 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbiased Diffusion Variational Inversion via Principled Posterior Matching
May 24, 2026Existing score-based methods for inverse problems often resort to approximate minimization of the KL divergence between the inversion distribution and the Bayesian posterior. Such an approximation leads to severe mode collapse and unreliable uncertainty quantification. In this paper, we propose Principled Posterior Matching (PPM), a framework that returns to the fundamentals of variational inference, rather than using tricky approximations. Instead of relying on heuristic approximations, we rigorously formulate the exact optimization of the KL divergence via the integration of Fisher divergence. We derive a tractable, equivalent gradient form of this integral, enabling precise optimization without the biases introduced by prior approximations. Our analysis clearly reveals that the mode collapse in previous methods stems directly from this approximation gap. Supported by our theoretical solution, PPM unifies two complementary paradigms: (1) In variational inference, PPM adopts mass-covering divergences that significantly improve the inversion diversity and uncertainty quantification; (2) In amortized inference, it enables the training of an efficient reconstruction network for rapid, single-step reconstruction. Furthermore, our formulation naturally extends to a broader family of divergence measures by generalizing the integral of the Fisher divergence. We validate PPM across challenging computational imaging tasks, including inpainting, super-resolution fluorescent microscopy, and radio interferometric black-hole imaging. In all experiments, PPM achieves superior reconstruction fidelity, faithful multimodal posterior recovery, and well-calibrated uncertainty estimates, establishing a robust framework for scientific imaging.
Autoregressive Visual Generation Needs a Prologue
May 07, 2026In this work, we propose Prologue, an approach to bridging the reconstruction-generation gap in autoregressive (AR) image generation. Instead of modifying visual tokens to satisfy both reconstruction and generation, Prologue generates a small set of prologue tokens prepended to the visual token sequence. These prologue tokens are trained exclusively with the AR cross-entropy (CE) loss, while visual tokens remain dedicated to reconstruction. This decoupled design lets us optimize generation through the AR model's true distribution without affecting reconstruction quality, which we further formalize from an ELBO perspective. On ImageNet 256x256, Prologue-Base reduces gFID from 21.01 to 10.75 without classifier-free guidance while keeping reconstruction almost unchanged; Prologue-Large reaches a competitive rFID of 0.99 and gFID of 1.46 using a standard AR model without auxiliary semantic supervision. Interestingly, driven only by AR gradients, prologue tokens exhibit emergent semantic structure: linear probing on 16 prologue tokens reaches 35.88% Top-1, far above the 23.71% of the first 16 tokens from a standard tokenizer; resampling with fixed prologue tokens preserves a similar high-level semantic layout. Our results suggest a new direction: generation quality can be improved by introducing a separate learned generative representation while leaving the original representation intact.
Taming the Entropy Cliff: Variable Codebook Size Quantization for Autoregressive Visual Generation
May 07, 2026Most discrete visual tokenizers rely on a default design: every position in the sequence shares the same codebook. Researchers try to scale the codebook size $K$ to get better reconstruction performance. Such a constant-codebook design hits a fundamental information-theoretic limit. We observe that the per-position conditional entropy of the training set decays so quickly along the sequence that, after a few positions, the conditional distribution becomes essentially deterministic. On ImageNet with $K=16384$, this happens within only 2 out of 256 positions, turning the remaining 254 into a memorization problem. We call this phenomenon the Entropy Cliff and formalize it with a simple expression: $t^{*} = \lceil \log_2 N / \log_2 K \rceil$. Interestingly, this phenomenon is not observed in language, as its natural structure keeps the effective entropy per position well below the codebook capacity. To address this, we propose Variable Codebook Size Quantization (VCQ), where the codebook size $K_t$ grows monotonically along the sequence from $K_{\min}=2$ to $K_{\max}$, leaving the loss function, parameter count, and AR training procedure unchanged. With a vanilla autoregressive Transformer and standard next-token prediction, a base version of VCQ reduces gFID w/o CFG from 27.98 to 14.80 on ImageNet $256\times256$ over the baseline. Scaled up, it reaches gFID 1.71 with 684M autoregressive parameters, without any extra training techniques such as semantic regularization or causal alignment. The extreme information bottleneck at $K_{\min}=2$ naturally induces a coarse-to-fine semantic hierarchy: a linear probe on only the first 10 tokens reaches 43.8% top-1 accuracy on ImageNet, compared to 27.1% for uniform codebooks. Ultimately, these results show that what matters is not only the total capacity of the codebook, but also how that capacity is distributed and organized.
