 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Tailed Classification of Thorax Diseases on Chest X-Ray: A New Benchmark Study
Aug 29, 2022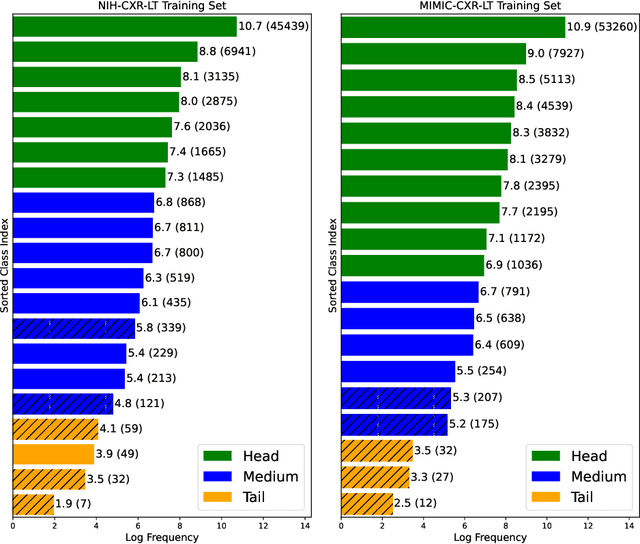
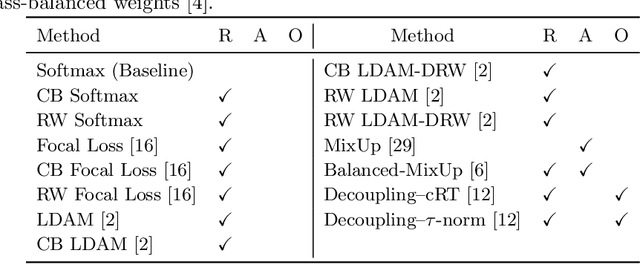
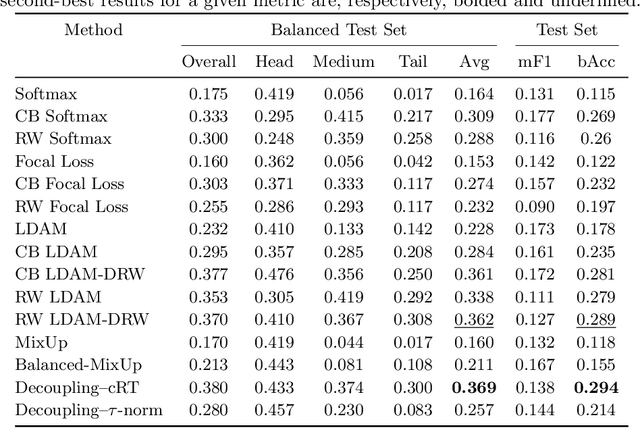
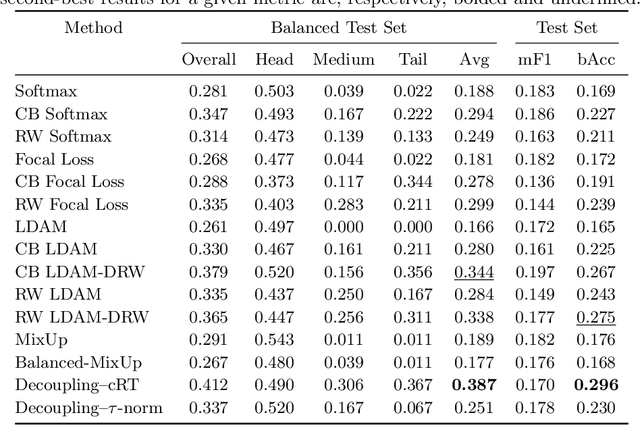
Imaging exams, such as chest radiography, will yield a small set of common findings and a much larger set of uncommon findings. While a trained radiologist can learn the visual presentation of rare conditions by studying a few representative examples, teaching a machine to learn from such a "long-tailed" distribution is much more difficult, as standard methods would be easily biased toward the most frequent classes. In this paper, we present a comprehensive benchmark study of the long-tailed learning problem in the specific domain of thorax diseases on chest X-rays. We focus on learning from naturally distributed chest X-ray data, optimizing classification accuracy over not only the common "head" classes, but also the rare yet critical "tail" classes. To accomplish this, we introduce a challenging new long-tailed chest X-ray benchmark to facilitate research on developing long-tailed learning methods for medical image classification. The benchmark consists of two chest X-ray datasets for 19- and 20-way thorax disease classification, containing classes with as many as 53,000 and as few as 7 labeled training images. We evaluate both standard and state-of-the-art long-tailed learning methods on this new benchmark, analyzing which aspects of these methods are most beneficial for long-tailed medical image classification and summarizing insights for future algorithm design. The datasets, trained models, and code are available at https://github.com/VITA-Group/LongTailCXR.
