 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Monocular 3D Detectors with LiDAR from the Past
Apr 09, 2024



Accurate 3D object detection is crucial to autonomous driving. Though LiDAR-based detectors have achieved impressive performance, the high cost of LiDAR sensors precludes their widespread adoption in affordable vehicles. Camera-based detectors are cheaper alternatives but often suffer inferior performance compared to their LiDAR-based counterparts due to inherent depth ambiguities in images. In this work, we seek to improve monocular 3D detectors by leveraging unlabeled historical LiDAR data. Specifically, at inference time, we assume that the camera-based detectors have access to multiple unlabeled LiDAR scans from past traversals at locations of interest (potentially from other high-end vehicles equipped with LiDAR sensors). Under this setup, we proposed a novel, simple, and end-to-end trainable framework, termed AsyncDepth, to effectively extract relevant features from asynchronous LiDAR traversals of the same location for monocular 3D detectors. We show consistent and significant performance gain (up to 9 AP) across multiple state-of-the-art models and datasets with a negligible additional latency of 9.66 ms and a small storage cost.
Reward Finetuning for Faster and More Accurate Unsupervised Object Discovery
Nov 05, 2023



Recent advances in machine learning have shown that Reinforcement Learning from Human Feedback (RLHF) can improve machine learning models and align them with human preferences. Although very successful for Large Language Models (LLMs), these advancements have not had a comparable impact in research for autonomous vehicles -- where alignment with human expectations can be imperative. In this paper, we propose to adapt similar RL-based methods to unsupervised object discovery, i.e. learning to detect objects from LiDAR points without any training labels. Instead of labels, we use simple heuristics to mimic human feedback. More explicitly, we combine multiple heuristics into a simple reward function that positively correlates its score with bounding box accuracy, i.e., boxes containing objects are scored higher than those without. We start from the detector's own predictions to explore the space and reinforce boxes with high rewards through gradient updates. Empirically, we demonstrate that our approach is not only more accurate, but also orders of magnitudes faster to train compared to prior works on object discovery.
Pre-Training LiDAR-Based 3D Object Detectors Through Colorization
Oct 23, 2023Accurate 3D object detection and understanding for self-driving cars heavily relies on LiDAR point clouds, necessitating large amounts of labeled data to train. In this work, we introduce an innovative pre-training approach, Grounded Point Colorization (GPC), to bridge the gap between data and labels by teaching the model to colorize LiDAR point clouds, equipping it with valuable semantic cues. To tackle challenges arising from color variations and selection bias, we incorporate color as "context" by providing ground-truth colors as hints during colorization. Experimental results on the KITTI and Waymo datasets demonstrate GPC's remarkable effectiveness. Even with limited labeled data, GPC significantly improves fine-tuning performance; notably, on just 20% of the KITTI dataset, GPC outperforms training from scratch with the entire dataset. In sum, we introduce a fresh perspective on pre-training for 3D object detection, aligning the objective with the model's intended role and ultimately advancing the accuracy and efficiency of 3D object detection for autonomous vehicles.
Unsupervised Domain Adaptation for Self-Driving from Past Traversal Features
Sep 21, 2023The rapid development of 3D object detection systems for self-driving cars has significantly improved accuracy. However, these systems struggle to generalize across diverse driving environments, which can lead to safety-critical failures in detecting traffic participants. To address this, we propose a method that utilizes unlabeled repeated traversals of multiple locations to adapt object detectors to new driving environments. By incorporating statistics computed from repeated LiDAR scans, we guide the adaptation process effectively. Our approach enhances LiDAR-based detection models using spatial quantized historical features and introduces a lightweight regression head to leverage the statistics for feature regularization. Additionally, we leverage the statistics for a novel self-training process to stabilize the training. The framework is detector model-agnostic and experiments on real-world datasets demonstrate significant improvements, achieving up to a 20-point performance gain, especially in detecting pedestrians and distant objects. Code is available at https://github.com/zhangtravis/Hist-DA.
