 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBag of Tricks for Training Deeper Graph Neural Networks: A Comprehensive Benchmark Study
Paper and Code
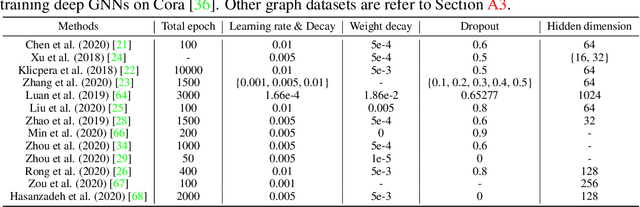
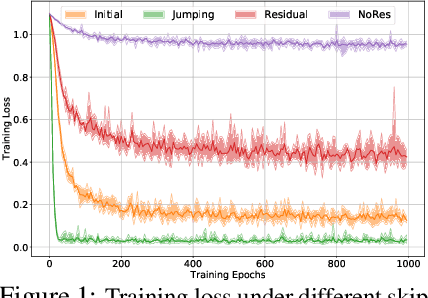

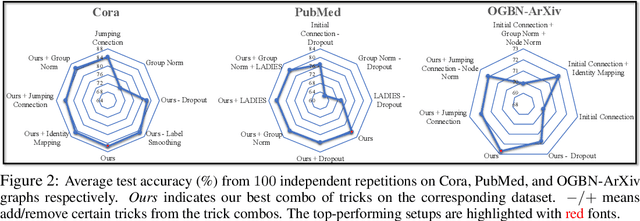
Training deep graph neural networks (GNNs) is notoriously hard. Besides the standard plights in training deep architectures such as vanishing gradients and overfitting, the training of deep GNNs also uniquely suffers from over-smoothing, information squashing, and so on, which limits their potential power on large-scale graphs. Although numerous efforts are proposed to address these limitations, such as various forms of skip connections, graph normalization, and random dropping, it is difficult to disentangle the advantages brought by a deep GNN architecture from those "tricks" necessary to train such an architecture. Moreover, the lack of a standardized benchmark with fair and consistent experimental settings poses an almost insurmountable obstacle to gauging the effectiveness of new mechanisms. In view of those, we present the first fair and reproducible benchmark dedicated to assessing the "tricks" of training deep GNNs. We categorize existing approaches, investigate their hyperparameter sensitivity, and unify the basic configuration. Comprehensive evaluations are then conducted on tens of representative graph datasets including the recent large-scale Open Graph Benchmark (OGB), with diverse deep GNN backbones. Based on synergistic studies, we discover the combo of superior training tricks, that lead us to attain the new state-of-the-art results for deep GCNs, across multiple representative graph datasets. We demonstrate that an organic combo of initial connection, identity mapping, group and batch normalization has the most ideal performance on large datasets. Experiments also reveal a number of "surprises" when combining or scaling up some of the tricks. All codes are available at https://github.com/VITA-Group/Deep_GCN_Benchmarking.