 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation of Large Language Models
Jun 14, 2023Knowledge Distillation (KD) is a promising technique for reducing the high computational demand of large language models (LLMs). However, previous KD methods are primarily applied to white-box classification models or training small models to imitate black-box model APIs like ChatGPT. How to effectively distill the knowledge from white-box generative LLMs is still under-explored, which becomes more and more important with the prosperity of LLMs. In this work, we propose MiniLLM that distills smaller language models from generative larger language models. We first replace the forward Kullback-Leibler divergence (KLD) objective in the standard KD approaches with reverse KLD, which is more suitable for KD on generative language models, to prevent the student model from overestimating the low-probability regions of the teacher distribution. Then, we derive an effective optimization approach to learn this objective. Extensive experiments in the instruction-following setting show that the MiniLLM models generate more precise responses with the higher overall quality, lower exposure bias, better calibration, and higher long-text generation performance. Our method is also scalable for different model families with 120M to 13B parameters. We will release our code and model checkpoints at https://aka.ms/MiniLLM.
Pre-Training to Learn in Context
May 16, 2023



In-context learning, where pre-trained language models learn to perform tasks from task examples and instructions in their contexts, has attracted much attention in the NLP community. However, the ability of in-context learning is not fully exploited because language models are not explicitly trained to learn in context. To this end, we propose PICL (Pre-training for In-Context Learning), a framework to enhance the language models' in-context learning ability by pre-training the model on a large collection of "intrinsic tasks" in the general plain-text corpus using the simple language modeling objective. PICL encourages the model to infer and perform tasks by conditioning on the contexts while maintaining task generalization of pre-trained models. We evaluate the in-context learning performance of the model trained with PICL on seven widely-used text classification datasets and the Super-NaturalInstrctions benchmark, which contains 100+ NLP tasks formulated to text generation. Our experiments show that PICL is more effective and task-generalizable than a range of baselines, outperforming larger language models with nearly 4x parameters. The code is publicly available at https://github.com/thu-coai/PICL.
Structured Prompting: Scaling In-Context Learning to 1,000 Examples
Dec 13, 2022



Large language models have exhibited intriguing in-context learning capability, achieving promising zero- and few-shot performance without updating the parameters. However, conventional in-context learning is usually restricted by length constraints, rendering it ineffective to absorb supervision from a large number of examples. In order to go beyond few shots, we introduce structured prompting that breaks the length limit and scales in-context learning to thousands of examples. Specifically, demonstration examples are separately encoded with well-designed position embeddings, and then they are jointly attended by the test example using a rescaled attention mechanism. So we can scale the number of exemplars with linear complexity instead of quadratic complexity with respect to length. Experimental results on a diverse set of tasks show that our approach improves end-task performance and reduces evaluation variance over conventional in-context learning as the number of demonstration examples increases. Code has been released at https://aka.ms/structured-prompting.
