 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYun Liu
PointGame: Geometrically and Adaptively Masked Auto-Encoder on Point Clouds
Mar 23, 2023
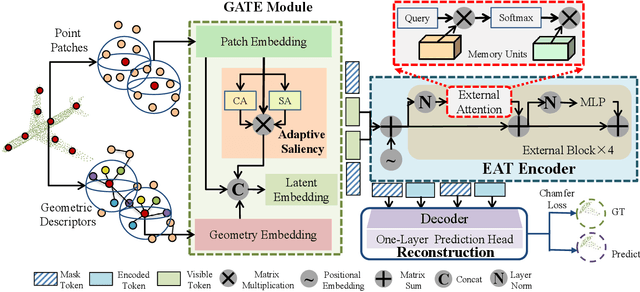
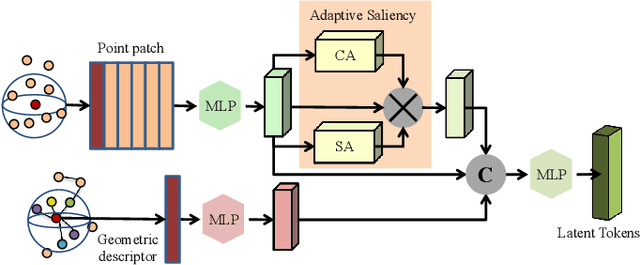
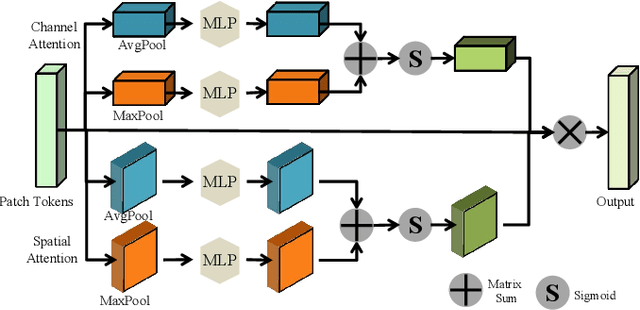
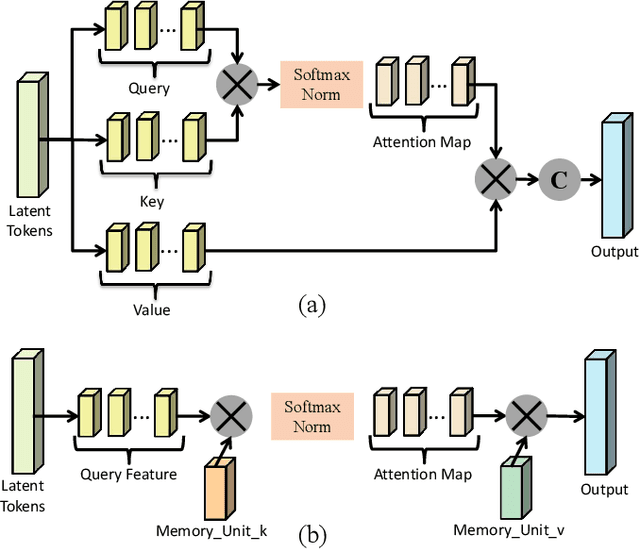
Self-supervised learning is attracting large attention in point cloud understanding. However, exploring discriminative and transferable features still remains challenging due to their nature of irregularity and sparsity. We propose a geometrically and adaptively masked auto-encoder for self-supervised learning on point clouds, termed \textit{PointGame}. PointGame contains two core components: GATE and EAT. GATE stands for the geometrical and adaptive token embedding module; it not only absorbs the conventional wisdom of geometric descriptors that captures the surface shape effectively, but also exploits adaptive saliency to focus on the salient part of a point cloud. EAT stands for the external attention-based Transformer encoder with linear computational complexity, which increases the efficiency of the whole pipeline. Unlike cutting-edge unsupervised learning models, PointGame leverages geometric descriptors to perceive surface shapes and adaptively mines discriminative features from training data. PointGame showcases clear advantages over its competitors on various downstream tasks under both global and local fine-tuning strategies. The code and pre-trained models will be publicly available.
