 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral Geospatial Inference with a Population Dynamics Foundation Model
Nov 13, 2024



Supporting the health and well-being of dynamic populations around the world requires governmental agencies, organizations and researchers to understand and reason over complex relationships between human behavior and local contexts in order to identify high-risk groups and strategically allocate limited resources. Traditional approaches to these classes of problems often entail developing manually curated, task-specific features and models to represent human behavior and the natural and built environment, which can be challenging to adapt to new, or even, related tasks. To address this, we introduce a Population Dynamics Foundation Model (PDFM) that aims to capture the relationships between diverse data modalities and is applicable to a broad range of geospatial tasks. We first construct a geo-indexed dataset for postal codes and counties across the United States, capturing rich aggregated information on human behavior from maps, busyness, and aggregated search trends, and environmental factors such as weather and air quality. We then model this data and the complex relationships between locations using a graph neural network, producing embeddings that can be adapted to a wide range of downstream tasks using relatively simple models. We evaluate the effectiveness of our approach by benchmarking it on 27 downstream tasks spanning three distinct domains: health indicators, socioeconomic factors, and environmental measurements. The approach achieves state-of-the-art performance on all 27 geospatial interpolation tasks, and on 25 out of the 27 extrapolation and super-resolution tasks. We combined the PDFM with a state-of-the-art forecasting foundation model, TimesFM, to predict unemployment and poverty, achieving performance that surpasses fully supervised forecasting. The full set of embeddings and sample code are publicly available for researchers.
Community search signatures as foundation features for human-centered geospatial modeling
Oct 30, 2024



Aggregated relative search frequencies offer a unique composite signal reflecting people's habits, concerns, interests, intents, and general information needs, which are not found in other readily available datasets. Temporal search trends have been successfully used in time series modeling across a variety of domains such as infectious diseases, unemployment rates, and retail sales. However, most existing applications require curating specialized datasets of individual keywords, queries, or query clusters, and the search data need to be temporally aligned with the outcome variable of interest. We propose a novel approach for generating an aggregated and anonymized representation of search interest as foundation features at the community level for geospatial modeling. We benchmark these features using spatial datasets across multiple domains. In zip codes with a population greater than 3000 that cover over 95% of the contiguous US population, our models for predicting missing values in a 20% set of holdout counties achieve an average $R^2$ score of 0.74 across 21 health variables, and 0.80 across 6 demographic and environmental variables. Our results demonstrate that these search features can be used for spatial predictions without strict temporal alignment, and that the resulting models outperform spatial interpolation and state of the art methods using satellite imagery features.
Crafting Tomorrow: The Influence of Design Choices on Fresh Content in Social Media Recommendation
Oct 19, 2024The rise in popularity of social media platforms, has resulted in millions of new, content pieces being created every day. This surge in content creation underscores the need to pay attention to our design choices as they can greatly impact how long content remains relevant. In today's landscape where regularly recommending new content is crucial, particularly in the absence of detailed information, a variety of factors such as UI features, algorithms and system settings contribute to shaping the journey of content across the platform. While previous research has focused on how new content affects users' experiences, this study takes a different approach by analyzing these decisions considering the content itself. Through a series of carefully crafted experiments we explore how seemingly small decisions can influence the longevity of content, measured by metrics like Content Progression (CVP) and Content Survival (CSR). We also emphasize the importance of recognizing the stages that content goes through underscoring the need to tailor strategies for each stage as a one size fits all approach may not be effective. Additionally we argue for a departure from traditional experimental setups in the study of content lifecycles, to avoid potential misunderstandings while proposing advanced techniques, to achieve greater precision and accuracy in the evaluation process.
Accelerating Reinforcement Learning Agent with EEG-based Implicit Human Feedback
Jul 17, 2020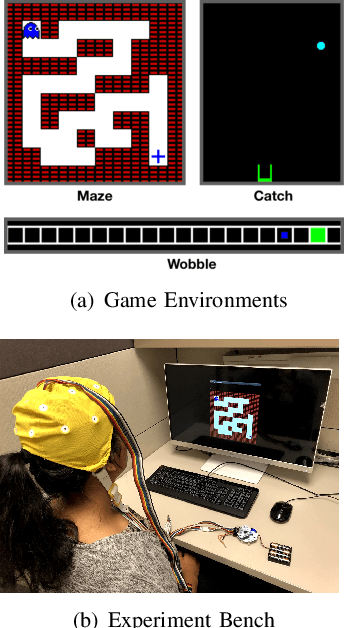

