 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCL-VISTA: Benchmarking Continual Learning in Video Large Language Models
Apr 01, 2026Video Large Language Models (Video-LLMs) require continual learning to adapt to non-stationary real-world data. However, existing benchmarks fall short of evaluating modern foundation models: many still rely on models without large-scale pre-training, and prevailing benchmarks typically partition a single dataset into sub-tasks, resulting in high task redundancy and negligible forgetting on pre-trained Video-LLMs. To address these limitations, we propose CL-VISTA, a benchmark tailored for continual video understanding of Video-LLMs. By curating 8 diverse tasks spanning perception, understanding, and reasoning, CL-VISTA induces substantial distribution shifts that effectively expose catastrophic forgetting. To systematically assess CL methods, we establish a comprehensive evaluation framework comprising 6 distinct protocols across 3 critical dimensions: performance, computational efficiency, and memory footprint. Notably, the performance dimension incorporates a general video understanding assessment to assess whether CL methods genuinely enhance foundational intelligence or merely induce task-specific overfitting. Extensive benchmarking of 10 mainstream CL methods reveals a fundamental trade-off: no single approach achieves universal superiority across all dimensions. Methods that successfully mitigate catastrophic forgetting tend to compromise generalization or incur prohibitive computational and memory overheads. We hope CL-VISTA provides critical insights for advancing continual learning in multimodal foundation models.
ContextRL: Enhancing MLLM's Knowledge Discovery Efficiency with Context-Augmented RL
Feb 26, 2026We propose ContextRL, a novel framework that leverages context augmentation to overcome these bottlenecks. Specifically, to enhance Identifiability, we provide the reward model with full reference solutions as context, enabling fine-grained process verification to filter out false positives (samples with the right answer but low-quality reasoning process). To improve Reachability, we introduce a multi-turn sampling strategy where the reward model generates mistake reports for failed attempts, guiding the policy to "recover" correct responses from previously all-negative groups. Experimental results on 11 perception and reasoning benchmarks show that ContextRL significantly improves knowledge discovery efficiency. Notably, ContextRL enables the Qwen3-VL-8B model to achieve performance comparable to the 32B model, outperforming standard RLVR baselines by a large margin while effectively mitigating reward hacking. Our in-depth analysis reveals the significant potential of contextual information for improving reward model accuracy and document the widespread occurrence of reward hacking, offering valuable insights for future RLVR research.
VideoTemp-o3: Harmonizing Temporal Grounding and Video Understanding in Agentic Thinking-with-Videos
Feb 08, 2026In long-video understanding, conventional uniform frame sampling often fails to capture key visual evidence, leading to degraded performance and increased hallucinations. To address this, recent agentic thinking-with-videos paradigms have emerged, adopting a localize-clip-answer pipeline in which the model actively identifies relevant video segments, performs dense sampling within those clips, and then produces answers. However, existing methods remain inefficient, suffer from weak localization, and adhere to rigid workflows. To solve these issues, we propose VideoTemp-o3, a unified agentic thinking-with-videos framework that jointly models video grounding and question answering. VideoTemp-o3 exhibits strong localization capability, supports on-demand clipping, and can refine inaccurate localizations. Specifically, in the supervised fine-tuning stage, we design a unified masking mechanism that encourages exploration while preventing noise. For reinforcement learning, we introduce dedicated rewards to mitigate reward hacking. Besides, from the data perspective, we develop an effective pipeline to construct high-quality long video grounded QA data, along with a corresponding benchmark for systematic evaluation across various video durations. Experimental results demonstrate that our method achieves remarkable performance on both long video understanding and grounding.