Unsupervised Adaptation from Repeated Traversals for Autonomous Driving
Mar 27, 2023For a self-driving car to operate reliably, its perceptual system must generalize to the end-user's environment -- ideally without additional annotation efforts. One potential solution is to leverage unlabeled data (e.g., unlabeled LiDAR point clouds) collected from the end-users' environments (i.e. target domain) to adapt the system to the difference between training and testing environments. While extensive research has been done on such an unsupervised domain adaptation problem, one fundamental problem lingers: there is no reliable signal in the target domain to supervise the adaptation process. To overcome this issue we observe that it is easy to collect unsupervised data from multiple traversals of repeated routes. While different from conventional unsupervised domain adaptation, this assumption is extremely realistic since many drivers share the same roads. We show that this simple additional assumption is sufficient to obtain a potent signal that allows us to perform iterative self-training of 3D object detectors on the target domain. Concretely, we generate pseudo-labels with the out-of-domain detector but reduce false positives by removing detections of supposedly mobile objects that are persistent across traversals. Further, we reduce false negatives by encouraging predictions in regions that are not persistent. We experiment with our approach on two large-scale driving datasets and show remarkable improvement in 3D object detection of cars, pedestrians, and cyclists, bringing us a step closer to generalizable autonomous driving.
Ithaca365: Dataset and Driving Perception under Repeated and Challenging Weather Conditions
Aug 01, 2022
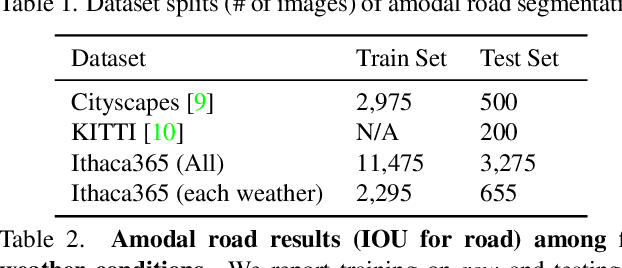
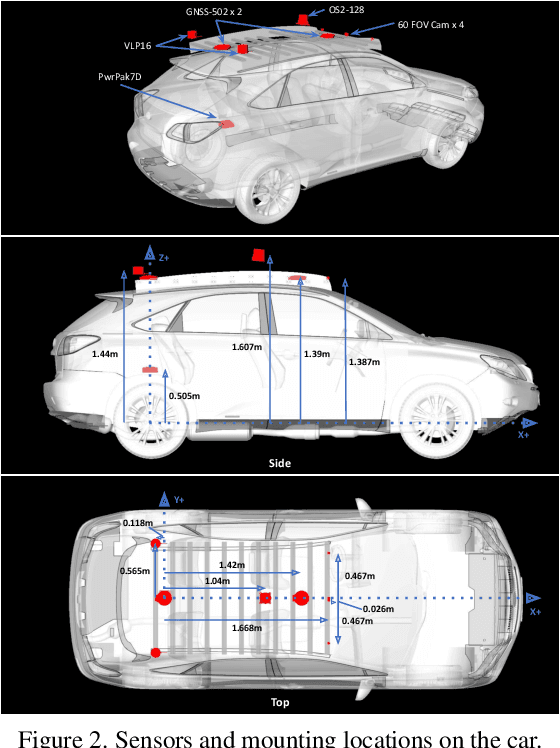
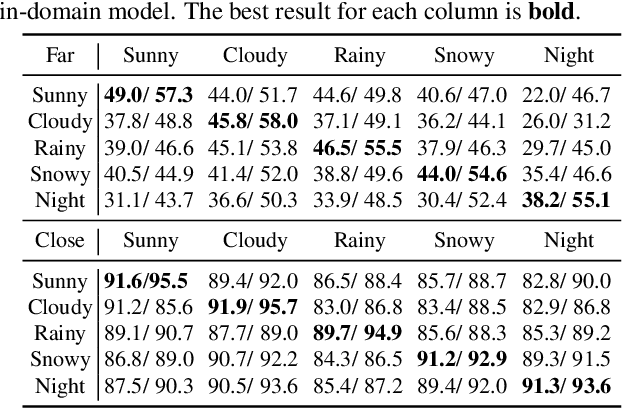
Advances in perception for self-driving cars have accelerated in recent years due to the availability of large-scale datasets, typically collected at specific locations and under nice weather conditions. Yet, to achieve the high safety requirement, these perceptual systems must operate robustly under a wide variety of weather conditions including snow and rain. In this paper, we present a new dataset to enable