 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Backdoor Attack on VLMs for Autonomous Driving via Graffiti and Cross-Lingual Triggers
Apr 06, 2026Visual language model (VLM) is rapidly being integrated into safety-critical systems such as autonomous driving, making it an important attack surface for potential backdoor attacks. Existing backdoor attacks mainly rely on unimodal, explicit, and easily detectable triggers, making it difficult to construct both covert and stable attack channels in autonomous driving scenarios. GLA introduces two naturalistic triggers: graffiti-based visual patterns generated via stable diffusion inpainting, which seamlessly blend into urban scenes, and cross-language text triggers, which introduce distributional shifts while maintaining semantic consistency to build robust language-side trigger signals. Experiments on DriveVLM show that GLA requires only a 10\% poisoning ratio to achieve a 90\% Attack Success Rate (ASR) and a 0\% False Positive Rate (FPR). More insidiously, the backdoor does not weaken the model on clean tasks, but instead improves metrics such as BLEU-1, making it difficult for traditional performance-degradation-based detection methods to identify the attack. This study reveals underestimated security threats in self-driving VLMs and provides a new attack paradigm for backdoor evaluation in safety-critical multimodal systems.
UniMLVG: Unified Framework for Multi-view Long Video Generation with Comprehensive Control Capabilities for Autonomous Driving
Dec 06, 2024The creation of diverse and realistic driving scenarios has become essential to enhance perception and planning capabilities of the autonomous driving system. However, generating long-duration, surround-view consistent driving videos remains a significant challenge. To address this, we present UniMLVG, a unified framework designed to generate extended street multi-perspective videos under precise control. By integrating single- and multi-view driving videos into the training data, our approach updates cross-frame and cross-view modules across three stages with different training objectives, substantially boosting the diversity and quality of generated visual content. Additionally, we employ the explicit viewpoint modeling in multi-view video generation to effectively improve motion transition consistency. Capable of handling various input reference formats (e.g., text, images, or video), our UniMLVG generates high-quality multi-view videos according to the corresponding condition constraints such as 3D bounding boxes or frame-level text descriptions. Compared to the best models with similar capabilities, our framework achieves improvements of 21.4% in FID and 36.5% in FVD.
Cross-Block Fine-Grained Semantic Cascade for Skeleton-Based Sports Action Recognition
Apr 30, 2024Human action video recognition has recently attracted more attention in applications such as video security and sports posture correction. Popular solutions, including graph convolutional networks (GCNs) that model the human skeleton as a spatiotemporal graph, have proven very effective. GCNs-based methods with stacked blocks usually utilize top-layer semantics for classification/annotation purposes. Although the global features learned through the procedure are suitable for the general classification, they have difficulty capturing fine-grained action change across adjacent frames -- decisive factors in sports actions. In this paper, we propose a novel ``Cross-block Fine-grained Semantic Cascade (CFSC)'' module to overcome this challenge. In summary, the proposed CFSC progressively integrates shallow visual knowledge into high-level blocks to allow networks to focus on action details. In particular, the CFSC module utilizes the GCN feature maps produced at different levels, as well as aggregated features from proceeding levels to consolidate fine-grained features. In addition, a dedicated temporal convolution is applied at each level to learn short-term temporal features, which will be carried over from shallow to deep layers to maximize the leverage of low-level details. This cross-block feature aggregation methodology, capable of mitigating the loss of fine-grained information, has resulted in improved performance. Last, FD-7, a new action recognition dataset for fencing sports, was collected and will be made publicly available. Experimental results and empirical analysis on public benchmarks (FSD-10) and self-collected (FD-7) demonstrate the advantage of our CFSC module on learning discriminative patterns for action classification over others.
Embedded Representation Learning Network for Animating Styled Video Portrait
Apr 29, 2024



The talking head generation recently attracted considerable attention due to its widespread application prospects, especially for digital avatars and 3D animation design. Inspired by this practical demand, several works explored Neural Radiance Fields (NeRF) to synthesize the talking heads. However, these methods based on NeRF face two challenges: (1) Difficulty in generating style-controllable talking heads. (2) Displacement artifacts around the neck in rendered images. To overcome these two challenges, we propose a novel generative paradigm \textit{Embedded Representation Learning Network} (ERLNet) with two learning stages. First, the \textit{ audio-driven FLAME} (ADF) module is constructed to produce facial expression and head pose sequences synchronized with content audio and style video. Second, given the sequence deduced by the ADF, one novel \textit{dual-branch fusion NeRF} (DBF-NeRF) explores these contents to render the final images. Extensive empirical studies demonstrate that the collaboration of these two stages effectively facilitates our method to render a more realistic talking head than the existing algorithms.