AudioStory: Generating Long-Form Narrative Audio with Large Language Models
Aug 27, 2025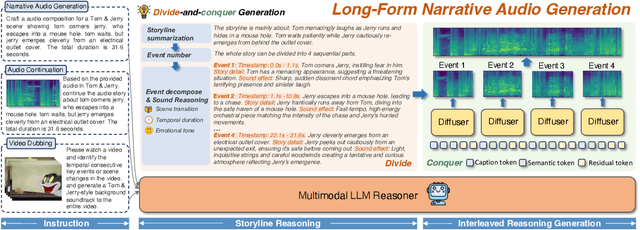
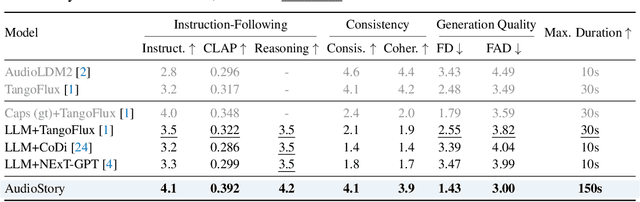
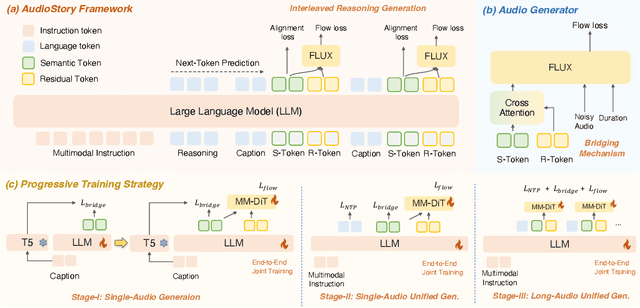

Recent advances in text-to-audio (TTA) generation excel at synthesizing short audio clips but struggle with long-form narrative audio, which requires temporal coherence and compositional reasoning. To address this gap, we propose AudioStory, a unified framework that integrates large language models (LLMs) with TTA systems to generate structured, long-form audio narratives. AudioStory possesses strong instruction-following reasoning generation capabilities. It employs LLMs to decompose complex narrative queries into temporally ordered sub-tasks with contextual cues, enabling coherent scene transitions and emotional tone consistency. AudioStory has two appealing features: (1) Decoupled bridging mechanism: AudioStory disentangles LLM-diffuser collaboration into two specialized components, i.e., a bridging query for intra-event semantic alignment and a residual query for cross-event coherence preservation. (2) End-to-end training: By unifying instruction comprehension and audio generation within a single end-to-end framework, AudioStory eliminates the need for modular training pipelines while enhancing synergy between components. Furthermore, we establish a benchmark AudioStory-10K, encompassing diverse domains such as animated soundscapes and natural sound narratives. Extensive experiments show the superiority of AudioStory on both single-audio generation and narrative audio generation, surpassing prior TTA baselines in both instruction-following ability and audio fidelity. Our code is available at https://github.com/TencentARC/AudioStory
MCITlib: Multimodal Continual Instruction Tuning Library and Benchmark
Aug 10, 2025Continual learning aims to equip AI systems with the ability to continuously acquire and adapt to new knowledge without forgetting previously learned information, similar to human learning. While traditional continual learning methods focusing on unimodal tasks have achieved notable success, the emergence of Multimodal Large Language Models has brought increasing attention to Multimodal Continual Learning tasks involving multiple modalities, such as vision and language. In this setting, models are expected to not only mitigate catastrophic forgetting but also handle the challenges posed by cross-modal interactions and coordination. To facilitate research in this direction, we introduce MCITlib, a comprehensive and constantly evolving code library for continual instruction tuning of Multimodal Large Language Models. In MCITlib, we have currently implemented 8 representative algorithms for Multimodal Continual Instruction Tuning and systematically evaluated them on 2 carefully selected benchmarks. MCITlib will be continuously updated to reflect advances in the Multimodal Continual Learning field. The codebase is released at https://github.com/Ghy0501/MCITlib.
A Comprehensive Survey on Continual Learning in Generative Models
Jun 16, 2025The rapid advancement of generative models has enabled modern AI systems to comprehend and produce highly sophisticated content, even achieving human-level performance in specific domains. However, these models remain fundamentally constrained by catastrophic forgetting - a persistent challenge where adapting to new tasks typically leads to significant degradation in performance on previously learned tasks. To address this practical limitation, numerous approaches have been proposed to enhance the adaptability and scalability of generative models in real-world applications. In this work, we present a comprehensive survey of continual learning methods for mainstream generative models, including large language models, multimodal large language models, vision language action models, and diffusion models. Drawing inspiration from the memory mechanisms of the human brain, we systematically categorize these approaches into three paradigms: architecture-based, regularization-based, and replay-based methods, while elucidating their underlying methodologies and motivations. We further analyze continual learning setups for different generative models, including training objectives, benchmarks, and core backbones, offering deeper insights into the field. The project page of this paper is available at https://github.com/Ghy0501/Awesome-Continual-Learning-in-Generative-Models.
Aligned Better, Listen Better for Audio-Visual Large Language Models
Apr 02, 2025



Audio is essential for multimodal video understanding. On the one hand, video inherently contains audio, which supplies complementary information to vision. Besides, video large language models (Video-LLMs) can encounter many audio-centric settings. However, existing Video-LLMs and Audio-Visual Large Language Models (AV-LLMs) exhibit deficiencies in exploiting audio information, leading to weak understanding and hallucinations. To solve the issues, we delve into the model architecture and dataset. (1) From the architectural perspective, we propose a fine-grained AV-LLM, namely Dolphin. The concurrent alignment of audio and visual modalities in both temporal and spatial dimensions ensures a comprehensive and accurate understanding of videos. Specifically, we devise an audio-visual multi-scale adapter for multi-scale information aggregation, which achieves spatial alignment. For temporal alignment, we propose audio-visual interleaved merging. (2) From the dataset perspective, we curate an audio-visual caption and instruction-tuning dataset, called AVU. It comprises 5.2 million diverse, open-ended data tuples (video, audio, question, answer) and introduces a novel data partitioning strategy. Extensive experiments show our model not only achieves remarkable performance in audio-visual understanding, but also mitigates potential hallucinations.
