 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePokeVLA: Empowering Pocket-Sized Vision-Language-Action Model with Comprehensive World Knowledge Guidance
Apr 22, 2026Recent advances in Vision-Language-Action (VLA) models have opened new avenues for robot manipulation, yet existing methods exhibit limited efficiency and a lack of high-level knowledge and spatial awareness. To address these challenges, we propose PokeVLA, a lightweight yet powerful foundation model for embodied manipulation that effectively infuses vision-language understanding into action learning. Our framework introduces a two-stage training paradigm: first, we pre-train a compact vision-language model (PokeVLM) on a curated multimodal dataset of 2.4M samples encompassing spatial grounding, affordance, and embodied reasoning tasks; second, we inject manipulation-relevant representations into the action space through multi-view goal-aware semantics learning, geometry alignment, and a novel action expert. Extensive experiments demonstrate state-of-the-art performance on the LIBERO-Plus benchmark and in real-world deployment, outperforming comparable baselines in success rate and robustness under diverse perturbations. To foster reproducibility and community progress, we will open-source our code, model weights, and the scripts for the curated pre-training dataset. Project page: https://getterupper.github.io/PokeVLA
OneVL: One-Step Latent Reasoning and Planning with Vision-Language Explanation
Apr 20, 2026Chain-of-Thought (CoT) reasoning has become a powerful driver of trajectory prediction in VLA-based autonomous driving, yet its autoregressive nature imposes a latency cost that is prohibitive for real-time deployment. Latent CoT methods attempt to close this gap by compressing reasoning into continuous hidden states, but consistently fall short of their explicit counterparts. We suggest that this is due to purely linguistic latent representations compressing a symbolic abstraction of the world, rather than the causal dynamics that actually govern driving. Thus, we present OneVL (One-step latent reasoning and planning with Vision-Language explanations), a unified VLA and World Model framework that routes reasoning through compact latent tokens supervised by dual auxiliary decoders. Alongside a language decoder that reconstructs text CoT, we introduce a visual world model decoder that predicts future-frame tokens, forcing the latent space to internalize the causal dynamics of road geometry, agent motion, and environmental change. A three-stage training pipeline progressively aligns these latents with trajectory, language, and visual objectives, ensuring stable joint optimization. At inference, the auxiliary decoders are discarded and all latent tokens are prefilled in a single parallel pass, matching the speed of answer-only prediction. Across four benchmarks, OneVL becomes the first latent CoT method to surpass explicit CoT, delivering state-of-the-art accuracy at answer-only latency, and providing direct evidence that tighter compression, when guided in both language and world-model supervision, produces more generalizable representations than verbose token-by-token reasoning. Project Page: https://xiaomi-embodied-intelligence.github.io/OneVL
PerlAD: Towards Enhanced Closed-loop End-to-end Autonomous Driving with Pseudo-simulation-based Reinforcement Learning
Mar 16, 2026End-to-end autonomous driving policies based on Imitation Learning (IL) often struggle in closed-loop execution due to the misalignment between inadequate open-loop training objectives and real driving requirements. While Reinforcement Learning (RL) offers a solution by directly optimizing driving goals via reward signals, the rendering-based training environments introduce the rendering gap and are inefficient due to high computational costs. To overcome these challenges, we present a novel Pseudo-simulation-based RL method for closed-loop end-to-end autonomous driving, PerlAD. Based on offline datasets, PerlAD constructs a pseudo-simulation that operates in vector space, enabling efficient, rendering-free trial-and-error training. To bridge the gap between static datasets and dynamic closed-loop environments, PerlAD introduces a prediction world model that generates reactive agent trajectories conditioned on the ego vehicle's plan. Furthermore, to facilitate efficient planning, PerlAD utilizes a hierarchical decoupled planner that combines IL for lateral path generation and RL for longitudinal speed optimization. Comprehensive experimental results demonstrate that PerlAD achieves state-of-the-art performance on the Bench2Drive benchmark, surpassing the previous E2E RL method by 10.29% in Driving Score without requiring expensive online interactions. Additional evaluations on the DOS benchmark further confirm its reliability in handling safety-critical occlusion scenarios.
Learning from Mistakes: Post-Training for Driving VLA with Takeover Data
Mar 16, 2026Current Vision-Language-Action (VLA) paradigms in end-to-end autonomous driving rely on offline training from static datasets, leaving them vulnerable to distribution shift. Recent post-training methods use takeover data to mitigate this by augmenting the dataset with high-quality expert takeover samples, yet they suffer from two key limitations: supervision restricted to the period after the takeover moments leads to policies with limited safety margins, and passive preference optimization lacks active exploration for optimal performance. In this paper, we propose TakeVLA, a novel VLA post-training framework that overcomes these shortcomings through two complementary innovations. First, we introduce pre-takeover language supervision, which allows the VLA to learn from mistakes proactively. By explicitly teaching the model about what to do in error-prone situations, we cultivate a precautionary mindset that anticipates hazards early and substantially enlarges safety margins. Second, we propose Scenario Dreaming, a reinforcement fine-tuning paradigm that operates in reconstruceted takeover scenarios, encouraging active exploration beyond mere preference fitting. Experiments on the Bench2Drive benchmark demonstrate that TakeVLA achieves state-of-the-art closed-loop performance, surpassing the strong VLA baseline SimLingo by 4.93 in driving score, with an enhanced safety margin as evidenced by an 11.76% increase in average TTC.