robust autonomous driving via a novel data collection process - data is repeatedly recorded along a 15 km route under diverse scene (urban, highway, rural, campus), weather (snow, rain, sun), time (day/night), and traffic conditions (pedestrians, cyclists and cars). The dataset includes images and point clouds from cameras and LiDAR sensors, along with high-precision GPS/INS to establish correspondence across routes. The dataset includes road and object annotations using amodal masks to capture partial occlusions and 3D bounding boxes. We demonstrate the uniqueness of this dataset by analyzing the performance of baselines in amodal segmentation of road and objects, depth estimation, and 3D object detection. The repeated routes opens new research directions in object discovery, continual learning, and anomaly detection. Link to Ithaca365: https://ithaca365.mae.cornell.edu/
R4D: Utilizing Reference Objects for Long-Range Distance Estimation
Jun 10, 2022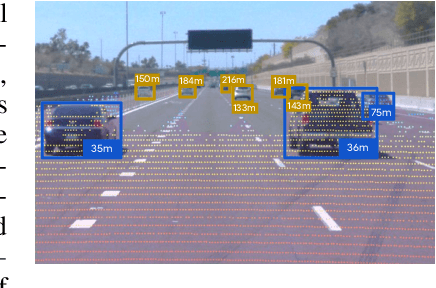

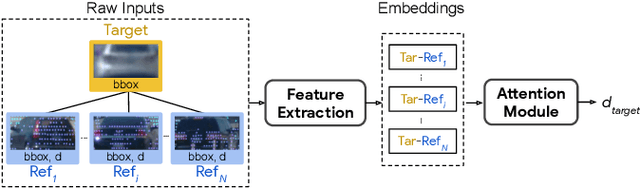
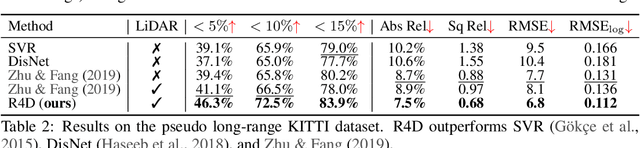
Estimating the distance of objects is a safety-critical task for autonomous driving. Focusing on short-range objects, existing methods and datasets neglect the equally important long-range objects. In this paper, we introduce a challenging and under-explored task, which we refer to as Long-Range Distance Estimation, as well as two datasets to validate new methods developed for this task. We then proposeR4D, the first framework to accurately estimate the distance of long-range objects by using references with known distances in the scene. Drawing inspiration from human perception, R4D builds a graph by connecting a target object to all references. An edge in the graph encodes the relative distance information between a pair of target and reference objects. An attention module is then used to weigh the importance of reference objects and combine them into one target object distance prediction. Experiments on the two proposed datasets demonstrate the effectiveness and robustness of R4D by showing significant improvements compared to existing baselines. We are looking to make the proposed dataset, Waymo OpenDataset - Long-Range Labels, available publicly at waymo.com/open/download.