Auto-ViT-Acc: An FPGA-Aware Automatic Acceleration Framework for Vision Transformer with Mixed-Scheme Quantization
Aug 10, 2022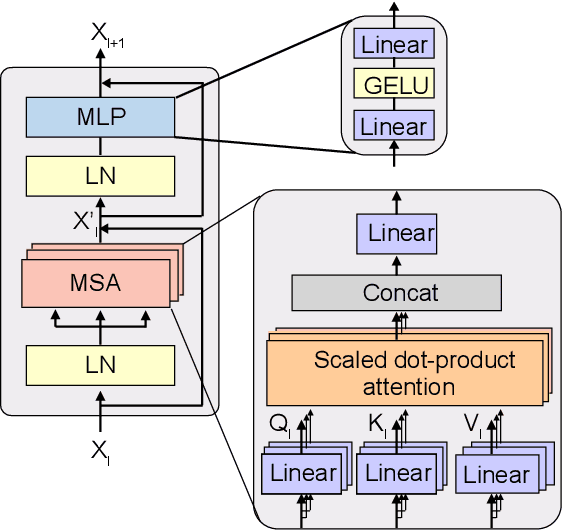
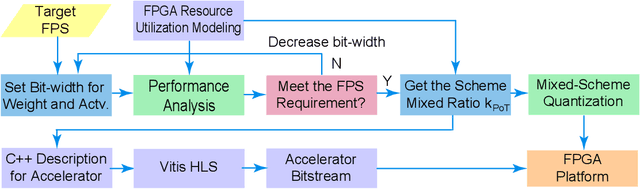
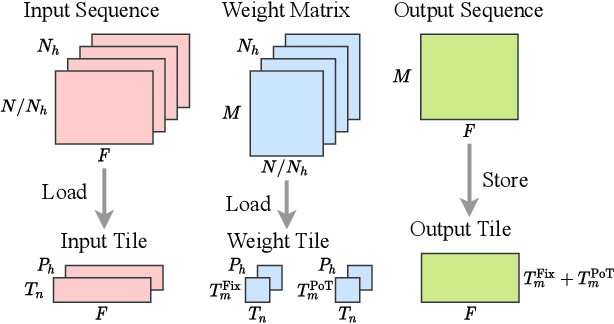
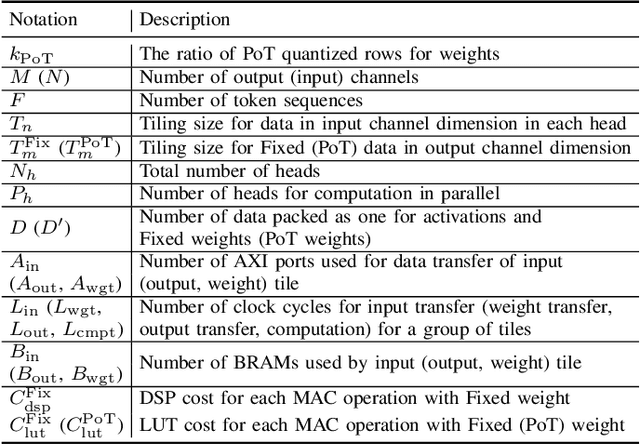
Vision transformers (ViTs) are emerging with significantly improved accuracy in computer vision tasks. However, their complex architecture and enormous computation/storage demand impose urgent needs for new hardware accelerator design methodology. This work proposes an FPGA-aware automatic ViT acceleration framework based on the proposed mixed-scheme quantization. To the best of our knowledge, this is the first FPGA-based ViT acceleration framework exploring model quantization. Compared with state-of-the-art ViT quantization work (algorithmic approach only without hardware acceleration), our quantization achieves 0.47% to 1.36% higher Top-1 accuracy under the same bit-width. Compared with the 32-bit floating-point baseline FPGA accelerator, our accelerator achieves around 5.6x improvement on the frame rate (i.e., 56.8 FPS vs. 10.0 FPS) with 0.71% accuracy drop on ImageNet dataset for DeiT-base.