CSTalk: Correlation Supervised Speech-driven 3D Emotional Facial Animation Generation
Apr 29, 2024



Speech-driven 3D facial animation technology has been developed for years, but its practical application still lacks expectations. The main challenges lie in data limitations, lip alignment, and the naturalness of facial expressions. Although lip alignment has seen many related studies, existing methods struggle to synthesize natural and realistic expressions, resulting in a mechanical and stiff appearance of facial animations. Even with some research extracting emotional features from speech, the randomness of facial movements limits the effective expression of emotions. To address this issue, this paper proposes a method called CSTalk (Correlation Supervised) that models the correlations among different regions of facial movements and supervises the training of the generative model to generate realistic expressions that conform to human facial motion patterns. To generate more intricate animations, we employ a rich set of control parameters based on the metahuman character model and capture a dataset for five different emotions. We train a generative network using an autoencoder structure and input an emotion embedding vector to achieve the generation of user-control expressions. Experimental results demonstrate that our method outperforms existing state-of-the-art methods.
GCC: Generative Calibration Clustering
Apr 14, 2024



Deep clustering as an important branch of unsupervised representation learning focuses on embedding semantically similar samples into the identical feature space. This core demand inspires the exploration of contrastive learning and subspace clustering. However, these solutions always rely on the basic assumption that there are sufficient and category-balanced samples for generating valid high-level representation. This hypothesis actually is too strict to be satisfied for real-world applications. To overcome such a challenge, the natural strategy is utilizing generative models to augment considerable instances. How to use these novel samples to effectively fulfill clustering performance improvement is still difficult and under-explored. In this paper, we propose a novel Generative Calibration Clustering (GCC) method to delicately incorporate feature learning and augmentation into clustering procedure. First, we develop a discriminative feature alignment mechanism to discover intrinsic relationship across real and generated samples. Second, we design a self-supervised metric learning to generate more reliable cluster assignment to boost the conditional diffusion generation. Extensive experimental results on three benchmarks validate the effectiveness and advantage of our proposed method over the state-of-the-art methods.
Sketch3D: Style-Consistent Guidance for Sketch-to-3D Generation
Apr 07, 2024Recently, image-to-3D approaches have achieved significant results with a natural image as input. However, it is not always possible to access these enriched color input samples in practical applications, where only sketches are available. Existing sketch-to-3D researches suffer from limitations in broad applications due to the challenges of lacking color information and multi-view content. To overcome them, this paper proposes a novel generation paradigm Sketch3D to generate realistic 3D assets with shape aligned with the input sketch and color matching the textual description. Concretely, Sketch3D first instantiates the given sketch in the reference image through the shape-preserving generation process. Second, the reference image is leveraged to deduce a coarse 3D Gaussian prior, and multi-view style-consistent guidance images are generated based on the renderings of the 3D Gaussians. Finally, three strategies are designed to optimize 3D Gaussians, i.e., structural optimization via a distribution transfer mechanism, color optimization with a straightforward MSE loss and sketch similarity optimization with a CLIP-based geometric similarity loss. Extensive visual comparisons and quantitative analysis illustrate the advantage of our Sketch3D in generating realistic 3D assets while preserving consistency with the input.