DEHRFormer: Real-time Transformer for Depth Estimation and Haze Removal from Varicolored Haze Scenes
Mar 13, 2023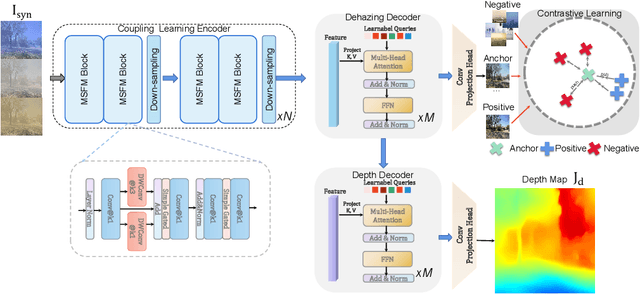
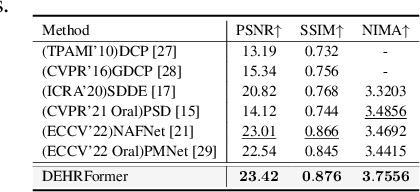
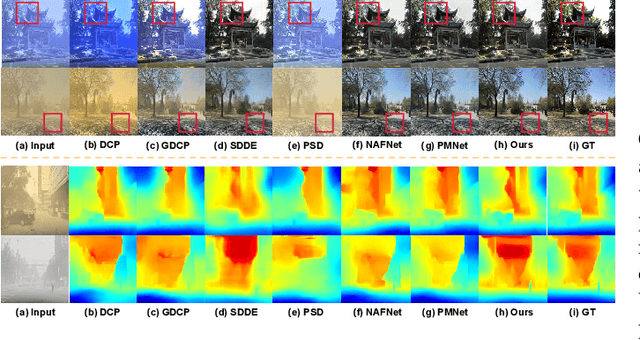
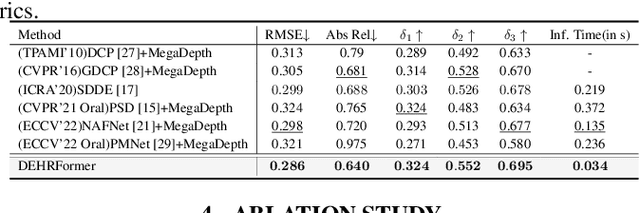
Varicolored haze caused by chromatic casts poses haze removal and depth estimation challenges. Recent learning-based depth estimation methods are mainly targeted at dehazing first and estimating depth subsequently from haze-free scenes. This way, the inner connections between colored haze and scene depth are lost. In this paper, we propose a real-time transformer for simultaneous single image Depth Estimation and Haze Removal (DEHRFormer). DEHRFormer consists of a single encoder and two task-specific decoders. The transformer decoders with learnable queries are designed to decode coupling features from the task-agnostic encoder and project them into clean image and depth map, respectively. In addition, we introduce a novel learning paradigm that utilizes contrastive learning and domain consistency learning to tackle weak-generalization problem for real-world dehazing, while predicting the same depth map from the same scene with varicolored haze. Experiments demonstrate that DEHRFormer achieves significant performance improvement across diverse varicolored haze scenes over previous depth estimation networks and dehazing approaches.
