 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThrough the PRISM: Preference Representation in Intermediate States of Video Diffusion Models
Jun 18, 2026Evaluating video generation with clean, pixel-based reward models disconnects evaluation from the noisy diffusion process and incurs massive VAE decoding costs. In this paper, we challenge this paradigm by asking a fundamental question: Can a powerful video generator inherently discriminate preferences directly from noisy latents? To answer this, we introduce \textbf{PRISM} (\textbf{P}reference \textbf{R}epresentation in \textbf{I}ntermediate \textbf{S}tates of Diffusion \textbf{M}odels). PRISM employs a lightweight Query-based Aggregation head with a frozen video diffusion backbone to decode preference signals from noisy latents. Surprisingly, PRISM not only achieves SOTA preference accuracy but also unlocks strong noise-robustness, which enables early-stage Best-of-$N$ sampling. This allows for filtering suboptimal candidates at the very beginning of denoising, drastically reducing computation while boosting video quality. We also reveal a strong positive correlation between a backbone's generative performance and its inherent evaluative power, enabling self-improving video backbones.
SBoRA: Low-Rank Adaptation with Regional Weight Updates
Jul 10, 2024



This paper introduces Standard Basis LoRA (SBoRA), a novel parameter-efficient fine-tuning approach for Large Language Models that builds upon the pioneering works of Low-Rank Adaptation (LoRA) and Orthogonal Adaptation. SBoRA further reduces the computational and memory requirements of LoRA while enhancing learning performance. By leveraging orthogonal standard basis vectors to initialize one of the low-rank matrices, either A or B, SBoRA enables regional weight updates and memory-efficient fine-tuning. This approach gives rise to two variants, SBoRA-FA and SBoRA-FB, where only one of the matrices is updated, resulting in a sparse update matrix with a majority of zero rows or columns. Consequently, the majority of the fine-tuned model's weights remain unchanged from the pre-trained weights. This characteristic of SBoRA, wherein regional weight updates occur, is reminiscent of the modular organization of the human brain, which efficiently adapts to new tasks. Our empirical results demonstrate the superiority of SBoRA-FA over LoRA in various fine-tuning tasks, including commonsense reasoning and arithmetic reasoning. Furthermore, we evaluate the effectiveness of QSBoRA on quantized LLaMA models of varying scales, highlighting its potential for efficient adaptation to new tasks. Code is available at https://github.com/cityuhkai/SBoRA