Adversarial Bi-Regressor Network for Domain Adaptive Regression
Sep 20, 2022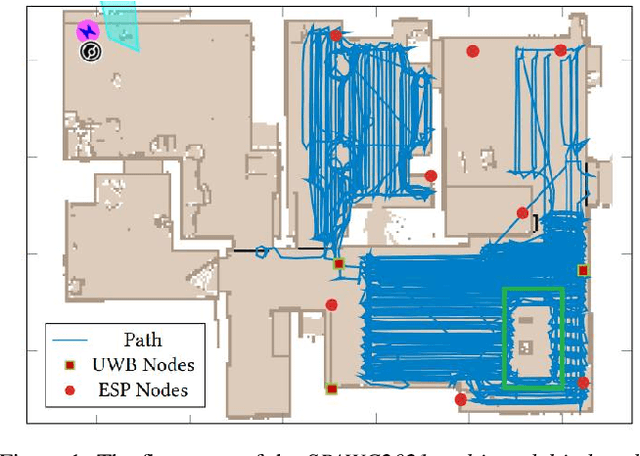
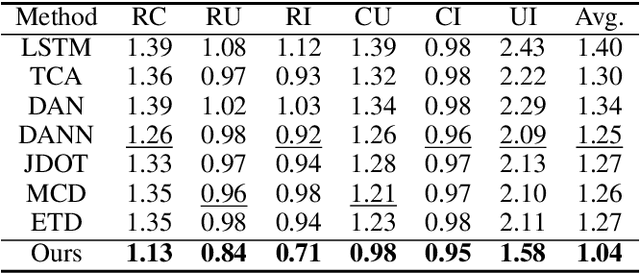
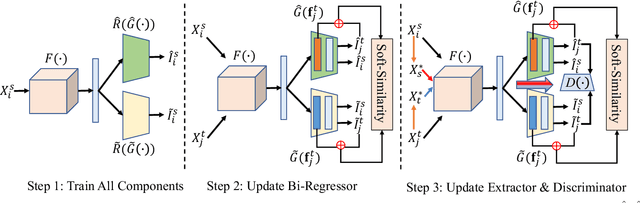
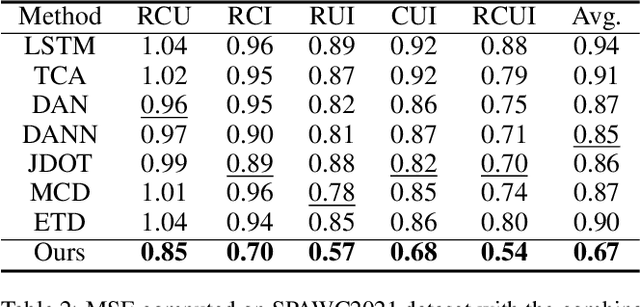
Domain adaptation (DA) aims to transfer the knowledge of a well-labeled source domain to facilitate unlabeled target learning. When turning to specific tasks such as indoor (Wi-Fi) localization, it is essential to learn a cross-domain regressor to mitigate the domain shift. This paper proposes a novel method Adversarial Bi-Regressor Network (ABRNet) to seek more effective cross-domain regression model. Specifically, a discrepant bi-regressor architecture is developed to maximize the difference of bi-regressor to discover uncertain target instances far from the source distribution, and then an adversarial training mechanism is adopted between feature extractor and dual regressors to produce domain-invariant representations. To further bridge the large domain gap, a domain-specific augmentation module is designed to synthesize two source-similar and target-similar intermediate domains to gradually eliminate the original domain mismatch. The empirical studies on two cross-domain regressive benchmarks illustrate the power of our method on solving the domain adaptive regression (DAR) problem.
Adaptively-Accumulated Knowledge Transfer for Partial Domain Adaptation
Aug 27, 2020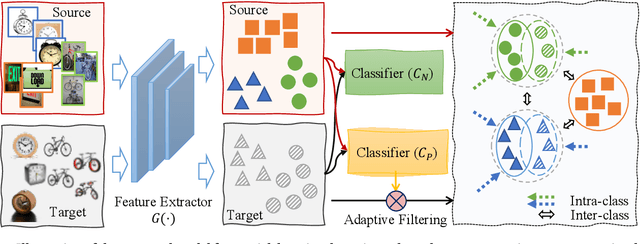
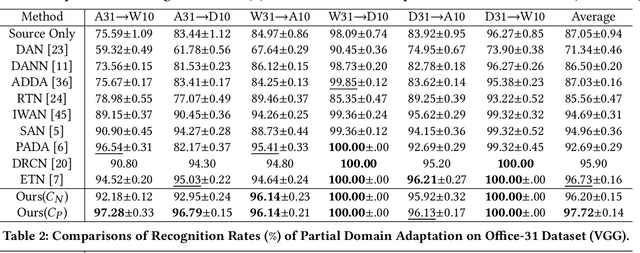
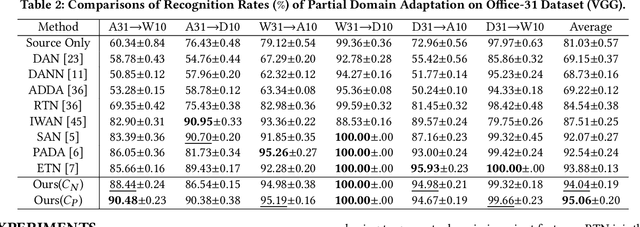
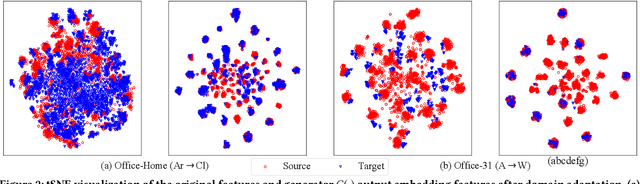
Partial domain adaptation (PDA) attracts appealing attention as it deals with a realistic and challenging problem when the source domain label space substitutes the target domain. Most conventional domain adaptation (DA) efforts concentrate on learning domain-invariant features to mitigate the distribution disparity across domains. However, it is crucial to alleviate the negative influence caused by the irrelevant source domain categories explicitly for PDA. In this work, we propose an Adaptively-Accumulated Knowledge Transfer framework (A$^2$KT) to align the relevant