RSFDM-Net: Real-time Spatial and Frequency Domains Modulation Network for Underwater Image Enhancement
Feb 23, 2023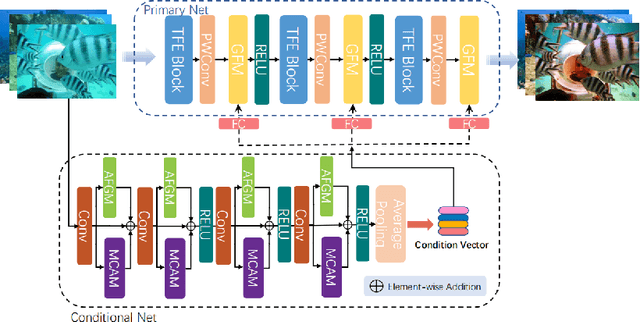

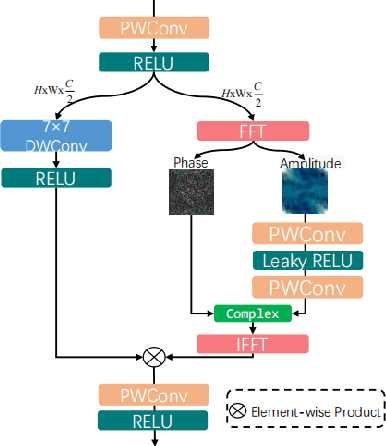
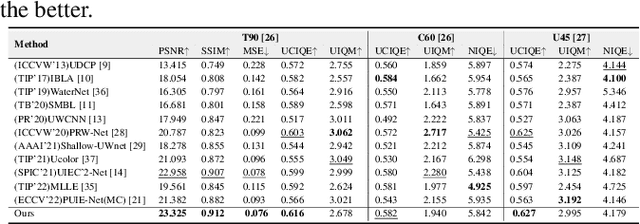
Underwater images typically experience mixed degradations of brightness and structure caused by the absorption and scattering of light by suspended particles. To address this issue, we propose a Real-time Spatial and Frequency Domains Modulation Network (RSFDM-Net) for the efficient enhancement of colors and details in underwater images. Specifically, our proposed conditional network is designed with Adaptive Fourier Gating Mechanism (AFGM) and Multiscale Convolutional Attention Module (MCAM) to generate vectors carrying low-frequency background information and high-frequency detail features, which effectively promote the network to model global background information and local texture details. To more precisely correct the color cast and low saturation of the image, we introduce a Three-branch Feature Extraction (TFE) block in the primary net that processes images pixel by pixel to integrate the color information extended by the same channel (R, G, or B). This block consists of three small branches, each of which has its own weights. Extensive experiments demonstrate that our network significantly outperforms over state-of-the-art methods in both visual quality and quantitative metrics.
Generative Sentiment Transfer via Adaptive Masking
Feb 23, 2023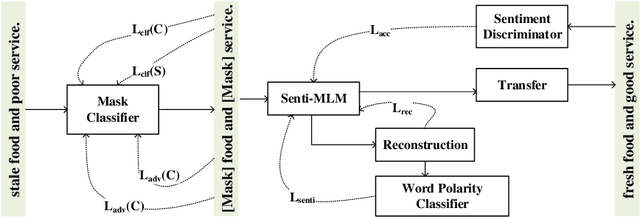
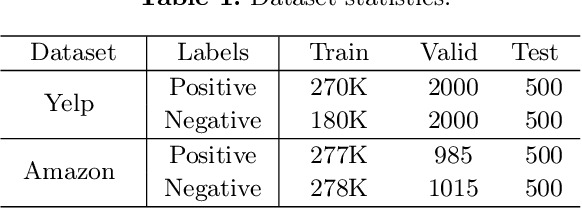
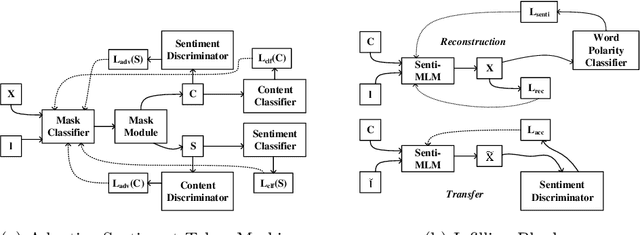
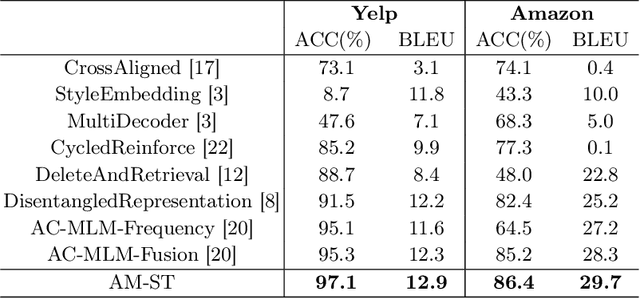
Sentiment transfer aims at revising the input text to satisfy a given sentiment polarity while retaining the original semantic content. The nucleus of sentiment transfer lies in precisely separating the sentiment information from the content information. Existing explicit approaches generally identify and mask sentiment tokens simply based on prior linguistic knowledge and manually-defined rules, leading to low generality and undesirable transfer performance. In this paper, we view the positions to be masked as the learnable parameters, and further propose a novel AM-ST model to learn adaptive task-relevant masks based on the attention mechanism. Moreover, a sentiment-aware masked language model is further proposed to fill in the blanks in the masked positions by incorporating both context and sentiment polarity to capture the multi-grained semantics comprehensively. AM-ST is thoroughly evaluated on two popular datasets, and the experimental results demonstrate the superiority of our proposal.