Multimodal OCR: Parse Anything from Documents
Mar 13, 2026We present Multimodal OCR (MOCR), a document parsing paradigm that jointly parses text and graphics into unified textual representations. Unlike conventional OCR systems that focus on text recognition and leave graphical regions as cropped pixels, our method, termed dots.mocr, treats visual elements such as charts, diagrams, tables, and icons as first-class parsing targets, enabling systems to parse documents while preserving semantic relationships across elements. It offers several advantages: (1) it reconstructs both text and graphics as structured outputs, enabling more faithful document reconstruction; (2) it supports end-to-end training over heterogeneous document elements, allowing models to exploit semantic relations between textual and visual components; and (3) it converts previously discarded graphics into reusable code-level supervision, unlocking multimodal supervision embedded in existing documents. To make this paradigm practical at scale, we build a comprehensive data engine from PDFs, rendered webpages, and native SVG assets, and train a compact 3B-parameter model through staged pretraining and supervised fine-tuning. We evaluate dots.mocr from two perspectives: document parsing and structured graphics parsing. On document parsing benchmarks, it ranks second only to Gemini 3 Pro on our OCR Arena Elo leaderboard, surpasses existing open-source document parsing systems, and sets a new state of the art of 83.9 on olmOCR Bench. On structured graphics parsing, dots.mocr achieves higher reconstruction quality than Gemini 3 Pro across image-to-SVG benchmarks, demonstrating strong performance on charts, UI layouts, scientific figures, and chemical diagrams. These results show a scalable path toward building large-scale image-to-code corpora for multimodal pretraining. Code and models are publicly available at https://github.com/rednote-hilab/dots.mocr.
TDM-R1: Reinforcing Few-Step Diffusion Models with Non-Differentiable Reward
Mar 08, 2026While few-step generative models have enabled powerful image and video generation at significantly lower cost, generic reinforcement learning (RL) paradigms for few-step models remain an unsolved problem. Existing RL approaches for few-step diffusion models strongly rely on back-propagating through differentiable reward models, thereby excluding the majority of important real-world reward signals, e.g., non-differentiable rewards such as humans' binary likeness, object counts, etc. To properly incorporate non-differentiable rewards to improve few-step generative models, we introduce TDM-R1, a novel reinforcement learning paradigm built upon a leading few-step model, Trajectory Distribution Matching (TDM). TDM-R1 decouples the learning process into surrogate reward learning and generator learning. Furthermore, we developed practical methods to obtain per-step reward signals along the deterministic generation trajectory of TDM, resulting in a unified RL post-training method that significantly improves few-step models' ability with generic rewards. We conduct extensive experiments ranging from text-rendering, visual quality, and preference alignment. All results demonstrate that TDM-R1 is a powerful reinforcement learning paradigm for few-step text-to-image models, achieving state-of-the-art reinforcement learning performances on both in-domain and out-of-domain metrics. Furthermore, TDM-R1 also scales effectively to the recent strong Z-Image model, consistently outperforming both its 100-NFE and few-step variants with only 4 NFEs. Project page: https://github.com/Luo-Yihong/TDM-R1
ZeroDiff++: Substantial Unseen Visual-semantic Correlation in Zero-shot Learning
Feb 12, 2026Zero-shot Learning (ZSL) enables classifiers to recognize classes unseen during training, commonly via generative two stage methods: (1) learn visual semantic correlations from seen classes; (2) synthesize unseen class features from semantics to train classifiers. In this paper, we identify spurious visual semantic correlations in existing generative ZSL worsened by scarce seen class samples and introduce two metrics to quantify spuriousness for seen and unseen classes. Furthermore, we point out a more critical bottleneck: existing unadaptive fully noised generators produce features disconnected from real test samples, which also leads to the spurious correlation. To enhance the visual-semantic correlations on both seen and unseen classes, we propose ZeroDiff++, a diffusion-based generative framework. In training, ZeroDiff++ uses (i) diffusion augmentation to produce diverse noised samples, (ii) supervised contrastive (SC) representations for instance level semantics, and (iii) multi view discriminators with Wasserstein mutual learning to assess generated features. At generation time, we introduce (iv) Diffusion-based Test time Adaptation (DiffTTA) to adapt the generator using pseudo label reconstruction, and (v) Diffusion-based Test time Generation (DiffGen) to trace the diffusion denoising path and produce partially synthesized features that connect real and generated data, and mitigates data scarcity further. Extensive experiments on three ZSL benchmarks demonstrate that ZeroDiff++ not only achieves significant improvements over existing ZSL methods but also maintains robust performance even with scarce training data. Code would be available.