WorldRFT: Latent World Model Planning with Reinforcement Fine-Tuning for Autonomous Driving
Dec 22, 2025Latent World Models enhance scene representation through temporal self-supervised learning, presenting a perception annotation-free paradigm for end-to-end autonomous driving. However, the reconstruction-oriented representation learning tangles perception with planning tasks, leading to suboptimal optimization for planning. To address this challenge, we propose WorldRFT, a planning-oriented latent world model framework that aligns scene representation learning with planning via a hierarchical planning decomposition and local-aware interactive refinement mechanism, augmented by reinforcement learning fine-tuning (RFT) to enhance safety-critical policy performance. Specifically, WorldRFT integrates a vision-geometry foundation model to improve 3D spatial awareness, employs hierarchical planning task decomposition to guide representation optimization, and utilizes local-aware iterative refinement to derive a planning-oriented driving policy. Furthermore, we introduce Group Relative Policy Optimization (GRPO), which applies trajectory Gaussianization and collision-aware rewards to fine-tune the driving policy, yielding systematic improvements in safety. WorldRFT achieves state-of-the-art (SOTA) performance on both open-loop nuScenes and closed-loop NavSim benchmarks. On nuScenes, it reduces collision rates by 83% (0.30% -> 0.05%). On NavSim, using camera-only sensors input, it attains competitive performance with the LiDAR-based SOTA method DiffusionDrive (87.8 vs. 88.1 PDMS).
TakeAD: Preference-based Post-optimization for End-to-end Autonomous Driving with Expert Takeover Data
Dec 22, 2025



Existing end-to-end autonomous driving methods typically rely on imitation learning (IL) but face a key challenge: the misalignment between open-loop training and closed-loop deployment. This misalignment often triggers driver-initiated takeovers and system disengagements during closed-loop execution. How to leverage those expert takeover data from disengagement scenarios and effectively expand the IL policy's capability presents a valuable yet unexplored challenge. In this paper, we propose TakeAD, a novel preference-based post-optimization framework that fine-tunes the pre-trained IL policy with this disengagement data to enhance the closed-loop driving performance. First, we design an efficient expert takeover data collection pipeline inspired by human takeover mechanisms in real-world autonomous driving systems. Then, this post optimization framework integrates iterative Dataset Aggregation (DAgger) for imitation learning with Direct Preference Optimization (DPO) for preference alignment. The DAgger stage equips the policy with fundamental capabilities to handle disengagement states through direct imitation of expert interventions. Subsequently, the DPO stage refines the policy's behavior to better align with expert preferences in disengagement scenarios. Through multiple iterations, the policy progressively learns recovery strategies for disengagement states, thereby mitigating the open-loop gap. Experiments on the closed-loop Bench2Drive benchmark demonstrate our method's effectiveness compared with pure IL methods, with comprehensive ablations confirming the contribution of each component.
ReasonPlan: Unified Scene Prediction and Decision Reasoning for Closed-loop Autonomous Driving
May 26, 2025Due to the powerful vision-language reasoning and generalization abilities, multimodal large language models (MLLMs) have garnered significant attention in the field of end-to-end (E2E) autonomous driving. However, their application to closed-loop systems remains underexplored, and current MLLM-based methods have not shown clear superiority to mainstream E2E imitation learning approaches. In this work, we propose ReasonPlan, a novel MLLM fine-tuning framework designed for closed-loop driving through holistic reasoning with a self-supervised Next Scene Prediction task and supervised Decision Chain-of-Thought process. This dual mechanism encourages the model to align visual representations with actionable driving context, while promoting interpretable and causally grounded decision making. We curate a planning-oriented decision reasoning dataset, namely PDR, comprising 210k diverse and high-quality samples. Our method outperforms the mainstream E2E imitation learning method by a large margin of 19% L2 and 16.1 driving score on Bench2Drive benchmark. Furthermore, ReasonPlan demonstrates strong zero-shot generalization on unseen DOS benchmark, highlighting its adaptability in handling zero-shot corner cases. Code and dataset will be found in https://github.com/Liuxueyi/ReasonPlan.
Dream to Drive with Predictive Individual World Model
Jan 28, 2025



It is still a challenging topic to make reactive driving behaviors in complex urban environments as road users' intentions are unknown. Model-based reinforcement learning (MBRL) offers great potential to learn a reactive policy by constructing a world model that can provide informative states and imagination training. However, a critical limitation in relevant research lies in the scene-level reconstruction representation learning, which may overlook key interactive vehicles and hardly model the interactive features among vehicles and their long-term intentions. Therefore, this paper presents a novel MBRL method with a predictive individual world model (PIWM) for autonomous driving. PIWM describes the driving environment from an individual-level perspective and captures vehicles' interactive relations and their intentions via trajectory prediction task. Meanwhile, a behavior policy is learned jointly with PIWM. It is trained in PIWM's imagination and effectively navigates in the urban driving scenes leveraging intention-aware latent states. The proposed method is trained and evaluated on simulation environments built upon real-world challenging interactive scenarios. Compared with popular model-free and state-of-the-art model-based reinforcement learning methods, experimental results show that the proposed method achieves the best performance in terms of safety and efficiency.