Large Language Models Encode Clinical Knowledge
Dec 26, 2022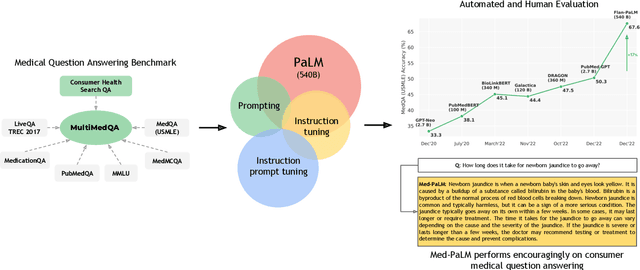
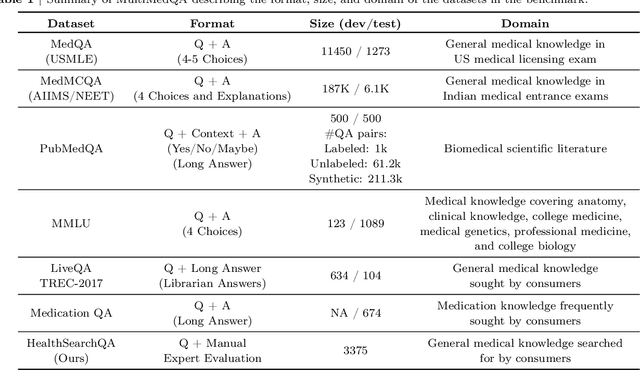
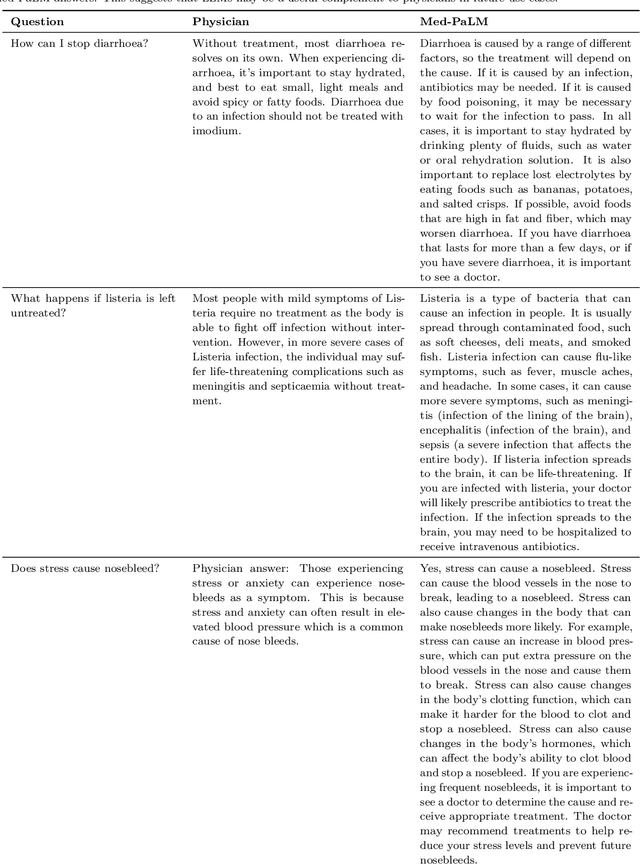

Large language models (LLMs) have demonstrated impressive capabilities in natural language understanding and generation, but the quality bar for medical and clinical applications is high. Today, attempts to assess models' clinical knowledge typically rely on automated evaluations on limited benchmarks. There is no standard to evaluate model predictions and reasoning across a breadth of tasks. To address this, we present MultiMedQA, a benchmark combining six existing open question answering datasets spanning professional medical exams, research, and consumer queries; and HealthSearchQA, a new free-response dataset of medical questions searched online. We propose a framework for human evaluation of model answers along multiple axes including factuality, precision, possible harm, and bias. In addition, we evaluate PaLM (a 540-billion parameter LLM) and its instruction-tuned variant, Flan-PaLM, on MultiMedQA. Using a combination of prompting strategies, Flan-PaLM achieves state-of-the-art accuracy on every MultiMedQA multiple-choice dataset (MedQA, MedMCQA, PubMedQA, MMLU clinical topics), including 67.6% accuracy on MedQA (US Medical License Exam questions), surpassing prior state-of-the-art by over 17%. However, human evaluation reveals key gaps in Flan-PaLM responses. To resolve this we introduce instruction prompt tuning, a parameter-efficient approach for aligning LLMs to new domains using a few exemplars. The resulting model, Med-PaLM, performs encouragingly, but remains