Density-Aware Personalized Training for Risk Prediction in Imbalanced Medical Data
Jul 29, 2022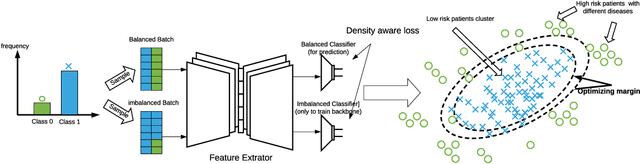

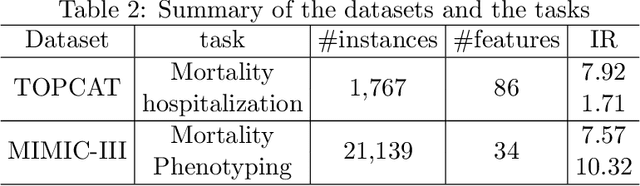
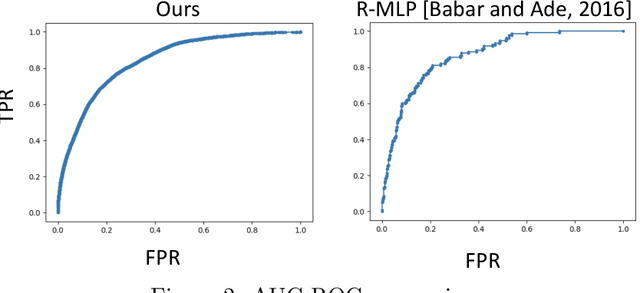
Medical events of interest, such as mortality, often happen at a low rate in electronic medical records, as most admitted patients survive. Training models with this imbalance rate (class density discrepancy) may lead to suboptimal prediction. Traditionally this problem is addressed through ad-hoc methods such as resampling or reweighting but performance in many cases is still limited. We propose a framework for training models for this imbalance issue: 1) we first decouple the feature extraction and classification process, adjusting training batches separately for each component to mitigate bias caused by class density discrepancy; 2) we train the network with both a density-aware loss and a learnable cost matrix for misclassifications. We demonstrate our model's improved performance in real-world medical datasets (TOPCAT and MIMIC-III) to show improved AUC-ROC, AUC-PRC, Brier Skill Score compared with the baselines in the domain.
Is Attention All NeRF Needs?
Jul 27, 2022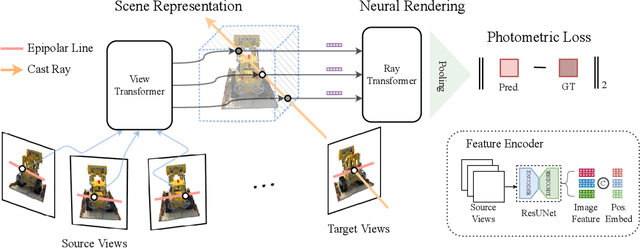
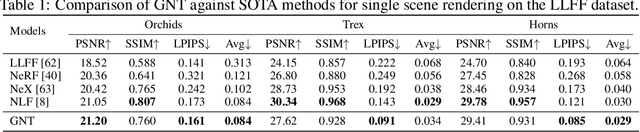
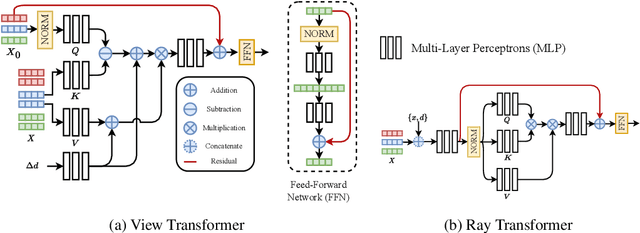
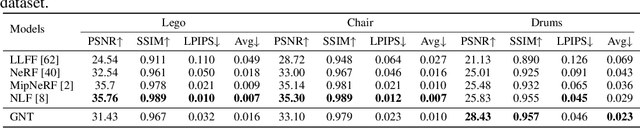
We present Generalizable NeRF Transformer (GNT), a pure, unified transformer-based architecture that efficiently reconstructs Neural Radiance Fields (NeRFs) on the fly from source views. Unlike prior works on NeRF that optimize a per-scene implicit representation by inverting a handcrafted rendering equation, GNT achieves generalizable neural scene representation and rendering, by encapsulating two transformer-based stages. The first stage of GNT, called view transformer, leverages multi-view geometry as an inductive bias for attention-based scene representation, and predicts coordinate-aligned features by aggregating information from epipolar lines on the neighboring views. The second stage of GNT, named ray transformer, renders novel views by ray marching and directly decodes the sequence of sampled point features using the attention mechanism. Our