 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: Embodied AI Requires a Privacy-Utility Trade-off
May 06, 2026Embodied AI (EAI) systems are rapidly transitioning from simulations into real-world domestic and other sensitive environments. However, recent EAI solutions have largely demonstrated advancements within isolated stages such as instruction, perception, planning and interaction, without considering their coupled privacy implications in high-frequency deployments where privacy leakage is often irreversible. This position paper argues that optimizing these components independently creates a systemic privacy crisis when deployed in sensitive settings, thereby advancing the position that privacy in EAI is a life cycle-level architectural constraint rather than a stage-local feature. To address these challenges, we propose Secure Privacy Integration in Next-generation Embodied AI (SPINE), a unified privacy-aware framework that treats privacy as a dynamic control signal governing cross-stage coupling throughout the entire EAI life cycle. SPINE decomposes the EAI pipeline into various stages and establishes a multi-criterion privacy classification matrix to orchestrate contextual sensitivity across stage boundaries. We conduct preliminary simulation and real-world case studies to conceptually validate how privacy constraints propagate downstream to reshape system behavior, illustrating the insufficiency of fragmented privacy patches and motivating future research directions into secure yet functional embodied AI systems. We detail the SPINE framework and case studies at https://github.com/rminshen03/EAI_Privacy_Position.
Elastic Diffusion Transformer
Feb 15, 2026Diffusion Transformers (DiT) have demonstrated remarkable generative capabilities but remain highly computationally expensive. Previous acceleration methods, such as pruning and distillation, typically rely on a fixed computational capacity, leading to insufficient acceleration and degraded generation quality. To address this limitation, we propose \textbf{Elastic Diffusion Transformer (E-DiT)}, an adaptive acceleration framework for DiT that effectively improves efficiency while maintaining generation quality. Specifically, we observe that the generative process of DiT exhibits substantial sparsity (i.e., some computations can be skipped with minimal impact on quality), and this sparsity varies significantly across samples. Motivated by this observation, E-DiT equips each DiT block with a lightweight router that dynamically identifies sample-dependent sparsity from the input latent. Each router adaptively determines whether the corresponding block can be skipped. If the block is not skipped, the router then predicts the optimal MLP width reduction ratio within the block. During inference, we further introduce a block-level feature caching mechanism that leverages router predictions to eliminate redundant computations in a training-free manner. Extensive experiments across 2D image (Qwen-Image and FLUX) and 3D asset (Hunyuan3D-3.0) demonstrate the effectiveness of E-DiT, achieving up to $\sim$2$\times$ speedup with negligible loss in generation quality. Code will be available at https://github.com/wangjiangshan0725/Elastic-DiT.
Memory Assisted LLM for Personalized Recommendation System
May 03, 2025Large language models (LLMs) have demonstrated significant potential in solving recommendation tasks. With proven capabilities in understanding user preferences, LLM personalization has emerged as a critical area for providing tailored responses to individuals. Current studies explore personalization through prompt design and fine-tuning, paving the way for further research in personalized LLMs. However, existing approaches are either costly and inefficient in capturing diverse user preferences or fail to account for timely updates to user history. To address these gaps, we propose the Memory-Assisted Personalized LLM (MAP). Through user interactions, we first create a history profile for each user, capturing their preferences, such as ratings for historical items. During recommendation, we extract relevant memory based on similarity, which is then incorporated into the prompts to enhance personalized recommendations. In our experiments, we evaluate MAP using a sequential rating prediction task under two scenarios: single domain, where memory and tasks are from the same category (e.g., movies), and cross-domain (e.g., memory from movies and recommendation tasks in books). The results show that MAP outperforms regular LLM-based recommenders that integrate user history directly through prompt design. Moreover, as user history grows, MAP's advantage increases in both scenarios, making it more suitable for addressing successive personalized user requests.
Episodic Multi-agent Reinforcement Learning with Curiosity-Driven Exploration
Nov 22, 2021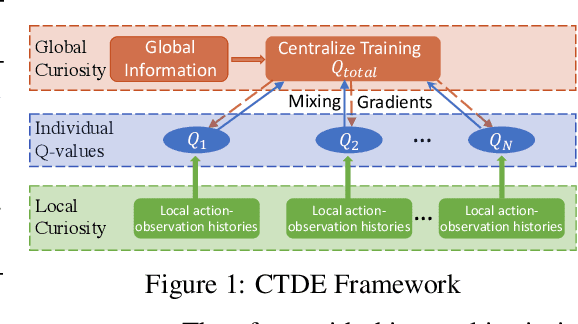
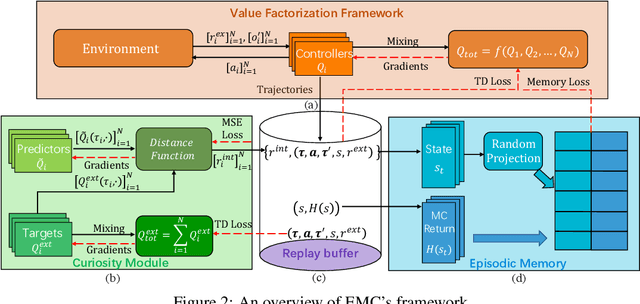

Efficient exploration in deep cooperative multi-agent reinforcement learning (MARL) still remains challenging in complex coordination problems. In this paper, we introduce a novel Episodic Multi-agent reinforcement learning with Curiosity-driven exploration, called EMC. We leverage an insight of popular factorized MARL algorithms that the "induced" individual Q-values, i.e., the individual utility functions used for local execution, are the embeddings of local action-observation histories, and can capture the interaction between agents due to reward backpropagation during centralized training. Therefore, we use prediction errors of individual Q-values as intrinsic rewards for coordinated exploration and utilize episodic memory to exploit explored informative experience to boost policy training. As the dynamics of an agent's individual Q-value function captures the novelty of states and the influence from other agents, our intrinsic reward can induce coordinated exploration to new or promising states. We illustrate the advantages of our method by didactic examples, and demonstrate its significant outperformance over state-of-the-art MARL baselines on challenging tasks in the StarCraft II micromanagement benchmark.