 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC$^{2}$R: Cross-sample Consistency Regularization Mitigates Feature Splitting and Absorption in Sparse Autoencoders
Jun 29, 2026Sparse Autoencoders (SAEs) are widely used to interpret large language models by decomposing activations into sparse, human-understandable features, but scaling to large dictionaries exposes fundamental challenges. Systematic studies reveal pervasive feature splitting that fragments coherent concepts into non-atomic latents and widespread feature absorption that creates arbitrary exceptions in general features, severely compromising latent reliability. These issues stem from inconsistent latent assignment across samples: without cross-sample constraints, per-sample optimization often allows a single underlying concept to be inconsistently distributed across multiple redundant or interfering latents. To address this, we introduce C$^2$R (\underline{\textbf{C}}ross-sample \underline{\textbf{C}}onsistency \underline{\textbf{R}}egularization). C$^2$R explicitly encourages that each semantic feature is consistently represented by a unified latent across the batch by penalizing the co-activation of directionally similar latents. Comprehensive evaluation demonstrates that C$^2$R effectively mitigates both splitting and absorption while, crucially, preserving reconstruction fidelity, providing a principled solution that enhances latent interpretability without degrading model performance. Source code is available at https://github.com/hr-jin/Cross-sample-Consistency-Regularization.
TAD: Temporal-Aware Trajectory Self-Distillation for Fast and Accurate Diffusion LLM
May 10, 2026Diffusion large language models (dLLMs) offer a promising paradigm for parallel text generation, but in practice they face an accuracy-parallelism trade-off, where increasing tokens per forward (TPF) often degrades generation quality. Existing acceleration methods often gain speed at the cost of accuracy. To address this limitation, we propose TAD, a Temporal-Aware trajectory self-Distillation framework. During data construction, we condition a teacher model on both the prompt and the ground-truth response to generate decoding trajectories, recording the intermediate masked states throughout the process. Based on how many decoding steps remain before each masked token is revealed, we partition masked positions into near and distant subsets. For near tokens, we train the student with a hard cross-entropy loss using the teacher trajectory tokens as labels, encouraging confident predictions for tokens that are about to be decoded. For distant tokens, we apply a soft KL divergence loss between the teacher and student token distributions, providing softer supervision and preserving future planning knowledge. This temporal-aware partition naturally gives rise to two deployment configurations: a Quality model that prioritizes accuracy and a Speed model that favors more aggressive acceleration. Experiments show that TAD consistently improves the accuracy-parallelism trade-off. On LLaDA, it raises average accuracy from 46.2\% to 51.6\% with the Quality model and average AUP from 46.2 to 257.1 with the Speed model. Our code is available at: https://github.com/BHmingyang/TAD
JoyAI-LLM Flash: Advancing Mid-Scale LLMs with Token Efficiency
Apr 03, 2026We introduce JoyAI-LLM Flash, an efficient Mixture-of-Experts (MoE) language model designed to redefine the trade-off between strong performance and token efficiency in the sub-50B parameter regime. JoyAI-LLM Flash is pretrained on a massive corpus of 20 trillion tokens and further optimized through a rigorous post-training pipeline, including supervised fine-tuning (SFT), Direct Preference Optimization (DPO), and large-scale reinforcement learning (RL) across diverse environments. To improve token efficiency, JoyAI-LLM Flash strategically balances \emph{thinking} and \emph{non-thinking} cognitive modes and introduces FiberPO, a novel RL algorithm inspired by fibration theory that decomposes trust-region maintenance into global and local components, providing unified multi-scale stability control for LLM policy optimization. To enhance architectural sparsity, the model comprises 48B total parameters while activating only 2.7B parameters per forward pass, achieving a substantially higher sparsity ratio than contemporary industry leading models of comparable scale. To further improve inference throughput, we adopt a joint training-inference co-design that incorporates dense Multi-Token Prediction (MTP) and Quantization-Aware Training (QAT). We release the checkpoints for both JoyAI-LLM-48B-A3B Base and its post-trained variants on Hugging Face to support the open-source community.
Cognitive Debiasing Large Language Models for Decision-Making
Apr 10, 2025



Large language models (LLMs) have shown potential in supporting decision-making applications, particularly as personal conversational assistants in the financial, healthcare, and legal domains. While prompt engineering strategies have enhanced the capabilities of LLMs in decision-making, cognitive biases inherent to LLMs present significant challenges. Cognitive biases are systematic patterns of deviation from norms or rationality in decision-making that can lead to the production of inaccurate outputs. Existing cognitive bias mitigation strategies assume that input prompts contain (exactly) one type of cognitive bias and therefore fail to perform well in realistic settings where there maybe any number of biases. To fill this gap, we propose a cognitive debiasing approach, called self-debiasing, that enhances the reliability of LLMs by iteratively refining prompts. Our method follows three sequential steps -- bias determination, bias analysis, and cognitive debiasing -- to iteratively mitigate potential cognitive biases in prompts. Experimental results on finance, healthcare, and legal decision-making tasks, using both closed-source and open-source LLMs, demonstrate that the proposed self-debiasing method outperforms both advanced prompt engineering methods and existing cognitive debiasing techniques in average accuracy under no-bias, single-bias, and multi-bias settings.
