 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructVRM: Aligning Multimodal Reasoning with Structured and Verifiable Reward Models
Aug 07, 2025



Existing Vision-Language Models often struggle with complex, multi-question reasoning tasks where partial correctness is crucial for effective learning. Traditional reward mechanisms, which provide a single binary score for an entire response, are too coarse to guide models through intricate problems with multiple sub-parts. To address this, we introduce StructVRM, a method that aligns multimodal reasoning with Structured and Verifiable Reward Models. At its core is a model-based verifier trained to provide fine-grained, sub-question-level feedback, assessing semantic and mathematical equivalence rather than relying on rigid string matching. This allows for nuanced, partial credit scoring in previously intractable problem formats. Extensive experiments demonstrate the effectiveness of StructVRM. Our trained model, Seed-StructVRM, achieves state-of-the-art performance on six out of twelve public multimodal benchmarks and our newly curated, high-difficulty STEM-Bench. The success of StructVRM validates that training with structured, verifiable rewards is a highly effective approach for advancing the capabilities of multimodal models in complex, real-world reasoning domains.
AdaCoT: Pareto-Optimal Adaptive Chain-of-Thought Triggering via Reinforcement Learning
May 17, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities but often face challenges with tasks requiring sophisticated reasoning. While Chain-of-Thought (CoT) prompting significantly enhances reasoning, it indiscriminately generates lengthy reasoning steps for all queries, leading to substantial computational costs and inefficiency, especially for simpler inputs. To address this critical issue, we introduce AdaCoT (Adaptive Chain-of-Thought), a novel framework enabling LLMs to adaptively decide when to invoke CoT. AdaCoT framed adaptive reasoning as a Pareto optimization problem that seeks to balance model performance with the costs associated with CoT invocation (both frequency and computational overhead). We propose a reinforcement learning (RL) based method, specifically utilizing Proximal Policy Optimization (PPO), to dynamically control the CoT triggering decision boundary by adjusting penalty coefficients, thereby allowing the model to determine CoT necessity based on implicit query complexity. A key technical contribution is Selective Loss Masking (SLM), designed to counteract decision boundary collapse during multi-stage RL training, ensuring robust and stable adaptive triggering. Experimental results demonstrate that AdaCoT successfully navigates the Pareto frontier, achieving substantial reductions in CoT usage for queries not requiring elaborate reasoning. For instance, on our production traffic testset, AdaCoT reduced CoT triggering rates to as low as 3.18\% and decreased average response tokens by 69.06%, while maintaining high performance on complex tasks.
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
"Tom" pet robot applied to urban autism
May 14, 2019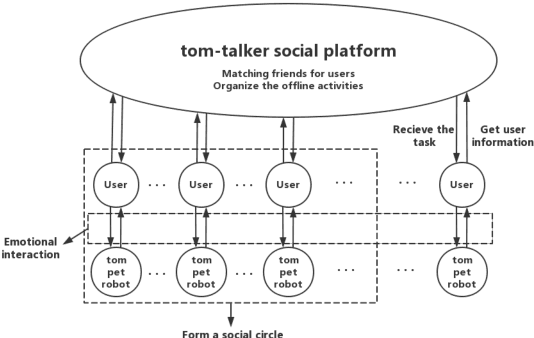
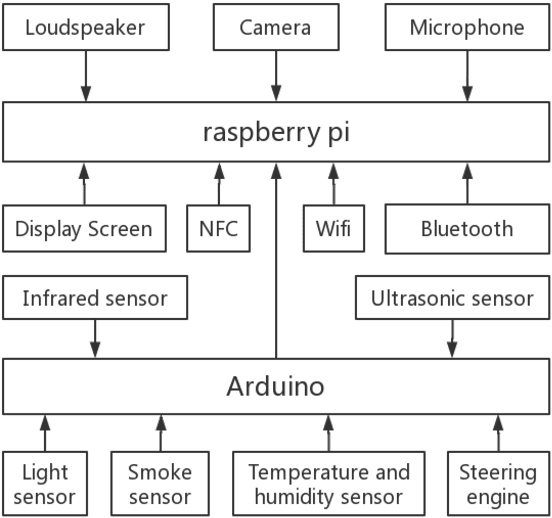
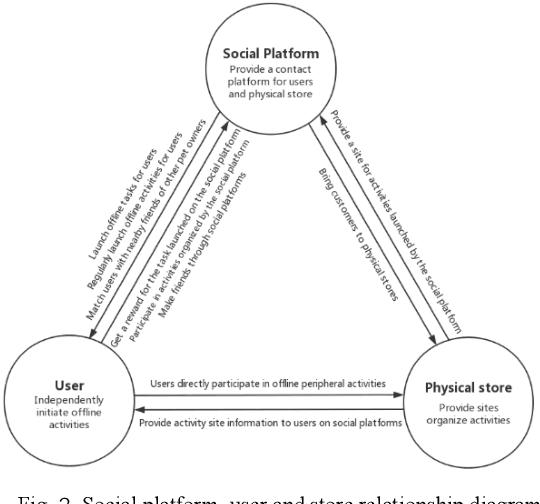
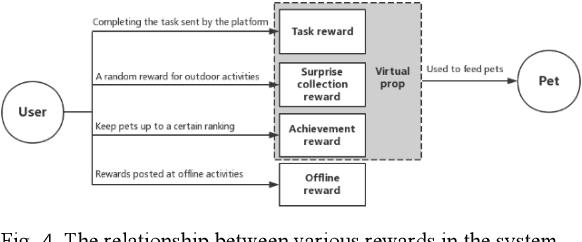
With the fast development of network information technology, more and more people are immersed in the virtual community environment brought by the network, ignoring the social interaction in real life. The consequent urban autism problem has become more and more serious. Promoting offline communication between people " and "eliminating loneliness through emotional communication between pet robots and breeders" to solve this problem, and has developed a design called "Tom". "Tom" is a smart pet robot with a pet robot-based social mechanism Called "Tom-Talker". The main contribution of this paper is to propose a social mechanism called "Tom-Talker" that encourages users to socialize offline. And "Tom-Talker" also has a corresponding reward mechanism and a friend recommendation algorithm. It also proposes a pet robot named "Tom" with an emotional interaction algorithm to recognize users' emotions, simulate animal emotions and communicate emotionally with use s. This paper designs experiments and analyzes the results. The results show that our pet robots have a good effect on solving urban autism problems.