inferior to clinicians. We show that comprehension, recall of knowledge, and medical reasoning improve with model scale and instruction prompt tuning, suggesting the potential utility of LLMs in medicine. Our human evaluations reveal important limitations of today's models, reinforcing the importance of both evaluation frameworks and method development in creating safe, helpful LLM models for clinical applications.
Deep Negative Correlation Classification
Dec 14, 2022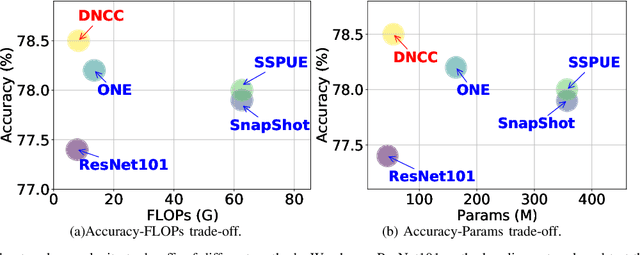
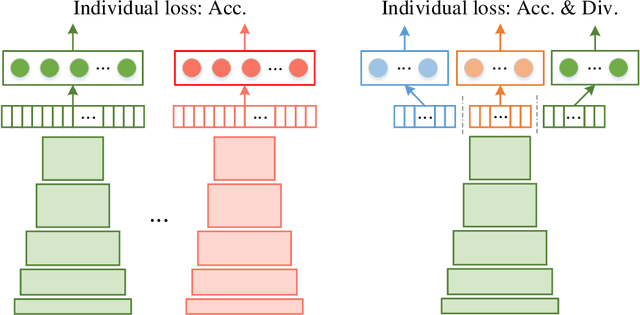
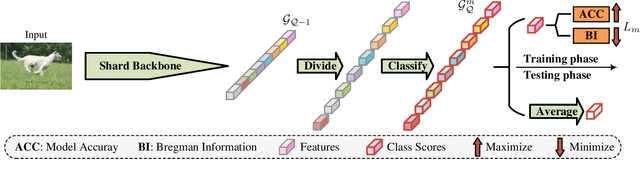
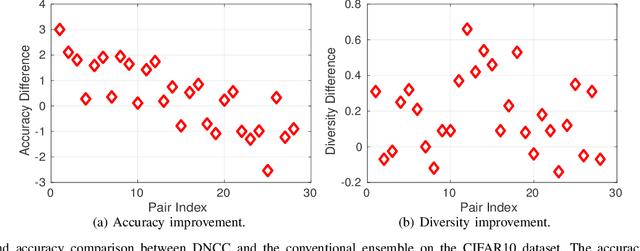
Ensemble learning serves as a straightforward way to improve the performance of almost any machine learning algorithm. Existing deep ensemble methods usually naively train many different models and then aggregate their predictions. This is not optimal in our view from two aspects: i) Naively training multiple models adds much more computational burden, especially in the deep learning era; ii) Purely optimizing each base model without considering their interactions limits the diversity of ensemble and performance gains. We tackle these issues by proposing deep negative correlation classification (DNCC), in which the accuracy and diversity trade-off is systematically controlled by decomposing the loss function seamlessly into individual accuracy and the correlation between individual models and the ensemble. DNCC yields a deep classification ensemble where the individual estimator is both accurate and negatively correlated. Thanks to the optimized diversities, DNCC works well even when utilizing a shared network backbone, which significantly improves its efficiency when compared with most existing ensemble systems. Extensive experiments on multiple benchmark datasets and network structures demonstrate the superiority of the proposed method.