Depth Estimation Matters Most: Improving Per-Object Depth Estimation for Monocular 3D Detection and Tracking
Jun 08, 2022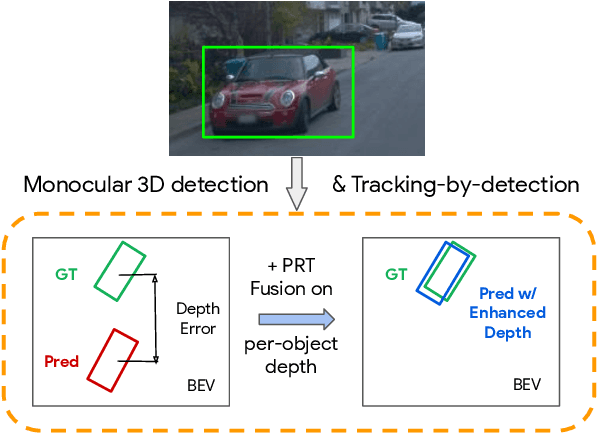
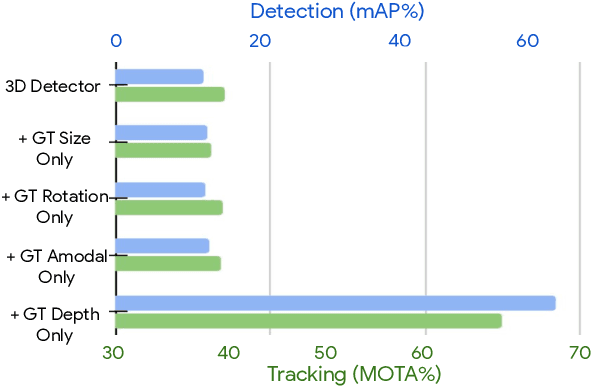
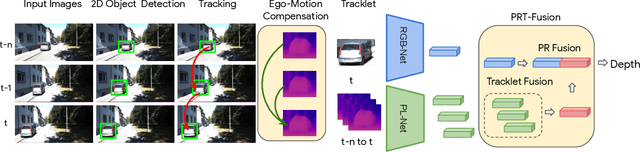
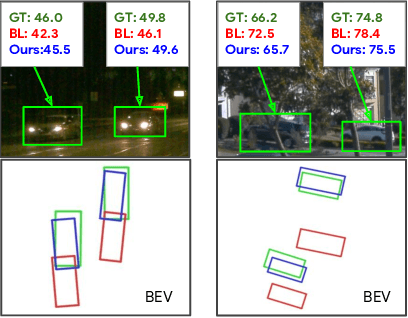
Monocular image-based 3D perception has become an active research area in recent years owing to its applications in autonomous driving. Approaches to monocular 3D perception including detection and tracking, however, often yield inferior performance when compared to LiDAR-based techniques. Through systematic analysis, we identified that per-object depth estimation accuracy is a major factor bounding the performance. Motivated by this observation, we propose a multi-level fusion method that combines different representations (RGB and pseudo-LiDAR) and temporal information across multiple frames for objects (tracklets) to enhance per-object depth estimation. Our proposed fusion method achieves the state-of-the-art performance of per-object depth estimation on the Waymo Open Dataset, the KITTI detection dataset, and the KITTI MOT dataset. We further demonstrate that by simply replacing estimated depth with fusion-enhanced depth, we can achieve significant improvements in monocular 3D perception tasks, including detection and tracking.
