 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering Context Reliance in Unstructured Knowledge Editing
Feb 22, 2026Editing Large language models (LLMs) with real-world, unstructured knowledge is essential for correcting and updating their internal parametric knowledge. In this work, we revisit the fundamental next-token prediction (NTP) as a candidate paradigm for unstructured editing. We identify Context Reliance as a critical failure mode of NTP-based approaches, where knowledge acquired from edited text becomes highly dependent on its preceding context, leading to recall failures when that context is absent during inference. This hypothesis is supported by our empirical validation that prepending context during inference recovers knowledge recall. We further theoretically demonstrate that Context Reliance is an inherent consequence of gradient-based optimization, which tends to bind acquired knowledge to a specific aggregated contextual representation. To address this, we propose a simple yet effective COntext-INdependent editing framework (COIN), encouraging model to focus on knowledge within local scope rather than memorizing contextual patterns. Evaluations show that COIN reduces Context Reliance by 45.2% and outperforms strong baselines by 23.6% in editing success rate, highlighting the vital role of mitigating Context Reliance for robust editing.
Self-Generative Adversarial Fine-Tuning for Large Language Models
Feb 01, 2026Fine-tuning large language models (LLMs) for alignment typically relies on supervised fine-tuning or reinforcement learning from human feedback, both limited by the cost and scarcity of high-quality annotations. Recent self-play and synthetic data approaches reduce this dependence but often rely on heuristic assumptions or ungrounded self-evaluation, which can cause bias accumulation and performance drift. In this paper, we propose Self-Generative Adversarial LLM (SGALM), a unified fine-tuning framework that formulates alignment as a generative adversarial game within a single LLM. SGALM jointly evolves generation and discrimination capabilities without external reward models. Theoretical and empirical results demonstrate that SGALM achieves state-of-the-art performance, serves as an effective alignment algorithm and a robust synthetic data engine.
OmniEVA: Embodied Versatile Planner via Task-Adaptive 3D-Grounded and Embodiment-aware Reasoning
Sep 11, 2025Recent advances in multimodal large language models (MLLMs) have opened new opportunities for embodied intelligence, enabling multimodal understanding, reasoning, and interaction, as well as continuous spatial decision-making. Nevertheless, current MLLM-based embodied systems face two critical limitations. First, Geometric Adaptability Gap: models trained solely on 2D inputs or with hard-coded 3D geometry injection suffer from either insufficient spatial information or restricted 2D generalization, leading to poor adaptability across tasks with diverse spatial demands. Second, Embodiment Constraint Gap: prior work often neglects the physical constraints and capacities of real robots, resulting in task plans that are theoretically valid but practically infeasible.To address these gaps, we introduce OmniEVA -- an embodied versatile planner that enables advanced embodied reasoning and task planning through two pivotal innovations: (1) a Task-Adaptive 3D Grounding mechanism, which introduces a gated router to perform explicit selective regulation of 3D fusion based on contextual requirements, enabling context-aware 3D grounding for diverse embodied tasks. (2) an Embodiment-Aware Reasoning framework that jointly incorporates task goals and embodiment constraints into the reasoning loop, resulting in planning decisions that are both goal-directed and executable. Extensive experimental results demonstrate that OmniEVA not only achieves state-of-the-art general embodied reasoning performance, but also exhibits a strong ability across a wide range of downstream scenarios. Evaluations of a suite of proposed embodied benchmarks, including both primitive and composite tasks, confirm its robust and versatile planning capabilities. Project page: https://omnieva.github.io
Bridging the Capability Gap: Joint Alignment Tuning for Harmonizing LLM-based Multi-Agent Systems
Sep 11, 2025The advancement of large language models (LLMs) has enabled the construction of multi-agent systems to solve complex tasks by dividing responsibilities among specialized agents, such as a planning agent for subgoal generation and a grounding agent for executing tool-use actions. Most existing methods typically fine-tune these agents independently, leading to capability gaps among them with poor coordination. To address this, we propose MOAT, a Multi-Agent Joint Alignment Tuning framework that improves agents collaboration through iterative alignment. MOAT alternates between two key stages: (1) Planning Agent Alignment, which optimizes the planning agent to generate subgoal sequences that better guide the grounding agent; and (2) Grounding Agent Improving, which fine-tunes the grounding agent using diverse subgoal-action pairs generated by the agent itself to enhance its generalization capablity. Theoretical analysis proves that MOAT ensures a non-decreasing and progressively convergent training process. Experiments across six benchmarks demonstrate that MOAT outperforms state-of-the-art baselines, achieving average improvements of 3.1% on held-in tasks and 4.4% on held-out tasks.