MONAI: An open-source framework for deep learning in healthcare
Nov 04, 2022
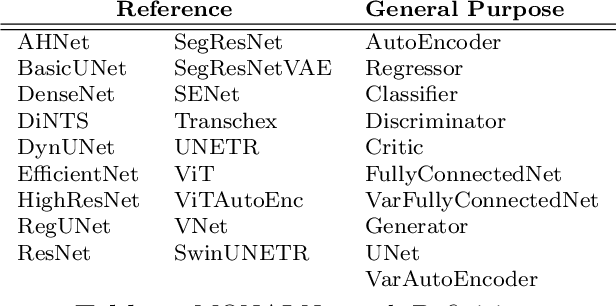
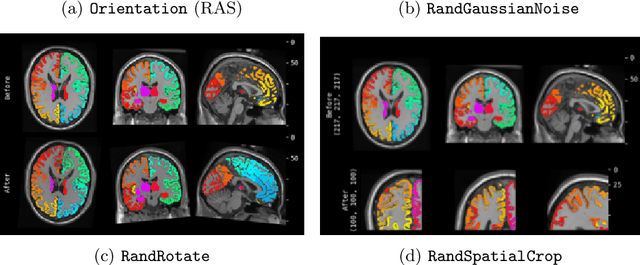
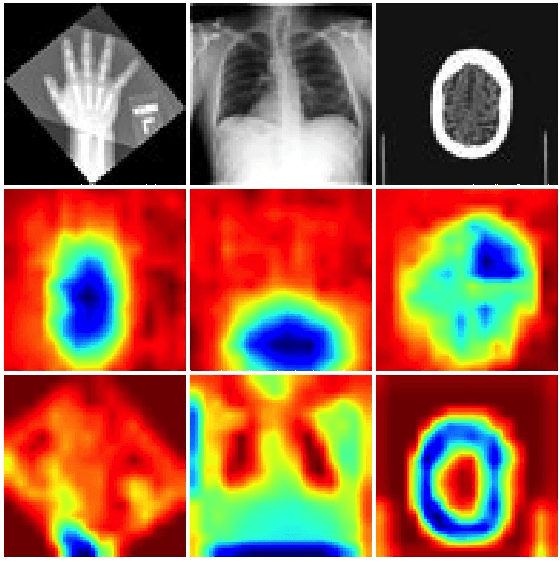
Artificial Intelligence (AI) is having a tremendous impact across most areas of science. Applications of AI in healthcare have the potential to improve our ability to detect, diagnose, prognose, and intervene on human disease. For AI models to be used clinically, they need to be made safe, reproducible and robust, and the underlying software framework must be aware of the particularities (e.g. geometry, physiology, physics) of medical data being processed. This work introduces MONAI, a freely available, community-supported, and consortium-led PyTorch-based framework for deep learning in healthcare. MONAI extends PyTorch to support medical data, with a particular focus on imaging, and provide purpose-specific AI model architectures, transformations and utilities that streamline the development and deployment of medical AI models. MONAI follows best practices for software-development, providing an easy-to-use, robust, well-documented, and well-tested software framework. MONAI preserves the simple, additive, and compositional approach of its underlying PyTorch libraries. MONAI is being used by and receiving contributions from research, clinical and industrial teams from around the world, who are pursuing applications spanning nearly every aspect of healthcare.