Unsupervised Classification for Polarimetric SAR Data Using Variational Bayesian Wishart Mixture Model with Inverse Gamma-Gamma Prior
Apr 04, 2021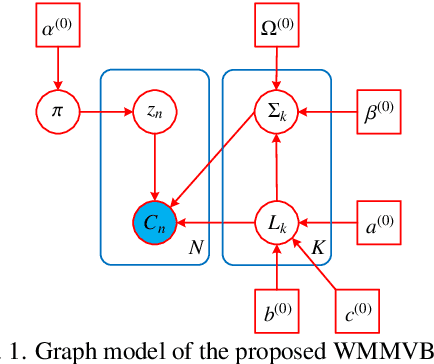
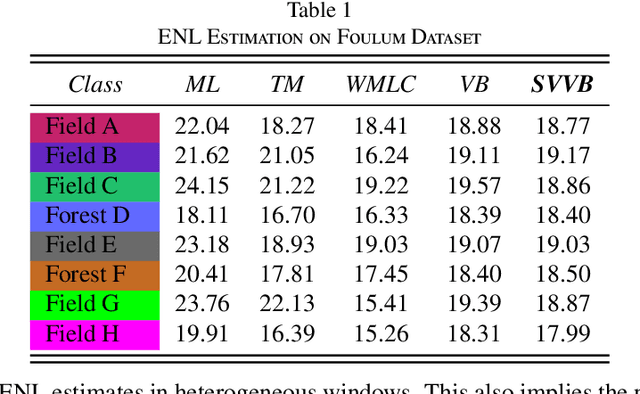
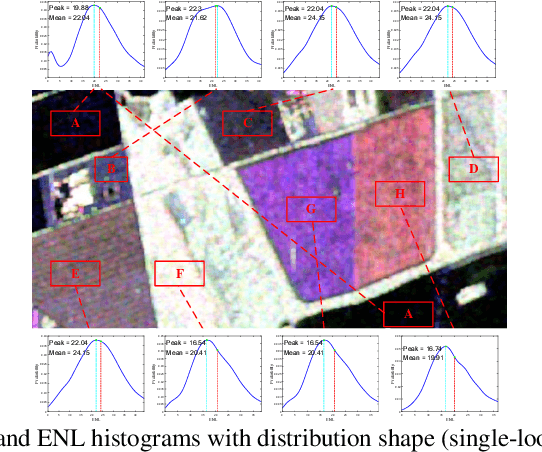
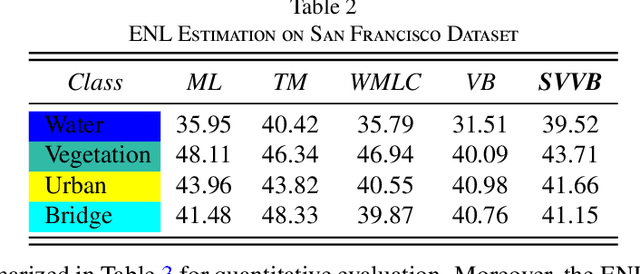
Although various clustering methods have been successfully applied to polarimetric synthetic aperture radar (PolSAR) image clustering tasks, most of the available approaches fail to realize automatic determination of cluster number, nor have they derived an exact distribution for the number of looks. To overcome these limitations and achieve robust unsupervised classification of PolSAR images, this paper proposes the variational Bayesian Wishart mixture model (VBWMM), where variational Bayesian expectation maximization (VBEM) technique is applied to estimate the variational posterior distribution of model parameters iteratively. Besides, covariance matrix similarity and geometric similarity are combined to incorporate spatial information of PolSAR images. Furthermore, we derive a new distribution named inverse gamma-gamma (IGG) prior that originates from the log-likelihood function of proposed model to enable efficient handling of number of looks. As a result, we obtain a closed-form variational lower bound, which can be used to evaluate the convergence of proposed model. We validate the superiority of proposed method in clustering performance on four real-measured datasets and demonstrate significant improvements towards conventional methods. As a by-product, the experiments show that our proposed IGG prior is effective in estimating the number of looks.