experiments demonstrate that when optimized on a single scene, GNT can successfully reconstruct NeRF without explicit rendering formula, and even improve the PSNR by ~1.3dB on complex scenes due to the learnable ray renderer. When trained across various scenes, GNT consistently achieves the state-of-the-art performance when transferring to forward-facing LLFF dataset (LPIPS ~20%, SSIM ~25%$) and synthetic blender dataset (LPIPS ~20%, SSIM ~4%). In addition, we show that depth and occlusion can be inferred from the learned attention maps, which implies that the pure attention mechanism is capable of learning a physically-grounded rendering process. All these results bring us one step closer to the tantalizing hope of utilizing transformers as the "universal modeling tool" even for graphics. Please refer to our project page for video results: https://vita-group.github.io/GNT/.
Single Frame Atmospheric Turbulence Mitigation: A Benchmark Study and A New Physics-Inspired Transformer Model
Jul 24, 2022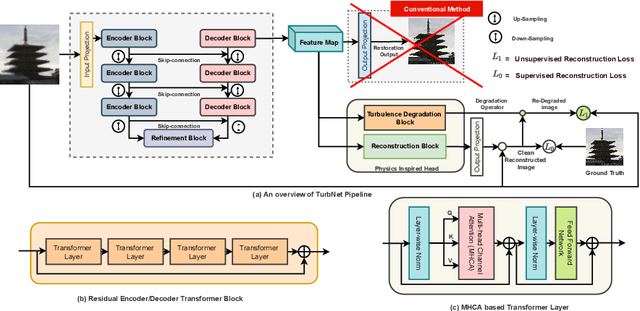
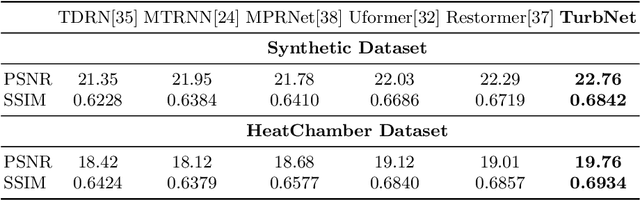
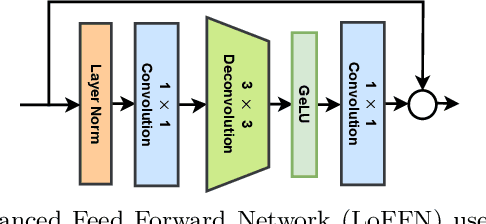

Image restoration algorithms for atmospheric turbulence are known to be much more challenging to design than traditional ones such as blur or noise because the distortion caused by the turbulence is an entanglement of spatially varying blur, geometric distortion, and sensor noise. Existing CNN-based restoration methods built upon convolutional kernels with static weights are insufficient to handle the spatially dynamical atmospheric turbulence effect. To address this problem, in this paper, we propose a physics-inspired transformer model for imaging through atmospheric turbulence. The proposed network utilizes the power of transformer blocks to jointly extract a dynamical turbulence distortion map and restore a turbulence-free image. In addition, recognizing the lack of a comprehensive dataset, we collect and present two new real-world turbulence datasets that allow for evaluation with both classical objective metrics (e.g., PSNR and SSIM) and a new task-driven metric using text recognition accuracy. Both real testing sets and all related code will be made publicly available.