Ultra Fast PDE Solving via Physics Guided Few-step Diffusion
Feb 03, 2026Diffusion-based models have demonstrated impressive accuracy and generalization in solving partial differential equations (PDEs). However, they still face significant limitations, such as high sampling costs and insufficient physical consistency, stemming from their many-step iterative sampling mechanism and lack of explicit physics constraints. To address these issues, we propose Phys-Instruct, a novel physics-guided distillation framework which not only (1) compresses a pre-trained diffusion PDE solver into a few-step generator via matching generator and prior diffusion distributions to enable rapid sampling, but also (2) enhances the physics consistency by explicitly injecting PDE knowledge through a PDE distillation guidance. Physic-Instruct is built upon a solid theoretical foundation, leading to a practical physics-constrained training objective that admits tractable gradients. Across five PDE benchmarks, Phys-Instruct achieves orders-of-magnitude faster inference while reducing PDE error by more than 8 times compared to state-of-the-art diffusion baselines. Moreover, the resulting unconditional student model functions as a compact prior, enabling efficient and physically consistent inference for various downstream conditional tasks. Our results indicate that Phys-Instruct is a novel, effective, and efficient framework for ultra-fast PDE solving powered by deep generative models.
Masked Auto-Regressive Variational Acceleration: Fast Inference Makes Practical Reinforcement Learning
Nov 19, 2025Masked auto-regressive diffusion models (MAR) benefit from the expressive modeling ability of diffusion models and the flexibility of masked auto-regressive ordering. However, vanilla MAR suffers from slow inference due to its hierarchical inference mechanism: an outer AR unmasking loop and an inner diffusion denoising chain. Such decoupled structure not only harm the generation efficiency but also hinder the practical use of MAR for reinforcement learning (RL), an increasingly critical paradigm for generative model post-training.To address this fundamental issue, we introduce MARVAL (Masked Auto-regressive Variational Acceleration), a distillation-based framework that compresses the diffusion chain into a single AR generation step while preserving the flexible auto-regressive unmasking order. Such a distillation with MARVAL not only yields substantial inference acceleration but, crucially, makes RL post-training with verifiable rewards practical, resulting in scalable yet human-preferred fast generative models. Our contributions are twofold: (1) a novel score-based variational objective for distilling masked auto-regressive diffusion models into a single generation step without sacrificing sample quality; and (2) an efficient RL framework for masked auto-regressive models via MARVAL-RL. On ImageNet 256*256, MARVAL-Huge achieves an FID of 2.00 with more than 30 times speedup compared with MAR-diffusion, and MARVAL-RL yields consistent improvements in CLIP and image-reward scores on ImageNet datasets with entity names. In conclusion, MARVAL demonstrates the first practical path to distillation and RL of masked auto-regressive diffusion models, enabling fast sampling and better preference alignments.