Learning to Detect Mobile Objects from LiDAR Scans Without Labels
Mar 29, 2022

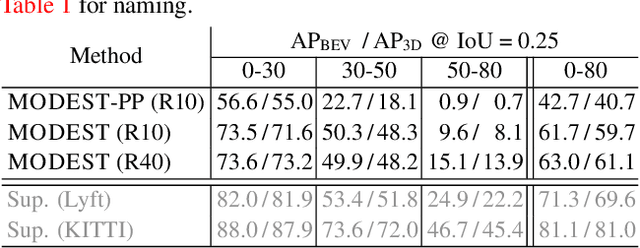
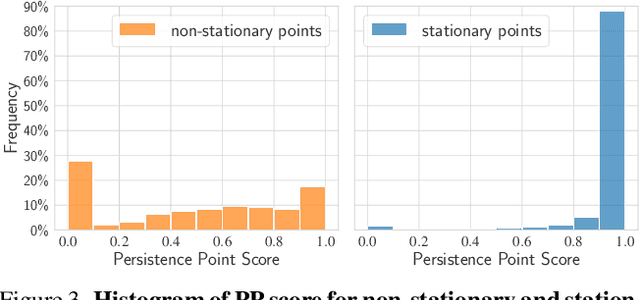
Current 3D object detectors for autonomous driving are almost entirely trained on human-annotated data. Although of high quality, the generation of such data is laborious and costly, restricting them to a few specific locations and object types. This paper proposes an alternative approach entirely based on unlabeled data, which can be collected cheaply and in abundance almost everywhere on earth. Our approach leverages several simple common sense heuristics to create an initial set of approximate seed labels. For example, relevant traffic participants are generally not persistent across multiple traversals of the same route, do not fly, and are never under ground. We demonstrate that these seed labels are highly effective to bootstrap a surprisingly accurate detector through repeated self-training without a single human annotated label.
Hindsight is 20/20: Leveraging Past Traversals to Aid 3D Perception
Mar 22, 2022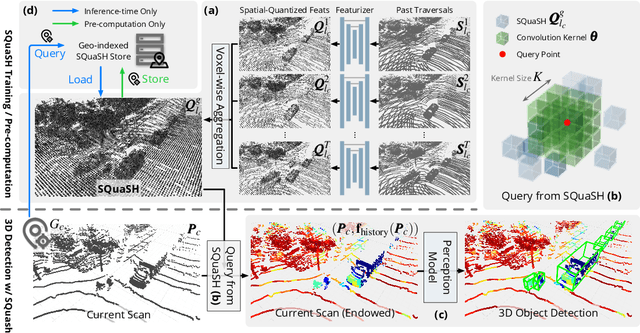
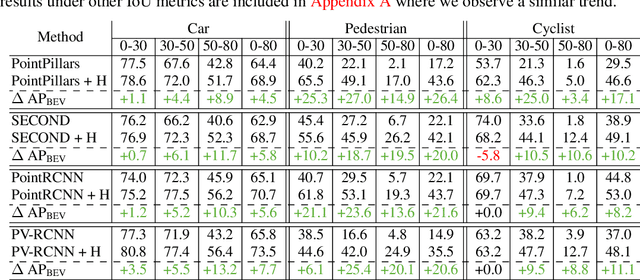
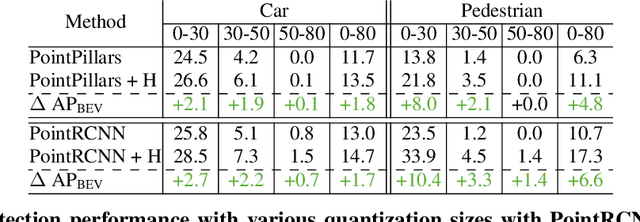
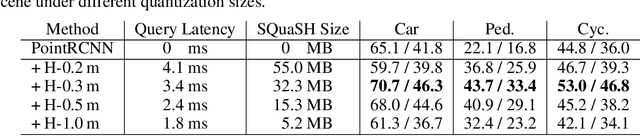
Self-driving cars must detect vehicles, pedestrians, and other traffic participants accurately to operate safely. Small, far-away, or highly occluded objects are particularly challenging because there is limited information in the LiDAR point clouds for detecting them. To address this challenge, we leverage valuable information from the past: in particular, data collected in past traversals of the same scene. We posit that these past data, which are typically discarded, provide rich contextual information for disambiguating the above-mentioned challenging cases. To this end, we propose a novel, end-to-end trainable Hindsight framework to extract this contextual information from past traversals and store it in an easy-to-query data structure, which can then be leveraged to aid future 3D object detection of the same scene. We show that this framework is compatible with most modern 3D detection architectures and can substantially improve their average precision on multiple autonomous driving datasets, most notably by more than 300% on the challenging cases.