Self-Supervised Learning of Echocardiogram Videos Enables Data-Efficient Clinical Diagnosis
Jul 23, 2022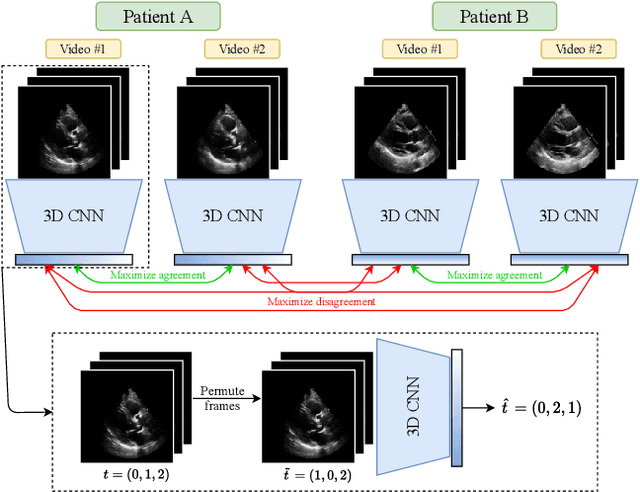
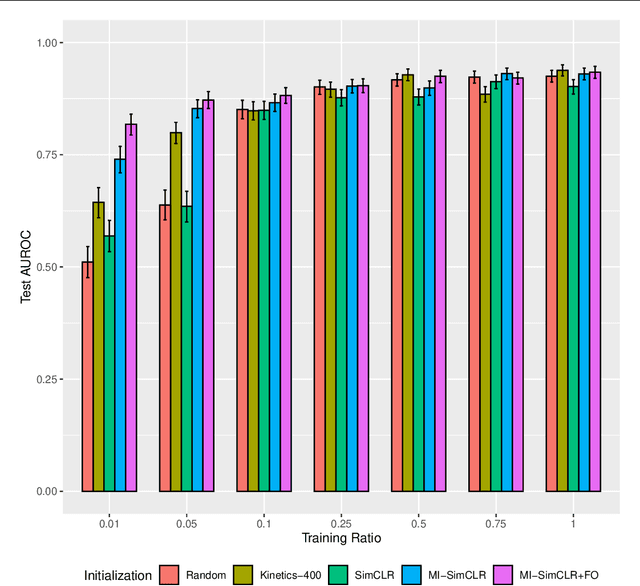
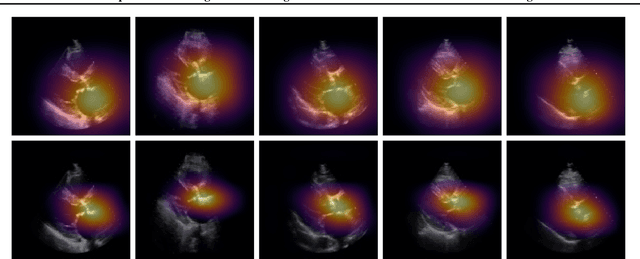
Given the difficulty of obtaining high-quality labels for medical image recognition tasks, there is a need for deep learning techniques that can be adequately fine-tuned on small labeled data sets. Recent advances in self-supervised learning techniques have shown that such an in-domain representation learning approach can provide a strong initialization for supervised fine-tuning, proving much more data-efficient than standard transfer learning from a supervised pretraining task. However, these applications are not adapted to applications to medical diagnostics captured in a video format. With this progress in mind, we developed a self-supervised learning approach catered to echocardiogram videos with the goal of learning strong representations for downstream fine-tuning on the task of diagnosing aortic stenosis (AS), a common and dangerous disease of the aortic valve. When fine-tuned on 1% of the training data, our best self-supervised learning model achieves 0.818 AUC (95% CI: 0.794, 0.840), while the standard transfer learning approach reaches 0.644 AUC (95% CI: 0.610, 0.677). We also find that our self-supervised model attends more closely to the aortic valve when predicting severe AS as demonstrated by saliency map visualizations.