GenHancer: Imperfect Generative Models are Secretly Strong Vision-Centric Enhancers
Mar 25, 2025The synergy between generative and discriminative models receives growing attention. While discriminative Contrastive Language-Image Pre-Training (CLIP) excels in high-level semantics, it struggles with perceiving fine-grained visual details. Generally, to enhance representations, generative models take CLIP's visual features as conditions for reconstruction. However, the underlying principle remains underexplored. In this work, we empirically found that visually perfect generations are not always optimal for representation enhancement. The essence lies in effectively extracting fine-grained knowledge from generative models while mitigating irrelevant information. To explore critical factors, we delve into three aspects: (1) Conditioning mechanisms: We found that even a small number of local tokens can drastically reduce the difficulty of reconstruction, leading to collapsed training. We thus conclude that utilizing only global visual tokens as conditions is the most effective strategy. (2) Denoising configurations: We observed that end-to-end training introduces extraneous information. To address this, we propose a two-stage training strategy to prioritize learning useful visual knowledge. Additionally, we demonstrate that lightweight denoisers can yield remarkable improvements. (3) Generation paradigms: We explore both continuous and discrete denoisers with desirable outcomes, validating the versatility of our method. Through our in-depth explorations, we have finally arrived at an effective method, namely GenHancer, which consistently outperforms prior arts on the MMVP-VLM benchmark, e.g., 6.0% on OpenAICLIP. The enhanced CLIP can be further plugged into multimodal large language models for better vision-centric performance. All the models and codes are made publicly available.
Happy: A Debiased Learning Framework for Continual Generalized Category Discovery
Oct 10, 2024



Constantly discovering novel concepts is crucial in evolving environments. This paper explores the underexplored task of Continual Generalized Category Discovery (C-GCD), which aims to incrementally discover new classes from unlabeled data while maintaining the ability to recognize previously learned classes. Although several settings are proposed to study the C-GCD task, they have limitations that do not reflect real-world scenarios. We thus study a more practical C-GCD setting, which includes more new classes to be discovered over a longer period, without storing samples of past classes. In C-GCD, the model is initially trained on labeled data of known classes, followed by multiple incremental stages where the model is fed with unlabeled data containing both old and new classes. The core challenge involves two conflicting objectives: discover new classes and prevent forgetting old ones. We delve into the conflicts and identify that models are susceptible to prediction bias and hardness bias. To address these issues, we introduce a debiased learning framework, namely Happy, characterized by Hardness-aware prototype sampling and soft entropy regularization. For the prediction bias, we first introduce clustering-guided initialization to provide robust features. In addition, we propose soft entropy regularization to assign appropriate probabilities to new classes, which can significantly enhance the clustering performance of new classes. For the harness bias, we present the hardness-aware prototype sampling, which can effectively reduce the forgetting issue for previously seen classes, especially for difficult classes. Experimental results demonstrate our method proficiently manages the conflicts of C-GCD and achieves remarkable performance across various datasets, e.g., 7.5% overall gains on ImageNet-100. Our code is publicly available at https://github.com/mashijie1028/Happy-CGCD.
WPS-SAM: Towards Weakly-Supervised Part Segmentation with Foundation Models
Jul 14, 2024



Segmenting and recognizing diverse object parts is crucial in computer vision and robotics. Despite significant progress in object segmentation, part-level segmentation remains underexplored due to complex boundaries and scarce annotated data. To address this, we propose a novel Weakly-supervised Part Segmentation (WPS) setting and an approach called WPS-SAM, built on the large-scale pre-trained vision foundation model, Segment Anything Model (SAM). WPS-SAM is an end-to-end framework designed to extract prompt tokens directly from images and perform pixel-level segmentation of part regions. During its training phase, it only uses weakly supervised labels in the form of bounding boxes or points. Extensive experiments demonstrate that, through exploiting the rich knowledge embedded in pre-trained foundation models, WPS-SAM outperforms other segmentation models trained with pixel-level strong annotations. Specifically, WPS-SAM achieves 68.93% mIOU and 79.53% mACC on the PartImageNet dataset, surpassing state-of-the-art fully supervised methods by approximately 4% in terms of mIOU.