Interpretable Latent Variables in Deep State Space Models
Mar 03, 2022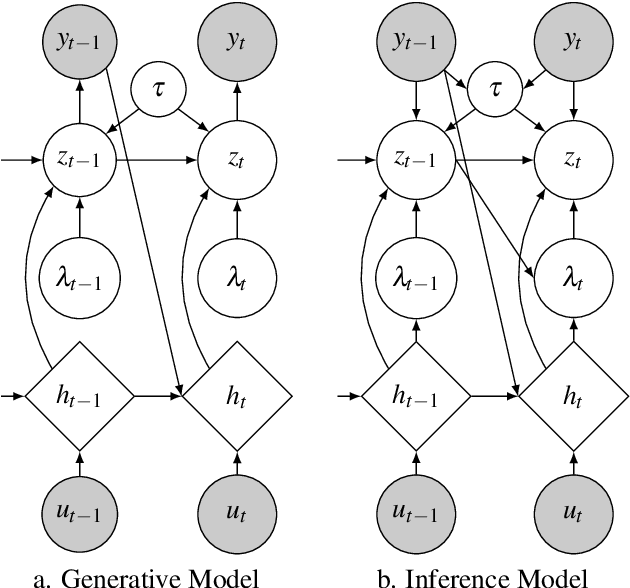
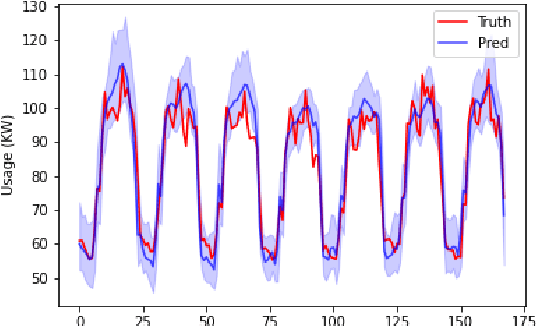
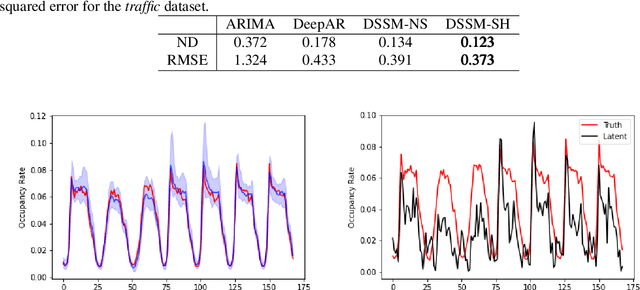
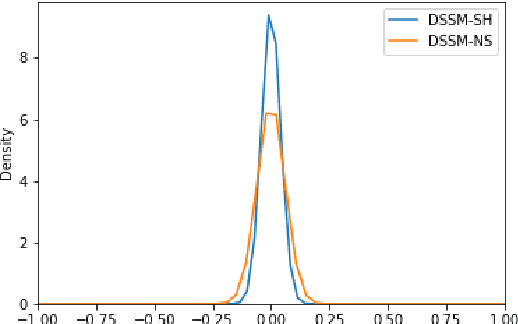
We introduce a new version of deep state-space models (DSSMs) that combines a recurrent neural network with a state-space framework to forecast time series data. The model estimates the observed series as functions of latent variables that evolve non-linearly through time. Due to the complexity and non-linearity inherent in DSSMs, previous works on DSSMs typically produced latent variables that are very difficult to interpret. Our paper focus on producing interpretable latent parameters with two key modifications. First, we simplify the predictive decoder by restricting the response variables to be a linear transformation of the latent variables plus some noise. Second, we utilize shrinkage priors on the latent variables to reduce redundancy and improve robustness. These changes make the latent variables much easier to understand and allow us to interpret the resulting latent variables as random effects in a linear mixed model. We show through two public benchmark datasets the resulting model improves forecasting performances.
A News-based Machine Learning Model for Adaptive Asset Pricing
Jun 13, 2021
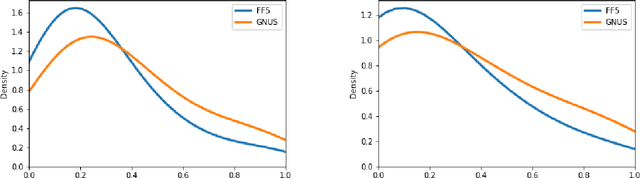
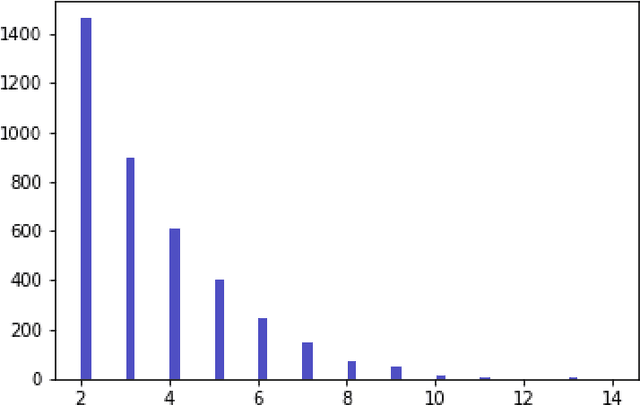
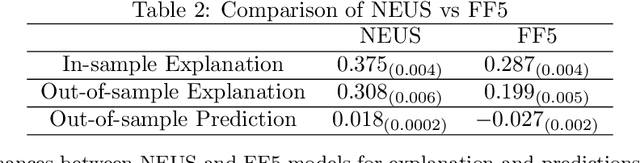
The paper proposes a new asset pricing model -- the News Embedding UMAP Selection (NEUS) model, to explain and predict the stock returns based on the financial news. Using a combination of various machine learning algorithms, we first derive a company embedding vector for each basis asset from the financial news. Then we obtain a collection of the basis assets based on their company embedding. After that for each stock, we select the basis assets to explain and predict the stock return with high-dimensional statistical methods. The new model is shown to have a significantly better fitting and prediction power than the Fama-French 5-factor model.