Learning Instructions with Unlabeled Data for Zero-Shot Cross-Task Generalization
Oct 17, 2022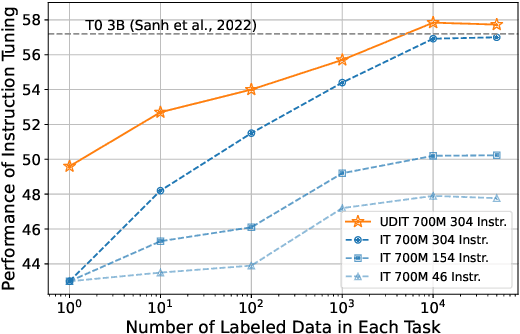
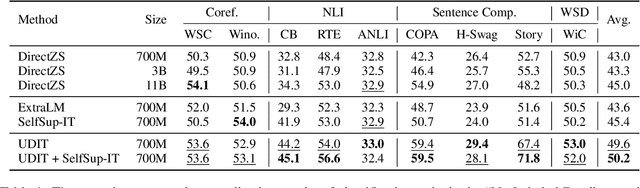
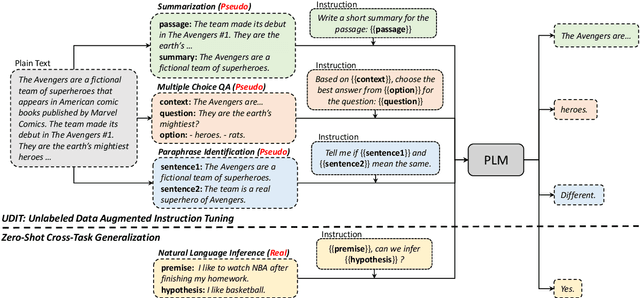
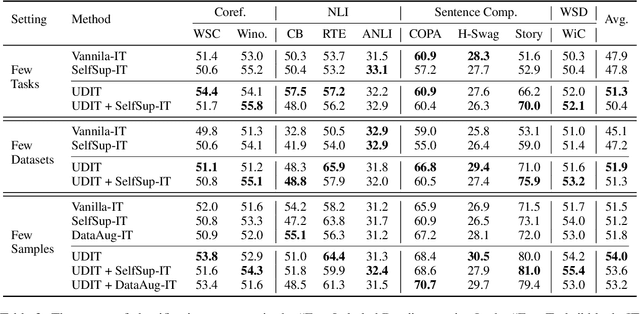
Training language models to learn from human instructions for zero-shot cross-task generalization has attracted much attention in NLP communities. Recently, instruction tuning (IT), which fine-tunes a pre-trained language model on a massive collection of tasks described via human-craft instructions, has been shown effective in instruction learning for unseen tasks. However, IT relies on a large amount of human-annotated samples, which restricts its generalization. Unlike labeled data, unlabeled data are often massive and cheap to obtain. In this work, we study how IT can be improved with unlabeled data. We first empirically explore the IT performance trends versus the number of labeled data, instructions, and training tasks. We find it critical to enlarge the number of training instructions, and the instructions can be underutilized due to the scarcity of labeled data. Then, we propose Unlabeled Data Augmented Instruction Tuning (UDIT) to take better advantage of the instructions during IT by constructing pseudo-labeled data from unlabeled plain texts. We conduct extensive experiments to show UDIT's effectiveness in various scenarios of tasks and datasets. We also comprehensively analyze the key factors of UDIT to investigate how to better improve IT with unlabeled data. The code is publicly available at https://github.com/thu-coai/UDIT.
Many-Class Text Classification with Matching
May 23, 2022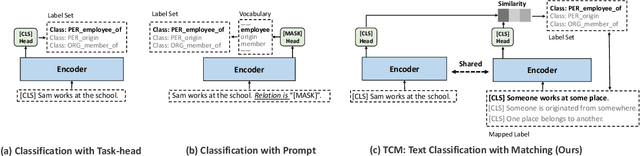
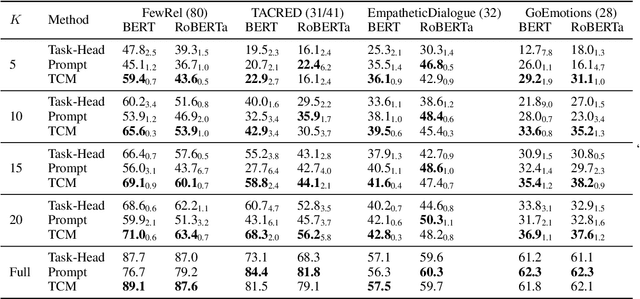
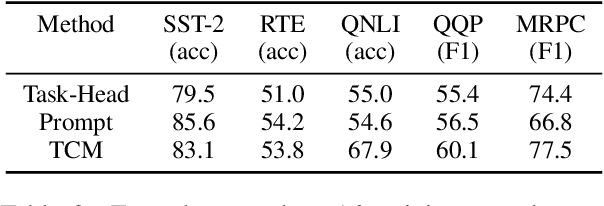
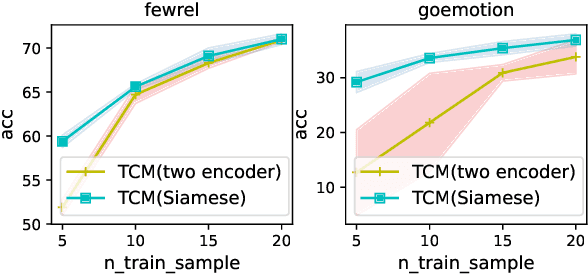
In this work, we formulate \textbf{T}ext \textbf{C}lassification as a \textbf{M}atching problem between the text and the labels, and propose a simple yet effective framework named TCM. Compared with previous text classification approaches, TCM takes advantage of the fine-grained semantic information of the classification labels, which helps distinguish each class better when the class number is large, especially in low-resource scenarios. TCM is also easy to implement and is compatible with various large pretrained language models. We evaluate TCM on 4 text classification datasets (each with 20+ labels) in both few-shot and full-data settings, and this model demonstrates significant improvements over other text classification paradigms. We also conduct extensive experiments with different variants of TCM and discuss the underlying factors of its success. Our method and analyses offer a new perspective on text classification.