Let Language Constrain Geometry: Vision-Language Models as Semantic and Spatial Critics for 3D Generation
Nov 18, 2025
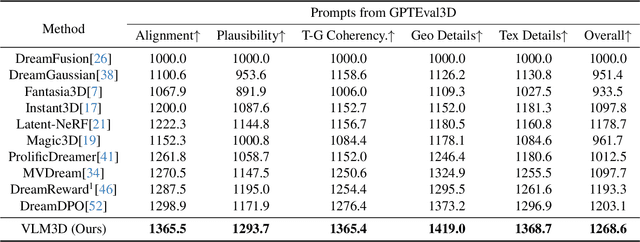
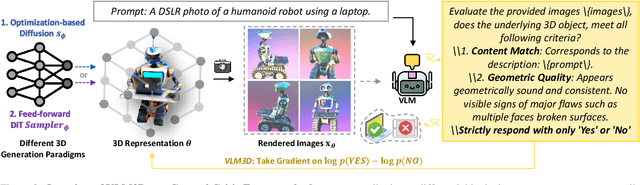
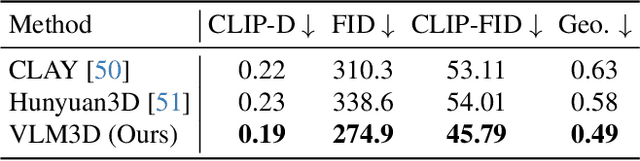
Text-to-3D generation has advanced rapidly, yet state-of-the-art models, encompassing both optimization-based and feed-forward architectures, still face two fundamental limitations. First, they struggle with coarse semantic alignment, often failing to capture fine-grained prompt details. Second, they lack robust 3D spatial understanding, leading to geometric inconsistencies and catastrophic failures in part assembly and spatial relationships. To address these challenges, we propose VLM3D, a general framework that repurposes large vision-language models (VLMs) as powerful, differentiable semantic and spatial critics. Our core contribution is a dual-query critic signal derived from the VLM's Yes or No log-odds, which assesses both semantic fidelity and geometric coherence. We demonstrate the generality of this guidance signal across two distinct paradigms: (1) As a reward objective for optimization-based pipelines, VLM3D significantly outperforms existing methods on standard benchmarks. (2) As a test-time guidance module for feed-forward pipelines, it actively steers the iterative sampling process of SOTA native 3D models to correct severe spatial errors. VLM3D establishes a principled and generalizable path to inject the VLM's rich, language-grounded understanding of both semantics and space into diverse 3D generative pipelines.
Vision-Language Models as Differentiable Semantic and Spatial Rewards for Text-to-3D Generation
Sep 19, 2025



Score Distillation Sampling (SDS) enables high-quality text-to-3D generation by supervising 3D models through the denoising of multi-view 2D renderings, using a pretrained text-to-image diffusion model to align with the input prompt and ensure 3D consistency. However, existing SDS-based methods face two fundamental limitations: (1) their reliance on CLIP-style text encoders leads to coarse semantic alignment and struggles with fine-grained prompts; and (2) 2D diffusion priors lack explicit 3D spatial constraints, resulting in geometric inconsistencies and inaccurate object relationships in multi-object scenes. To address these challenges, we propose VLM3D, a novel text-to-3D generation framework that integrates large vision-language models (VLMs) into the SDS pipeline as differentiable semantic and spatial priors. Unlike standard text-to-image diffusion priors, VLMs leverage rich language-grounded supervision that enables fine-grained prompt alignment. Moreover, their inherent vision language modeling provides strong spatial understanding, which significantly enhances 3D consistency for single-object generation and improves relational reasoning in multi-object scenes. We instantiate VLM3D based on the open-source Qwen2.5-VL model and evaluate it on the GPTeval3D benchmark. Experiments across diverse objects and complex scenes show that VLM3D significantly outperforms prior SDS-based methods in semantic fidelity, geometric coherence, and spatial correctness.