 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-Next: Lexicalizing Modalities as Discrete Tokens
Mar 29, 2026The prevailing Next-Token Prediction (NTP) paradigm has driven the success of large language models through discrete autoregressive modeling. However, contemporary multimodal systems remain language-centric, often treating non-linguistic modalities as external attachments, leading to fragmented architectures and suboptimal integration. To transcend this limitation, we introduce Discrete Native Autoregressive (DiNA), a unified framework that represents multimodal information within a shared discrete space, enabling a consistent and principled autoregressive modeling across modalities. A key innovation is the Discrete Native Any-resolution Visual Transformer (dNaViT), which performs tokenization and de-tokenization at arbitrary resolutions, transforming continuous visual signals into hierarchical discrete tokens. Building on this foundation, we develop LongCat-Next, a native multimodal model that processes text, vision, and audio under a single autoregressive objective with minimal modality-specific design. As an industrial-strength foundation model, it excels at seeing, painting, and talking within a single framework, achieving strong performance across a wide range of multimodal benchmarks. In particular, LongCat-Next addresses the long-standing performance ceiling of discrete vision modeling on understanding tasks and provides a unified approach to effectively reconcile the conflict between understanding and generation. As an attempt toward native multimodality, we open-source the LongCat-Next and its tokenizers, hoping to foster further research and development in the community. GitHub: https://github.com/meituan-longcat/LongCat-Next
Structured Prompting: Scaling In-Context Learning to 1,000 Examples
Dec 13, 2022



Large language models have exhibited intriguing in-context learning capability, achieving promising zero- and few-shot performance without updating the parameters. However, conventional in-context learning is usually restricted by length constraints, rendering it ineffective to absorb supervision from a large number of examples. In order to go beyond few shots, we introduce structured prompting that breaks the length limit and scales in-context learning to thousands of examples. Specifically, demonstration examples are separately encoded with well-designed position embeddings, and then they are jointly attended by the test example using a rescaled attention mechanism. So we can scale the number of exemplars with linear complexity instead of quadratic complexity with respect to length. Experimental results on a diverse set of tasks show that our approach improves end-task performance and reduces evaluation variance over conventional in-context learning as the number of demonstration examples increases. Code has been released at https://aka.ms/structured-prompting.
Prototypical Calibration for Few-shot Learning of Language Models
May 20, 2022
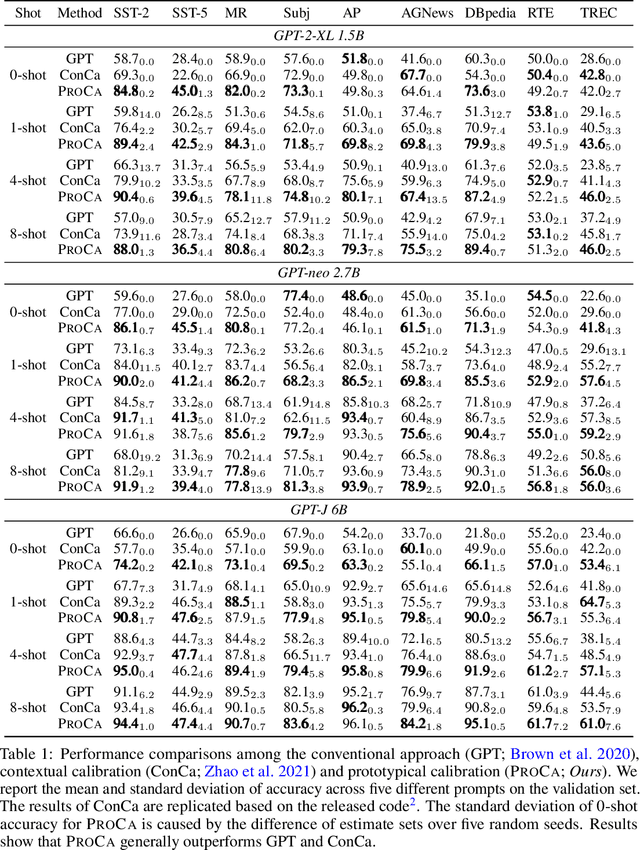
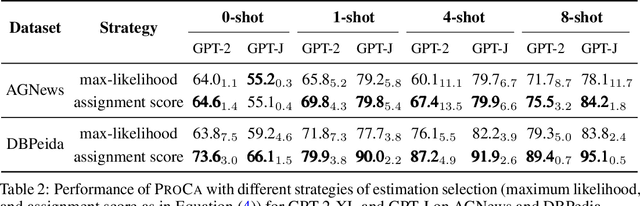
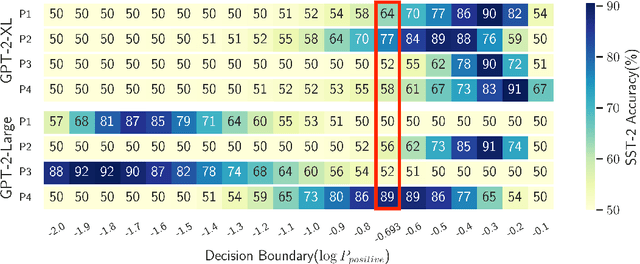
In-context learning of GPT-like models has been recognized as fragile across different hand-crafted templates, and demonstration permutations. In this work, we propose prototypical calibration to adaptively learn a more robust decision boundary for zero- and few-shot classification, instead of greedy decoding. Concretely, our method first adopts Gaussian mixture distribution to estimate the prototypical clusters for all categories. Then we assign each cluster to the corresponding label by solving a weighted bipartite matching problem. Given an example, its prediction is calibrated by the likelihood of prototypical clusters. Experimental results show that prototypical calibration yields a 15% absolute improvement on a diverse set of tasks. Extensive analysis across different scales also indicates that our method calibrates the decision boundary as expected, greatly improving the robustness of GPT to templates, permutations, and class imbalance.