EVA2.0: Investigating Open-Domain Chinese Dialogue Systems with Large-Scale Pre-Training
Mar 17, 2022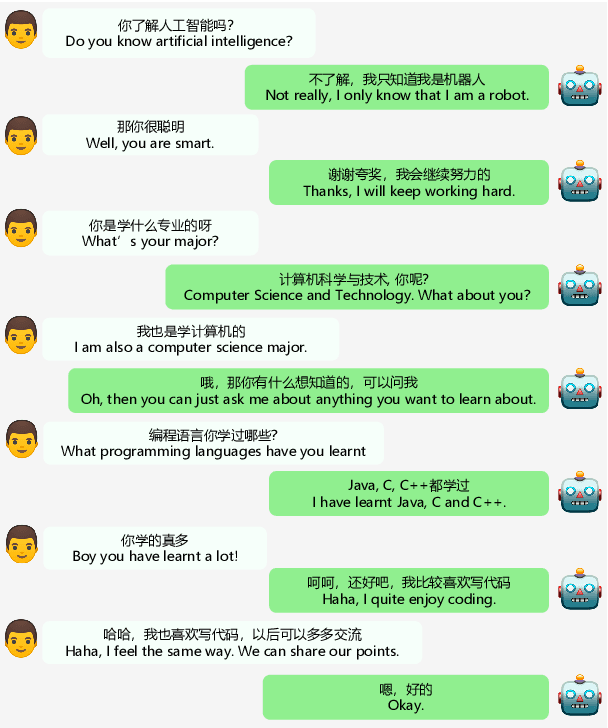


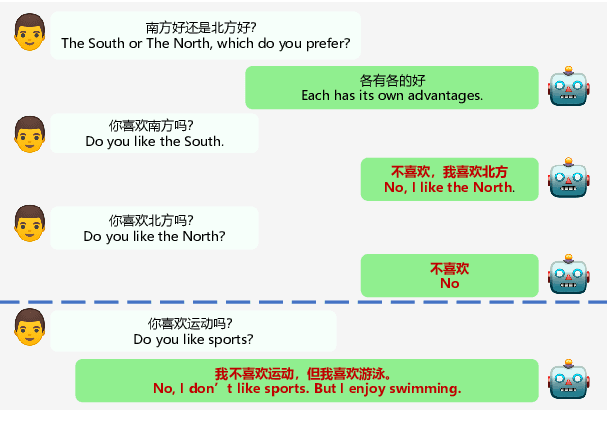
Large-scale pre-training has shown remarkable performance in building open-domain dialogue systems. However, previous works mainly focus on showing and evaluating the conversational performance of the released dialogue model, ignoring the discussion of some key factors towards a powerful human-like chatbot, especially in Chinese scenarios. In this paper, we conduct extensive experiments to investigate these under-explored factors, including data quality control, model architecture designs, training approaches, and decoding strategies. We propose EVA2.0, a large-scale pre-trained open-domain Chinese dialogue model with 2.8 billion parameters, and make our models and code publicly available. To our knowledge, EVA2.0 is the largest open-source Chinese dialogue model. Automatic and human evaluations show that our model significantly outperforms other open-source counterparts. We also discuss the limitations of this work by presenting some failure cases and pose some future directions.