Equivariant Hypergraph Diffusion Neural Operators
Jul 22, 2022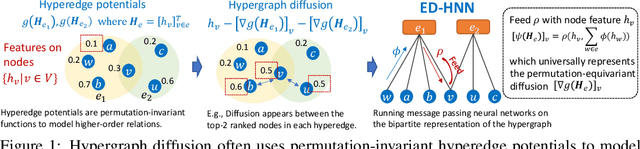

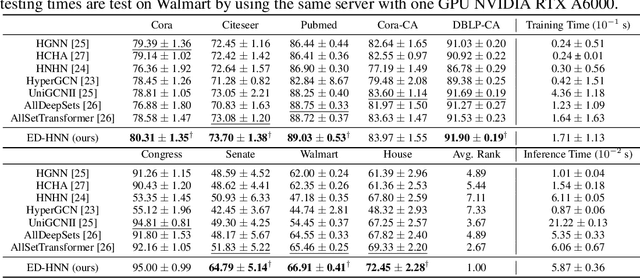
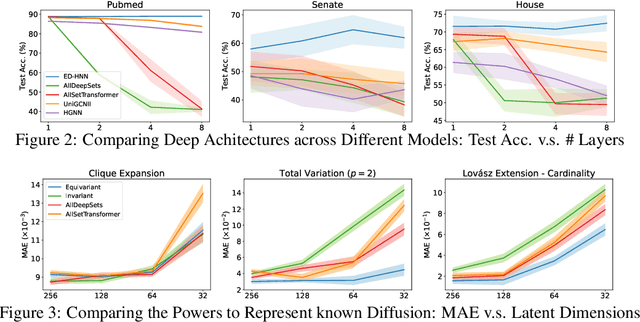
Hypergraph neural networks (HNNs) using neural networks to encode hypergraphs provide a promising way to model higher-order relations in data and further solve relevant prediction tasks built upon such higher-order relations. However, higher-order relations in practice contain complex patterns and are often highly irregular. So, it is often challenging to design an HNN that suffices to express those relations while keeping computational efficiency. Inspired by hypergraph diffusion algorithms, this work proposes a new HNN architecture named ED-HNN, which provably represents any continuous equivariant hypergraph diffusion operators that can model a wide range of higher-order relations. ED-HNN can be implemented efficiently by combining star expansions of hypergraphs with standard message passing neural networks. ED-HNN further shows great superiority in processing heterophilic hypergraphs and constructing deep models. We evaluate ED-HNN for node classification on nine real-world hypergraph datasets. ED-HNN uniformly outperforms the best baselines over these nine datasets and achieves more than 2\%$\uparrow$ in prediction accuracy over four datasets therein.
Radiomics-Guided Global-Local Transformer for Weakly Supervised Pathology Localization in Chest X-Rays
Jul 14, 2022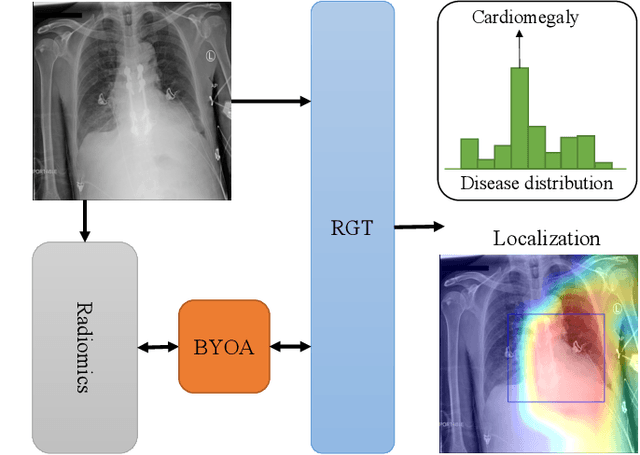
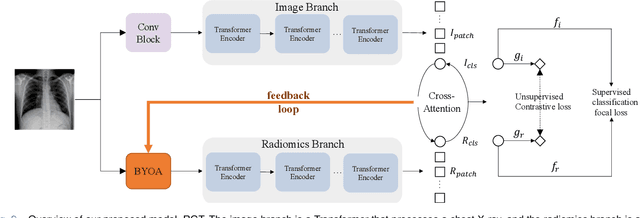

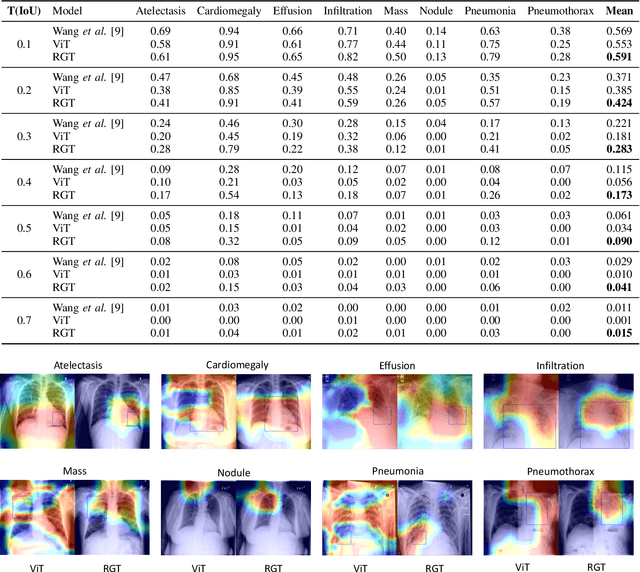
Before the recent success of deep learning methods for automated medical image analysis, practitioners used handcrafted radiomic features to quantitatively describe local patches of medical images. However, extracting discriminative radiomic features relies on accurate pathology localization, which is difficult to acquire in real-world settings. Despite advances in disease classification and localization from chest X-rays, many approaches fail to incorporate clinically-informed domain knowledge. For these reasons, we propose a Radiomics-Guided Transformer (RGT) that fuses \textit{global} image information