 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Unregistered Hyperspectral Image Super-Resolution via Unmixing-based Abundance Fusion Learning
Mar 09, 2026Unregistered hyperspectral image (HSI) super-resolution (SR) typically aims to enhance a low-resolution HSI using an unregistered high-resolution reference image. In this paper, we propose an unmixing-based fusion framework that decouples spatial-spectral information to simultaneously mitigate the impact of unregistered fusion and enhance the learnability of SR models. Specifically, we first utilize singular value decomposition for initial spectral unmixing, preserving the original endmembers while dedicating the subsequent network to enhancing the initial abundance map. To leverage the spatial texture of the unregistered reference, we introduce a coarse-to-fine deformable aggregation module, which first estimates a pixel-level flow and a similarity map using a coarse pyramid predictor. It further performs fine sub-pixel refinement to achieve deformable aggregation of the reference features. The aggregative features are then refined via a series of spatial-channel abundance cross-attention blocks. Furthermore, a spatial-channel modulated fusion module is presented to merge encoder-decoder features using dynamic gating weights, yielding a high-quality, high-resolution HSI. Experimental results on simulated and real datasets confirm that our proposed method achieves state-of-the-art super-resolution performance. The code will be available at https://github.com/yingkai-zhang/UAFL.
Supervise-assisted Multi-modality Fusion Diffusion Model for PET Restoration
Feb 12, 2026Positron emission tomography (PET) offers powerful functional imaging but involves radiation exposure. Efforts to reduce this exposure by lowering the radiotracer dose or scan time can degrade image quality. While using magnetic resonance (MR) images with clearer anatomical information to restore standard-dose PET (SPET) from low-dose PET (LPET) is a promising approach, it faces challenges with the inconsistencies in the structure and texture of multi-modality fusion, as well as the mismatch in out-of-distribution (OOD) data. In this paper, we propose a supervise-assisted multi-modality fusion diffusion model (MFdiff) for addressing these challenges for high-quality PET restoration. Firstly, to fully utilize auxiliary MR images without introducing extraneous details in the restored image, a multi-modality feature fusion module is designed to learn an optimized fusion feature. Secondly, using the fusion feature as an additional condition, high-quality SPET images are iteratively generated based on the diffusion model. Furthermore, we introduce a two-stage supervise-assisted learning strategy that harnesses both generalized priors from simulated in-distribution datasets and specific priors tailored to in-vivo OOD data. Experiments demonstrate that the proposed MFdiff effectively restores high-quality SPET images from multi-modality inputs and outperforms state-of-the-art methods both qualitatively and quantitatively.
Unaligned RGB Guided Hyperspectral Image Super-Resolution with Spatial-Spectral Concordance
May 04, 2025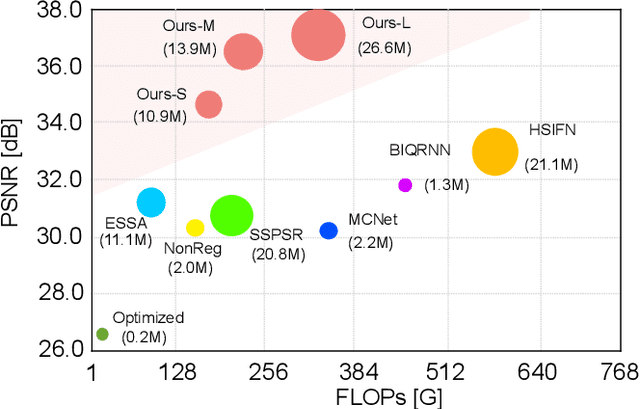
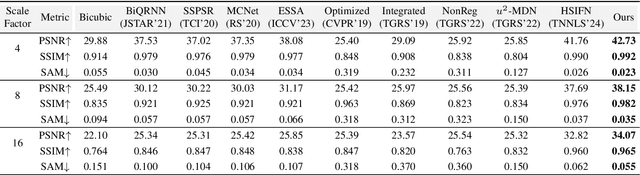
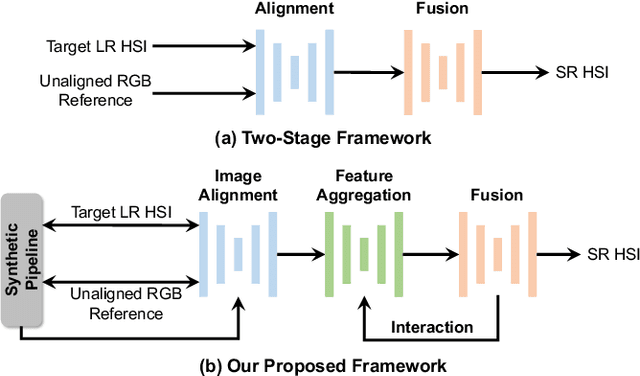
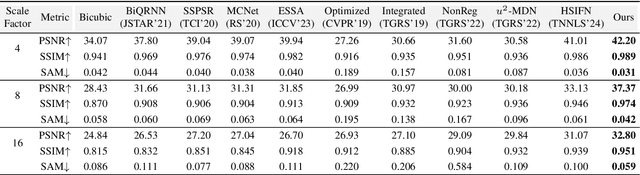
Hyperspectral images super-resolution aims to improve the spatial resolution, yet its performance is often limited at high-resolution ratios. The recent adoption of high-resolution reference images for super-resolution is driven by the poor spatial detail found in low-resolution HSIs, presenting it as a favorable method. However, these approaches cannot effectively utilize information from the reference image, due to the inaccuracy of alignment and its inadequate interaction between alignment and fusion modules. In this paper, we introduce a Spatial-Spectral Concordance Hyperspectral Super-Resolution (SSC-HSR) framework for unaligned reference RGB guided HSI SR to address the issues of inaccurate alignment and poor interactivity of the previous approaches. Specifically, to ensure spatial concordance, i.e., align images more accurately across resolutions and refine textures, we construct a Two-Stage Image Alignment with a synthetic generation pipeline in the image alignment module, where the fine-tuned optical flow model can produce a more accurate optical flow in the first stage and warp model can refine damaged textures in the second stage. To enhance the interaction between alignment and fusion modules and ensure spectral concordance during reconstruction, we propose a Feature Aggregation module and an Attention Fusion module. In the feature aggregation module, we introduce an Iterative Deformable Feature Aggregation block to achieve significant feature matching and texture aggregation with the fusion multi-scale results guidance, iteratively generating learnable offset. Besides, we introduce two basic spectral-wise attention blocks in the attention fusion module to model the inter-spectra interactions. Extensive experiments on three natural or remote-sensing datasets show that our method outperforms state-of-the-art approaches on both quantitative and qualitative evaluations.
Technique Report of CVPR 2024 PBDL Challenges
Jun 15, 2024



The intersection of physics-based vision and deep learning presents an exciting frontier for advancing computer vision technologies. By leveraging the principles of physics to inform and enhance deep learning models, we can develop more robust and accurate vision systems. Physics-based vision aims to invert the processes to recover scene properties such as shape, reflectance, light distribution, and medium properties from images. In recent years, deep learning has shown promising improvements for various vision tasks, and when combined with physics-based vision, these approaches can enhance the robustness and accuracy of vision systems. This technical report summarizes the outcomes of the Physics-Based Vision Meets Deep Learning (PBDL) 2024 challenge, held in CVPR 2024 workshop. The challenge consisted of eight tracks, focusing on Low-Light Enhancement and Detection as well as High Dynamic Range (HDR) Imaging. This report details the objectives, methodologies, and results of each track, highlighting the top-performing solutions and their innovative approaches.