CUGE: A Chinese Language Understanding and Generation Evaluation Benchmark
Dec 27, 2021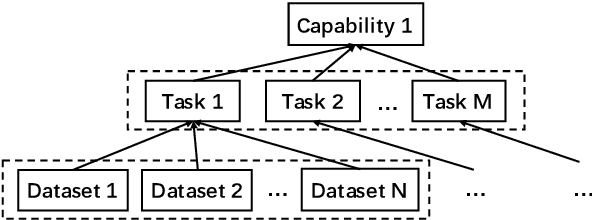
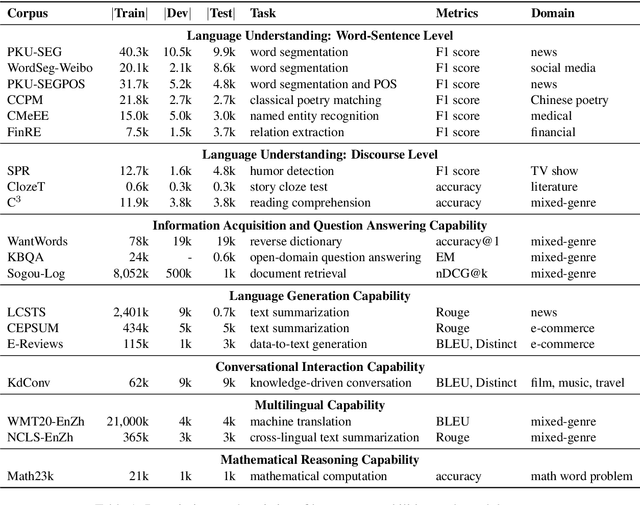

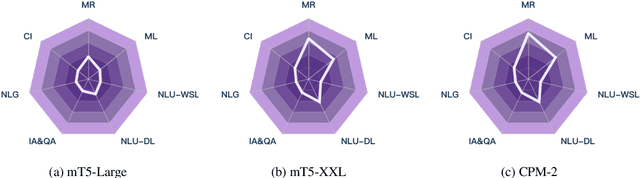
Realizing general-purpose language intelligence has been a longstanding goal for natural language processing, where standard evaluation benchmarks play a fundamental and guiding role. We argue that for general-purpose language intelligence evaluation, the benchmark itself needs to be comprehensive and systematic. To this end, we propose CUGE, a Chinese Language Understanding and Generation Evaluation benchmark with the following features: (1) Hierarchical benchmark framework, where datasets are principally selected and organized with a language capability-task-dataset hierarchy. (2) Multi-level scoring strategy, where different levels of model performance are provided based on the hierarchical framework. To facilitate CUGE, we provide a public leaderboard that can be customized to support flexible model judging criteria. Evaluation results on representative pre-trained language models indicate ample room for improvement towards general-purpose language intelligence. CUGE is publicly available at cuge.baai.ac.cn.