Dense Communication between Language Models
May 19, 2025As higher-level intelligence emerges from the combination of modular components with lower-level intelligence, many works combines Large Language Models (LLMs) for collective intelligence. Such combination is achieved by building communications among LLMs. While current systems primarily facilitate such communication through natural language, this paper proposes a novel paradigm of direct dense vector communication between LLMs. Our approach eliminates the unnecessary embedding and de-embedding steps when LLM interact with another, enabling more efficient information transfer, fully differentiable optimization pathways, and exploration of capabilities beyond human heuristics. We use such stripped LLMs as vertexes and optimizable seq2seq modules as edges to construct LMNet, with similar structure as MLPs. By utilizing smaller pre-trained LLMs as vertexes, we train a LMNet that achieves comparable performance with LLMs in similar size with only less than 0.1% training cost. This offers a new perspective on scaling for general intelligence rather than training a monolithic LLM from scratch. Besides, the proposed method can be used for other applications, like customizing LLM with limited data, showing its versatility.
Constrained Auto-Regressive Decoding Constrains Generative Retrieval
Apr 14, 2025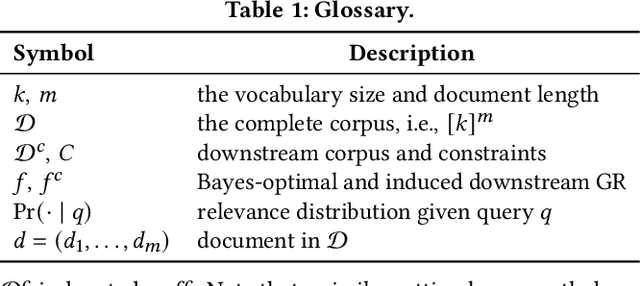
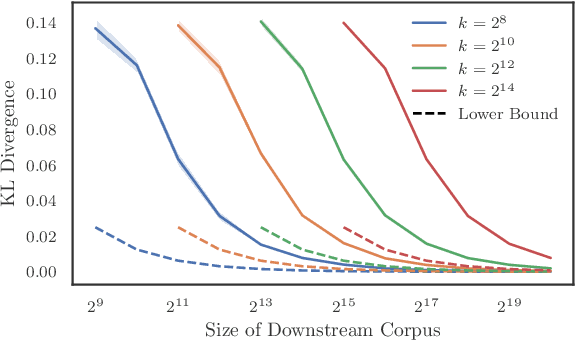
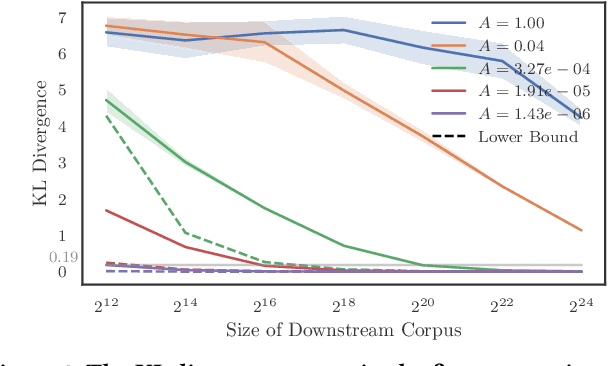
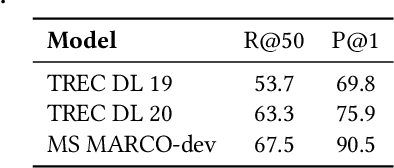
Generative retrieval seeks to replace traditional search index data structures with a single large-scale neural network, offering the potential for improved efficiency and seamless integration with generative large language models. As an end-to-end paradigm, generative retrieval adopts a learned differentiable search index to conduct retrieval by directly generating document identifiers through corpus-specific constrained decoding. The generalization capabilities of generative retrieval on out-of-distribution corpora have gathered significant attention. In this paper, we examine the inherent limitations of constrained auto-regressive generation from two essential perspectives: constraints and beam search. We begin with the Bayes-optimal setting where the generative retrieval model exactly captures the underlying relevance distribution of all possible documents. Then we apply the model to specific corpora by simply adding corpus-specific constraints. Our main findings are two-fold: (i) For the effect of constraints, we derive a lower bound of the error, in terms of the KL divergence between the ground-truth and the model-predicted step-wise marginal distributions. (ii) For the beam search algorithm used during generation, we reveal that the usage of marginal distributions may not be an ideal approach. This paper aims to improve our theoretical understanding of the generalization capabilities of the auto-regressive decoding retrieval paradigm, laying a foundation for its limitations and inspiring future advancements toward more robust and generalizable generative retrieval.