categories across two domains for effective domain adaptation. Specifically, an adaptively-accumulated mechanism is explored to gradually filter out the most confident target samples and their corresponding source categories, promoting positive transfer with more knowledge across two domains. Moreover, a dual distinct classifier architecture consisting of a prototype classifier and a multilayer perceptron classifier is built to capture intrinsic data distribution knowledge across domains from various perspectives. By maximizing the inter-class center-wise discrepancy and minimizing the intra-class sample-wise compactness, the proposed model is able to obtain more domain-invariant and task-specific discriminative representations of the shared categories data. Comprehensive experiments on several partial domain adaptation benchmarks demonstrate the effectiveness of our proposed model, compared with the state-of-the-art PDA methods.
Bi-Directional Generation for Unsupervised Domain Adaptation
Feb 12, 2020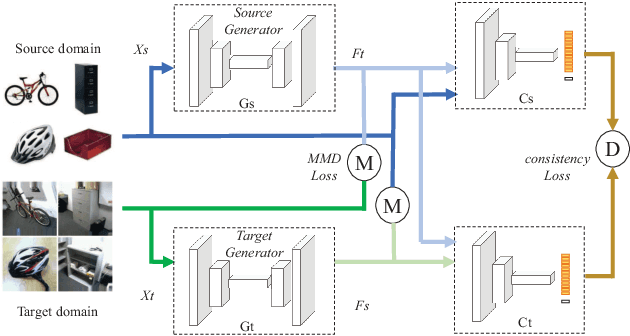
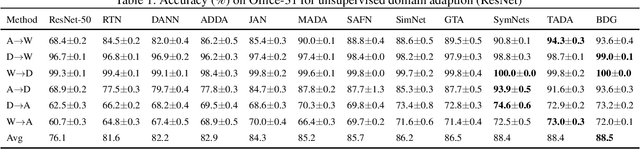
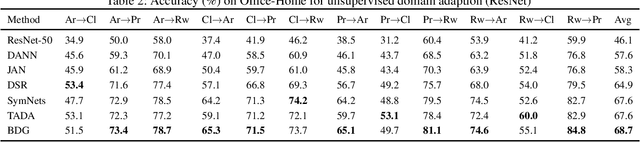

Unsupervised domain adaptation facilitates the unlabeled target domain relying on well-established source domain information. The conventional methods forcefully reducing the domain discrepancy in the latent space will result in the destruction of intrinsic data structure. To balance the mitigation of domain gap and the preservation of the inherent structure, we propose a Bi-Directional Generation domain adaptation model with consistent classifiers interpolating two intermediate domains to bridge source and target domains. Specifically, two cross-domain generators are employed to synthesize one domain conditioned on the other. The performance of our proposed method can be further enhanced by the consistent classifiers and the cross-domain alignment constraints. We also design two classifiers which are jointly optimized to maximize the consistency on target sample prediction. Extensive experiments verify that our proposed model outperforms the state-of-the-art on standard cross domain visual benchmarks.
* 9 pages, 4 figures