Enhancing Generalizable 6D Pose Tracking of an In-Hand Object with Tactile Sensing
Oct 08, 2022
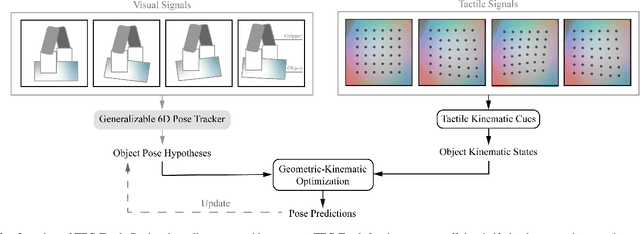


While holding and manipulating an object, humans track the object states through vision and touch so as to achieve complex tasks. However, nowadays the majority of robot research perceives object states just from visual signals, hugely limiting the robotic manipulation abilities. This work presents a tactile-enhanced generalizable 6D pose tracking design named TEG-Track to track previously unseen in-hand objects. TEG-Track extracts tactile kinematic cues of an in-hand object from consecutive tactile sensing signals. Such cues are incorporated into a geometric-kinematic optimization scheme to enhance existing generalizable visual trackers. To test our method in real scenarios and enable future studies on generalizable visual-tactile tracking, we collect a real visual-tactile in-hand object pose tracking dataset. Experiments show that TEG-Track significantly improves state-of-the-art generalizable 6D pose trackers in both synthetic and real cases.
Dual-former: Hybrid Self-attention Transformer for Efficient Image Restoration
Oct 03, 2022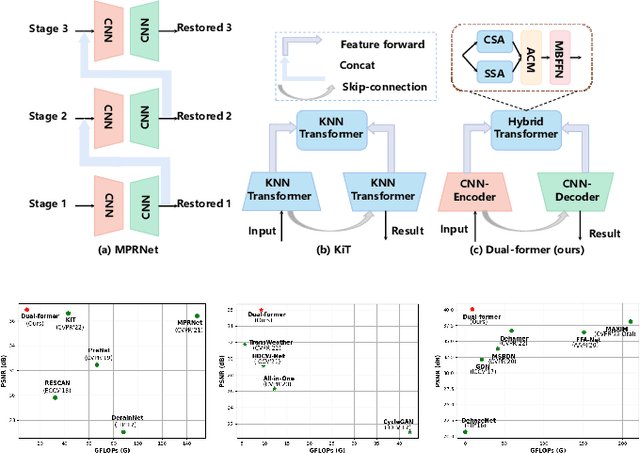

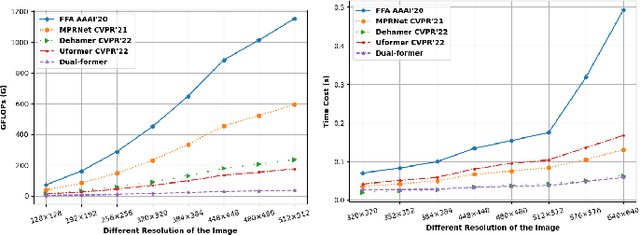
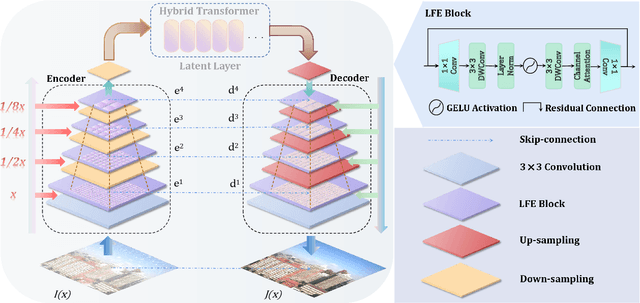
Recently, image restoration transformers have achieved comparable performance with previous state-of-the-art CNNs. However, how to efficiently leverage such architectures remains an open problem. In this work, we present Dual-former whose critical insight is to combine the powerful global modeling ability of self-attention modules and the local modeling ability of convolutions in an overall architecture. With convolution-based Local Feature Extraction modules equipped in the encoder and the decoder, we only adopt a novel Hybrid Transformer Block in the latent layer to model the long-distance dependence in spatial dimensions and handle the uneven distribution between channels. Such a design eliminates the substantial computational complexity in previous image restoration transformers and achieves superior performance on multiple image restoration tasks. Experiments