PPT: Pre-trained Prompt Tuning for Few-shot Learning
Sep 14, 2021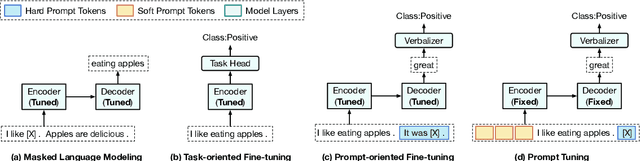

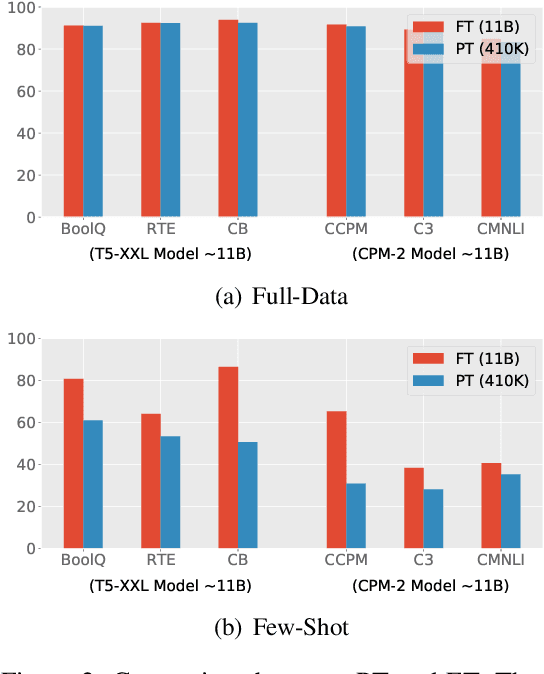
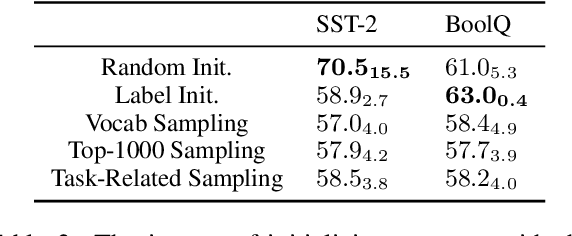
Prompts for pre-trained language models (PLMs) have shown remarkable performance by bridging the gap between pre-training tasks and various downstream tasks. Among these methods, prompt tuning, which freezes PLMs and only tunes soft prompts, provides an efficient and effective solution for adapting large-scale PLMs to downstream tasks. However, prompt tuning is yet to be fully explored. In our pilot experiments, we find that prompt tuning performs comparably with conventional full-model fine-tuning when downstream data are sufficient, whereas it performs much worse under few-shot learning settings, which may hinder the application of prompt tuning in practice. We attribute this low performance to the manner of initializing soft prompts. Therefore, in this work, we propose to pre-train prompts by adding soft prompts into the pre-training stage to obtain a better initialization. We name this Pre-trained Prompt Tuning framework "PPT". To ensure the generalization of PPT, we formulate similar classification tasks into a unified task form and pre-train soft prompts for this unified task. Extensive experiments show that tuning pre-trained prompts for downstream tasks can reach or even outperform full-model fine-tuning under both full-data and few-shot settings. Our approach is effective and efficient for using large-scale PLMs in practice.
EVA: An Open-Domain Chinese Dialogue System with Large-Scale Generative Pre-Training
Aug 03, 2021
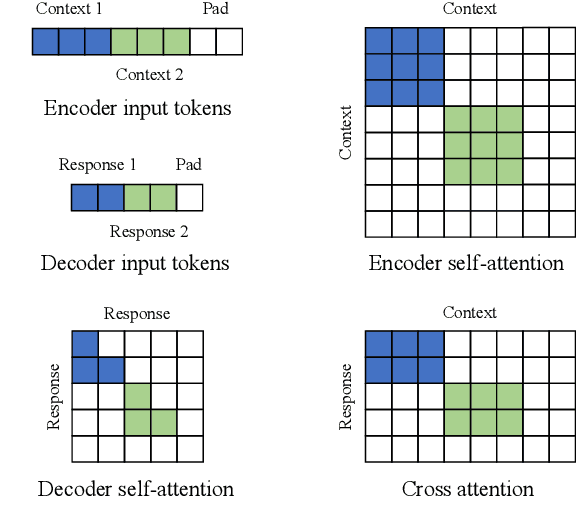
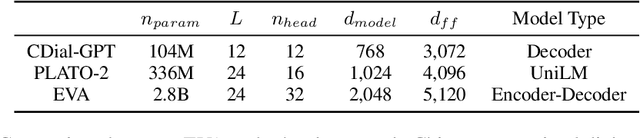
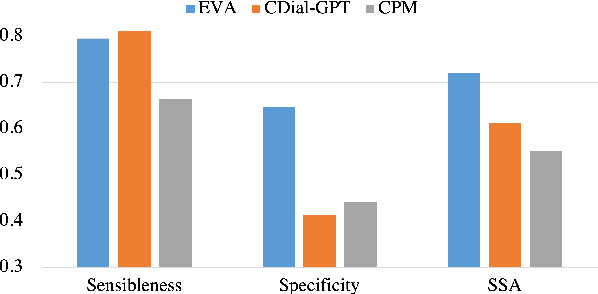
Although pre-trained language models have remarkably enhanced the generation ability of dialogue systems, open-domain Chinese dialogue systems are still limited by the dialogue data and the model size compared with English ones. In this paper, we propose EVA, a Chinese dialogue system that contains the largest Chinese pre-trained dialogue model with 2.8B parameters. To build this model, we collect the largest Chinese dialogue dataset named WDC-Dialogue from various public social media. This dataset contains 1.4B context-response pairs and is used as the pre-training corpus of EVA. Extensive experiments on automatic and human evaluation show that EVA outperforms other Chinese pre-trained dialogue models especially in the multi-turn interaction of human-bot conversations.
