bound of the error, in terms of the KL divergence between the ground-truth and the model-predicted step-wise marginal distributions. (ii) For the beam search algorithm used during generation, we reveal that the usage of marginal distributions may not be an ideal approach. This paper aims to improve our theoretical understanding of the generalization capabilities of the auto-regressive decoding retrieval paradigm, laying a foundation for its limitations and inspiring future advancements toward more robust and generalizable generative retrieval.
Cognitive Debiasing Large Language Models for Decision-Making
Apr 10, 2025



Large language models (LLMs) have shown potential in supporting decision-making applications, particularly as personal conversational assistants in the financial, healthcare, and legal domains. While prompt engineering strategies have enhanced the capabilities of LLMs in decision-making, cognitive biases inherent to LLMs present significant challenges. Cognitive biases are systematic patterns of deviation from norms or rationality in decision-making that can lead to the production of inaccurate outputs. Existing cognitive bias mitigation strategies assume that input prompts contain (exactly) one type of cognitive bias and therefore fail to perform well in realistic settings where there maybe any number of biases. To fill this gap, we propose a cognitive debiasing approach, called self-debiasing, that enhances the reliability of LLMs by iteratively refining prompts. Our method follows three sequential steps -- bias determination, bias analysis, and cognitive debiasing -- to iteratively mitigate potential cognitive biases in prompts. Experimental results on finance, healthcare, and legal decision-making tasks, using both closed-source and open-source LLMs, demonstrate that the proposed self-debiasing method outperforms both advanced prompt engineering methods and existing cognitive debiasing techniques in average accuracy under no-bias, single-bias, and multi-bias settings.
Unifying Search and Recommendation: A Generative Paradigm Inspired by Information Theory
Apr 09, 2025Recommender systems and search engines serve as foundational elements of online platforms, with the former delivering information proactively and the latter enabling users to seek information actively. Unifying both tasks in a shared model is promising since it can enhance user modeling and item understanding. Previous approaches mainly follow a discriminative paradigm, utilizing shared encoders to process input features and task-specific heads to perform each task. However, this paradigm encounters two key challenges: gradient conflict and manual design complexity. From the information theory perspective, these challenges potentially both stem from the same issue -- low mutual information between the input features and task-specific outputs during the optimization process. To tackle these issues, we propose GenSR, a novel generative paradigm for unifying search and recommendation (S&R), which leverages task-specific prompts to partition the model's parameter space into subspaces, thereby enhancing mutual information. To construct effective subspaces for each task, GenSR first prepares informative representations for each subspace and then optimizes both subspaces in one unified model. Specifically, GenSR consists of two main modules: (1) Dual Representation Learning, which independently models collaborative and semantic historical information to derive expressive item representations; and (2) S&R Task Unifying, which utilizes contrastive learning together with instruction tuning to generate task-specific outputs effectively. Extensive experiments on two public datasets show GenSR outperforms state-of-the-art methods across S&R tasks. Our work introduces a new generative paradigm compared with previous discriminative methods and establishes its superiority from the mutual information perspective.
UIPE: Enhancing LLM Unlearning by Removing Knowledge Related to Forgetting Targets
Mar 06, 2025Large Language Models (LLMs) inevitably acquire harmful information during training on massive datasets. LLM unlearning aims to eliminate the influence of such harmful information while maintaining the model's overall performance. Existing unlearning methods, represented by gradient ascent-based approaches, primarily focus on forgetting target data while overlooking the crucial impact of logically related knowledge on the effectiveness of unlearning. In this paper, through both theoretical and experimental analyses, we first demonstrate that a key reason for the suboptimal unlearning performance is that models can reconstruct the target content through reasoning with logically related knowledge. To address this issue, we propose Unlearning Improvement via Parameter Extrapolation (UIPE), a method that removes knowledge highly correlated with the forgetting targets. Experimental results show that UIPE significantly enhances the performance of various mainstream LLM unlearning methods on the TOFU benchmark.