demonstrate that Dual-former achieves a 1.91dB gain over the state-of-the-art MAXIM method on the Indoor dataset for single image dehazing while consuming only 4.2% GFLOPs as MAXIM. For single image deraining, it exceeds the SOTA method by 0.1dB PSNR on the average results of five datasets with only 21.5% GFLOPs. Dual-former also substantially surpasses the latest desnowing method on various datasets, with fewer parameters.
SnowFormer: Scale-aware Transformer via Context Interaction for Single Image Desnowing
Aug 23, 2022
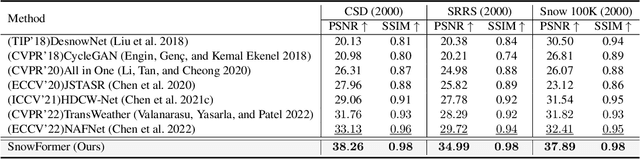
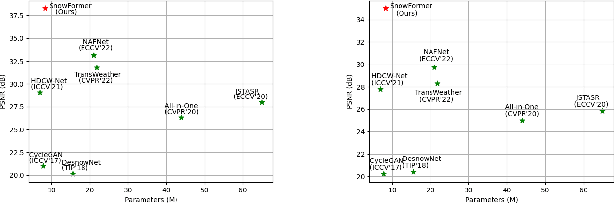
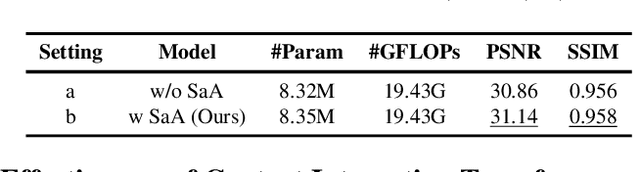
Single image desnowing is a common yet challenging task. The complex snow degradations and diverse degradation scales demand strong representation ability. In order for the desnowing network to see various snow degradations and model the context interaction of local details and global information, we propose a powerful architecture dubbed as SnowFormer. First, it performs Scale-aware Feature Aggregation in the encoder to capture rich snow information of various degradations. Second, in order to tackle with large-scale degradation, it uses a novel Context Interaction Transformer Block in the decoder, which conducts context interaction of local details and global information from previous scale-aware feature aggregation in global context interaction. And the introduction of local context interaction improves recovery of scene details. Third, we devise a Heterogeneous Feature Projection Head which progressively fuse features from both the encoder and decoder and project the refined feature into the clean image. Extensive experiments demonstrate that the proposed SnowFormer achieves significant improvements over other SOTA methods. Compared with SOTA single image desnowing method HDCW-Net, it boosts the PSNR metric by 9.2dB on the CSD testset. Moreover, it also achieves a 5.13dB increase in PSNR compared with general image restoration architecture NAFNet, which verifies the strong representation ability of our SnowFormer for snow removal task. The code is released in \url{https://github.com/Ephemeral182/SnowFormer}.