TrajGen: Generating Realistic and Diverse Trajectories with Reactive and Feasible Agent Behaviors for Autonomous Driving
Mar 31, 2022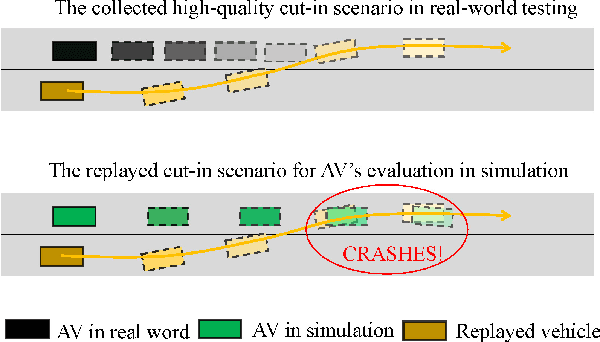
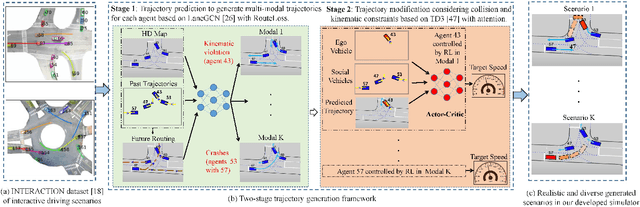
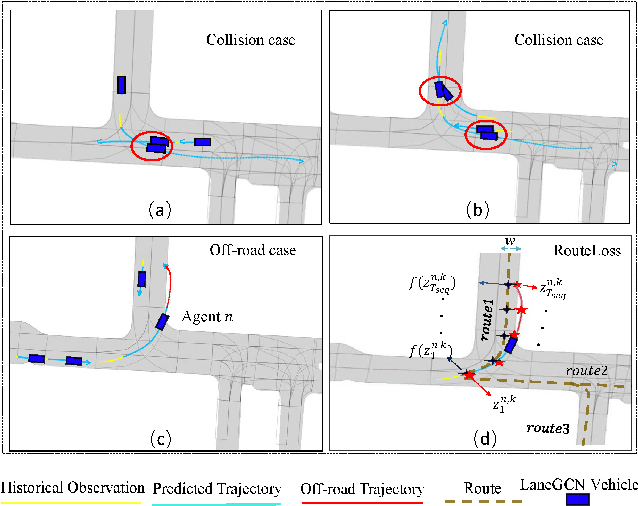
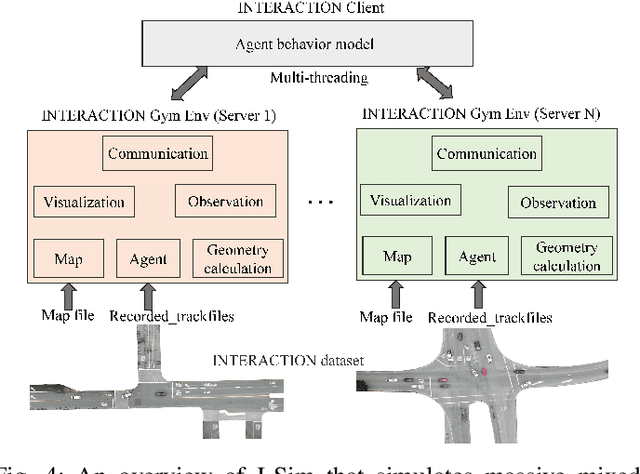
Realistic and diverse simulation scenarios with reactive and feasible agent behaviors can be used for validation and verification of self-driving system performance without relying on expensive and time-consuming real-world testing. Existing simulators rely on heuristic-based behavior models for background vehicles, which cannot capture the complex interactive behaviors in real-world scenarios. To bridge the gap between simulation and the real world, we propose TrajGen, a two-stage trajectory generation framework, which can capture more realistic behaviors directly from human demonstration. In particular, TrajGen consists of the multi-modal trajectory prediction stage and the reinforcement learning based trajectory modification stage. In the first stage, we propose a novel auxiliary RouteLoss for the trajectory prediction model to generate multi-modal diverse trajectories in the drivable area. In the second stage, reinforcement learning is used to track the predicted trajectories while avoiding collisions, which can improve the feasibility of generated trajectories. In addition, we develop a data-driven simulator I-Sim that can be used to train reinforcement learning models in parallel based on naturalistic driving data. The vehicle model in I-Sim can guarantee that the generated trajectories by TrajGen satisfy vehicle kinematic constraints. Finally, we give comprehensive metrics to evaluate generated trajectories for simulation scenarios, which shows that TrajGen outperforms either trajectory prediction or inverse reinforcement learning in terms of fidelity, reactivity, feasibility, and diversity.