SpatialCoT: Advancing Spatial Reasoning through Coordinate Alignment and Chain-of-Thought for Embodied Task Planning
Jan 17, 2025



Spatial reasoning is an essential problem in embodied AI research. Efforts to enhance spatial reasoning abilities through supplementary spatial data and fine-tuning have proven limited and ineffective when addressing complex embodied tasks, largely due to their dependence on language-based outputs. While some approaches have introduced a point-based action space to mitigate this issue, they fall short in managing more intricate tasks within complex environments. This deficiency arises from their failure to fully exploit the inherent thinking and reasoning capabilities that are fundamental strengths of Vision-Language Models (VLMs). To address these limitations, we propose a novel approach named SpatialCoT, specifically designed to bolster the spatial reasoning capabilities of VLMs. Our approach comprises two stages: spatial coordinate bi-directional alignment, which aligns vision-language inputs with spatial coordinates, and chain-of-thought spatial grounding, which harnesses the reasoning capabilities of language models for advanced spatial reasoning. We evaluate SpatialCoT on challenging navigation and manipulation tasks, both in simulation and real-world settings. Experimental results demonstrate that our method significantly outperforms previous state-of-the-art approaches in both tasks.
ConML: A Universal Meta-Learning Framework with Task-Level Contrastive Learning
Oct 08, 2024



Meta-learning enables learning systems to adapt quickly to new tasks, similar to humans. To emulate this human-like rapid learning and enhance alignment and discrimination abilities, we propose ConML, a universal meta-learning framework that can be applied to various meta-learning algorithms without relying on specific model architectures nor target models. The core of ConML is task-level contrastive learning, which extends contrastive learning from the representation space in unsupervised learning to the model space in meta-learning. By leveraging task identity as an additional supervision signal during meta-training, we contrast the outputs of the meta-learner in the model space, minimizing inner-task distance (between models trained on different subsets of the same task) and maximizing inter-task distance (between models from different tasks). We demonstrate that ConML integrates seamlessly with optimization-based, metric-based, and amortization-based meta-learning algorithms, as well as in-context learning, resulting in performance improvements across diverse few-shot learning tasks.
Actra: Optimized Transformer Architecture for Vision-Language-Action Models in Robot Learning
Aug 02, 2024Vision-language-action models have gained significant attention for their ability to model trajectories in robot learning. However, most existing models rely on Transformer models with vanilla causal attention, which we find suboptimal for processing segmented multi-modal sequences. Additionally, the autoregressive generation approach falls short in generating multi-dimensional actions. In this paper, we introduce Actra, an optimized Transformer architecture featuring trajectory attention and learnable action queries, designed for effective encoding and decoding of segmented vision-language-action trajectories in robot imitation learning. Furthermore, we devise a multi-modal contrastive learning objective to explicitly align different modalities, complementing the primary behavior cloning objective. Through extensive experiments conducted across various environments, Actra exhibits substantial performance improvement when compared to state-of-the-art models in terms of generalizability, dexterity, and precision.
ExcluIR: Exclusionary Neural Information Retrieval
Apr 26, 2024



Exclusion is an important and universal linguistic skill that humans use to express what they do not want. However, in information retrieval community, there is little research on exclusionary retrieval, where users express what they do not want in their queries. In this work, we investigate the scenario of exclusionary retrieval in document retrieval for the first time. We present ExcluIR, a set of resources for exclusionary retrieval, consisting of an evaluation benchmark and a training set for helping retrieval models to comprehend exclusionary queries. The evaluation benchmark includes 3,452 high-quality exclusionary queries, each of which has been manually annotated. The training set contains 70,293 exclusionary queries, each paired with a positive document and a negative document. We conduct detailed experiments and analyses, obtaining three main observations: (1) Existing retrieval models with different architectures struggle to effectively comprehend exclusionary queries; (2) Although integrating our training data can improve the performance of retrieval models on exclusionary retrieval, there still exists a gap compared to human performance; (3) Generative retrieval models have a natural advantage in handling exclusionary queries. To facilitate future research on exclusionary retrieval, we share the benchmark and evaluation scripts on \url{https://github.com/zwh-sdu/ExcluIR}.