CPM-2: Large-scale Cost-effective Pre-trained Language Models
Jun 24, 2021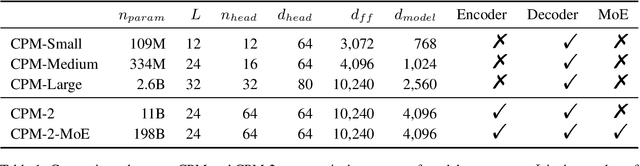
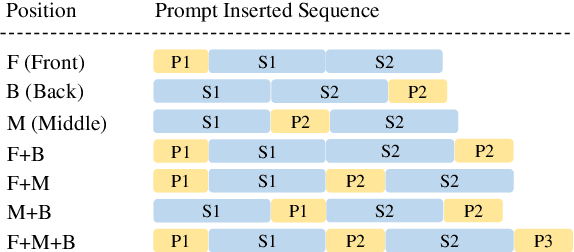

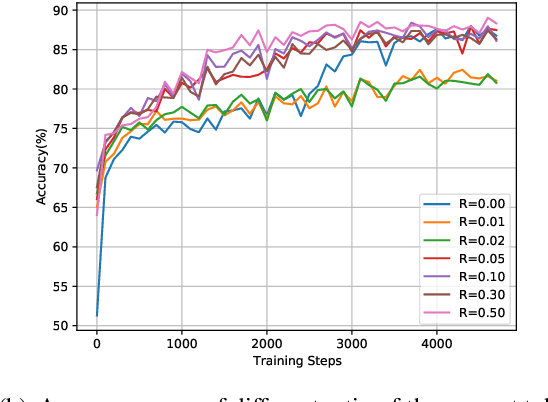
In recent years, the size of pre-trained language models (PLMs) has grown by leaps and bounds. However, efficiency issues of these large-scale PLMs limit their utilization in real-world scenarios. We present a suite of cost-effective techniques for the use of PLMs to deal with the efficiency issues of pre-training, fine-tuning, and inference. (1) We introduce knowledge inheritance to accelerate the pre-training process by exploiting existing PLMs instead of training models from scratch. (2) We explore the best practice of prompt tuning with large-scale PLMs. Compared with conventional fine-tuning, prompt tuning significantly reduces the number of task-specific parameters. (3) We implement a new inference toolkit, namely InfMoE, for using large-scale PLMs with limited computational resources. Based on our cost-effective pipeline, we pre-train two models: an encoder-decoder bilingual model with 11 billion parameters (CPM-2) and its corresponding MoE version with 198 billion parameters. In our experiments, we compare CPM-2 with mT5 on downstream tasks. Experimental results show that CPM-2 has excellent general language intelligence. Moreover, we validate the efficiency of InfMoE when conducting inference of large-scale models having tens of billions of parameters on a single GPU. All source code and model parameters are available at https://github.com/TsinghuaAI/CPM.