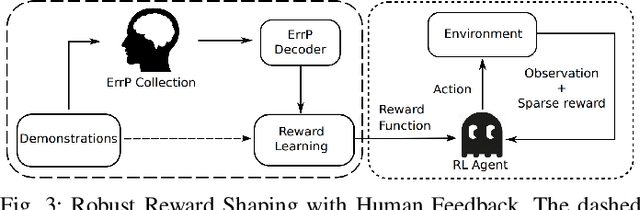
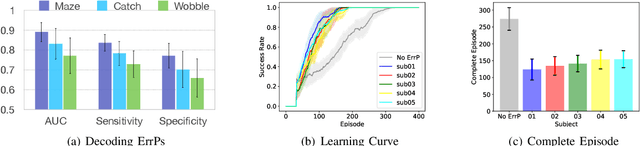
Providing Reinforcement Learning (RL) agents with human feedback can dramatically improve various aspects of learning. However, previous methods require human observer to give inputs explicitly (e.g., press buttons, voice interface), burdening the human in the loop of RL agent's learning process. Further, it is sometimes difficult or impossible to obtain the explicit human advise (feedback), e.g., autonomous driving, disabled rehabilitation, etc. In this work, we investigate capturing human's intrinsic reactions as implicit (and natural) feedback through EEG in the form of error-related potentials (ErrP), providing a natural and direct way for humans to improve the RL agent learning. As such, the human intelligence can be integrated via implicit feedback with RL algorithms to accelerate the learning of RL agent. We develop three reasonably complex 2D discrete navigational games to experimentally evaluate the overall performance of the proposed work. Major contributions of our work are as follows, (i) we propose and experimentally validate the zero-shot learning of ErrPs, where the ErrPs can be learned for one game, and transferred to other unseen games, (ii) we propose a novel RL framework for integrating implicit human feedbacks via ErrPs with RL agent, improving the label efficiency and robustness to human mistakes, and (iii) compared to prior works, we scale the application of ErrPs to reasonably complex environments, and demonstrate the significance of our approach for accelerated learning through real user experiments.
Fine-grained Sentiment Controlled Text Generation
Jun 17, 2020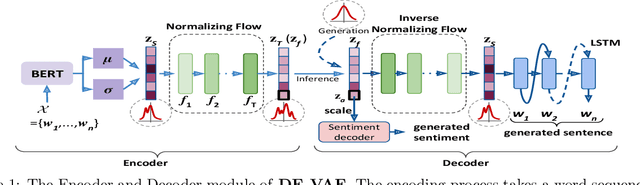
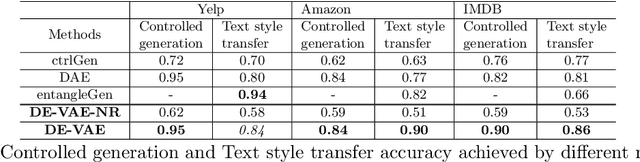
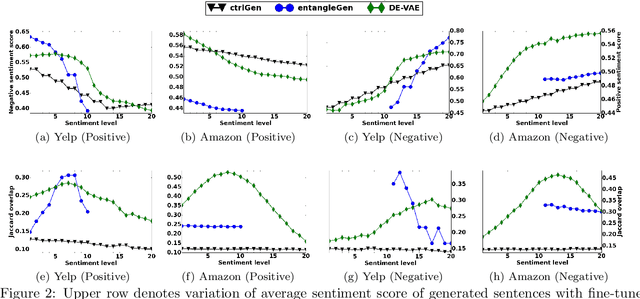

Controlled text generation techniques aim to regulate specific attributes (e.g. sentiment) while preserving the attribute independent content. The state-of-the-art approaches model the specified attribute as a structured or discrete representation while making the content representation independent of it to achieve a better control. However, disentangling the text representation into separate latent spaces overlooks complex dependencies between content and attribute, leading to generation of poorly constructed and not so meaningful sentences. Moreover, such an approach fails to provide a finer control on the degree of attribute change. To address these problems of controlled text generation, in this paper, we propose DE-VAE, a hierarchical framework which captures both information enriched entangled representation and attribute specific disentangled representation in different hierarchies. DE-VAE achieves better control of sentiment as an attribute while preserving the content by learning a suitable lossless transformation network from the disentangled sentiment space to the desired entangled representation. Through feature supervision on a single dimension of the disentangled representation, DE-VAE maps the variation of sentiment to a continuous space which helps in smoothly regulating sentiment from positive to negative and vice versa. Detailed experiments on three publicly available review datasets show the superiority of DE-VAE over recent state-of-the-art approaches.