with \textit{local} knowledge-guided radiomics information to provide accurate cardiopulmonary pathology localization and classification \textit{without any bounding box annotations}. RGT consists of an image Transformer branch, a radiomics Transformer branch, and fusion layers that aggregate image and radiomic information. Using the learned self-attention of its image branch, RGT extracts a bounding box for which to compute radiomic features, which are further processed by the radiomics branch; learned image and radiomic features are then fused and mutually interact via cross-attention layers. Thus, RGT utilizes a novel end-to-end feedback loop that can bootstrap accurate pathology localization only using image-level disease labels. Experiments on the NIH ChestXRay dataset demonstrate that RGT outperforms prior works in weakly supervised disease localization (by an average margin of 3.6\% over various intersection-over-union thresholds) and classification (by 1.1\% in average area under the receiver operating characteristic curve). We publicly release our codes and pre-trained models at \url{https://github.com/VITA-Group/chext}.
Neural Implicit Dictionary via Mixture-of-Expert Training
Jul 08, 2022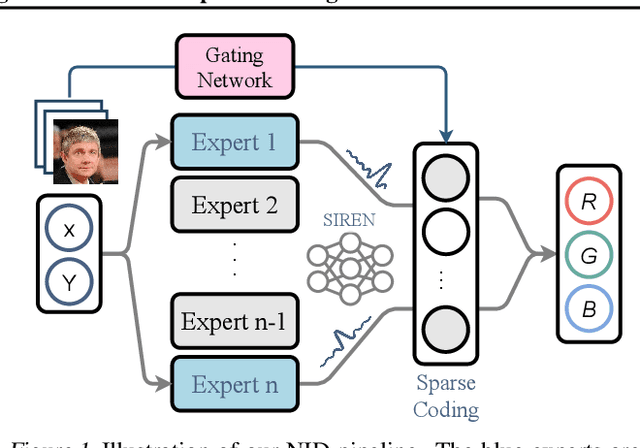
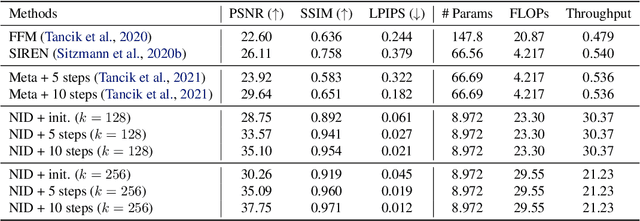

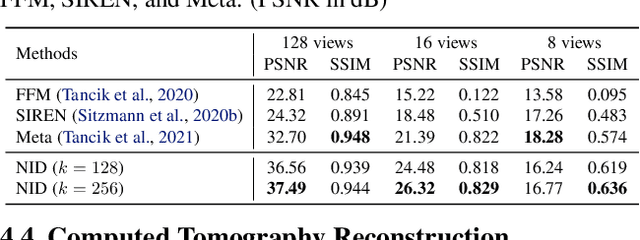
Representing visual signals by coordinate-based deep fully-connected networks has been shown advantageous in fitting complex details and solving inverse problems than discrete grid-based representation. However, acquiring such a continuous Implicit Neural Representation (INR) requires tedious per-scene training on tons of signal measurements, which limits its practicality. In this paper, we present a generic INR framework that achieves both data and training efficiency by learning a Neural Implicit Dictionary (NID) from a data collection and representing INR as a functional combination of basis sampled from the dictionary. Our NID assembles a group of coordinate-based subnetworks which are tuned to span the desired function space. After training, one can instantly and robustly acquire an unseen scene representation by solving the coding coefficients. To parallelly optimize a large group of networks, we borrow the idea from Mixture-of-Expert (MoE) to design and train our network with a sparse gating mechanism. Our experiments show that, NID can improve reconstruction of 2D images or 3D scenes by 2 orders of magnitude faster with up to 98% less input data. We further demonstrate various applications of NID in image inpainting and occlusion removal, which are considered to be challenging with vanilla INR. Our codes are available in https://github.com/VITA-Group/Neural-Implicit-Dict.
More ConvNets in the 2020s: Scaling up Kernels Beyond 51x51 using Sparsity
Jul 07, 2022
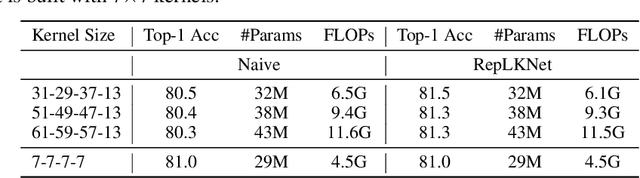
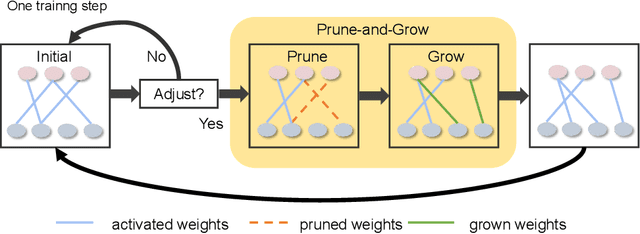
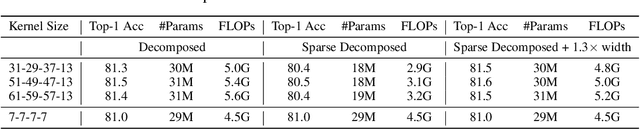
Transformers have quickly shined in the computer vision world since the emergence of Vision Transformers (ViTs). The dominant role of convolutional neural networks (CNNs) seems to be challenged by increasingly effective transformer-based models. Very recently, a couple of advanced convolutional models strike back with large kernels motivated by the local but large attention mechanism, showing appealing performance and efficiency. While one of them, i.e. RepLKNet, impressively manages to scale the kernel size to 31x31 with improved performance, the performance starts to saturate as the kernel size continues growing, compared to the scaling trend of advanced ViTs such as Swin Transformer. In this paper, we explore the possibility of training extreme convolutions larger than 31x31 and test whether the performance gap can be eliminated by strategically enlarging convolutions. This study ends up with a recipe for applying extremely large kernels from the perspective of sparsity, which can smoothly scale up kernels to 61x61 with better performance. Built on this recipe, we propose Sparse Large Kernel Network (SLaK), a pure CNN architecture equipped with 51x51 kernels that can perform on par with or better than state-of-the-art hierarchical Transformers and modern ConvNet architectures like ConvNeXt and RepLKNet, on ImageNet classification as well as typical downstream tasks. Our code is available here https://github.com/VITA-Group/SLaK.