 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatchSampler: Sampling Mini-Batches for Contrastive Learning in Vision, Language, and Graphs
Jun 06, 2023



In-Batch contrastive learning is a state-of-the-art self-supervised method that brings semantically-similar instances close while pushing dissimilar instances apart within a mini-batch. Its key to success is the negative sharing strategy, in which every instance serves as a negative for the others within the mini-batch. Recent studies aim to improve performance by sampling hard negatives \textit{within the current mini-batch}, whose quality is bounded by the mini-batch itself. In this work, we propose to improve contrastive learning by sampling mini-batches from the input data. We present BatchSampler\footnote{The code is available at \url{https://github.com/THUDM/BatchSampler}} to sample mini-batches of hard-to-distinguish (i.e., hard and true negatives to each other) instances. To make each mini-batch have fewer false negatives, we design the proximity graph of randomly-selected instances. To form the mini-batch, we leverage random walk with restart on the proximity graph to help sample hard-to-distinguish instances. BatchSampler is a simple and general technique that can be directly plugged into existing contrastive learning models in vision, language, and graphs. Extensive experiments on datasets of three modalities show that BatchSampler can consistently improve the performance of powerful contrastive models, as shown by significant improvements of SimCLR on ImageNet-100, SimCSE on STS (language), and GraphCL and MVGRL on graph datasets.
* 17 pages, 16 figures
GraphMAE2: A Decoding-Enhanced Masked Self-Supervised Graph Learner
Apr 10, 2023



Graph self-supervised learning (SSL), including contrastive and generative approaches, offers great potential to address the fundamental challenge of label scarcity in real-world graph data. Among both sets of graph SSL techniques, the masked graph autoencoders (e.g., GraphMAE)--one type of generative method--have recently produced promising results. The idea behind this is to reconstruct the node features (or structures)--that are randomly masked from the input--with the autoencoder architecture. However, the performance of masked feature reconstruction naturally relies on the discriminability of the input features and is usually vulnerable to disturbance in the features. In this paper, we present a masked self-supervised learning framework GraphMAE2 with the goal of overcoming this issue. The idea is to impose regularization on feature reconstruction for graph SSL. Specifically, we design the strategies of multi-view random re-mask decoding and latent representation prediction to regularize the feature reconstruction. The multi-view random re-mask decoding is to introduce randomness into reconstruction in the feature space, while the latent representation prediction is to enforce the reconstruction in the embedding space. Extensive experiments show that GraphMAE2 can consistently generate top results on various public datasets, including at least 2.45% improvements over state-of-the-art baselines on ogbn-Papers100M with 111M nodes and 1.6B edges.
Mask and Reason: Pre-Training Knowledge Graph Transformers for Complex Logical Queries
Aug 16, 2022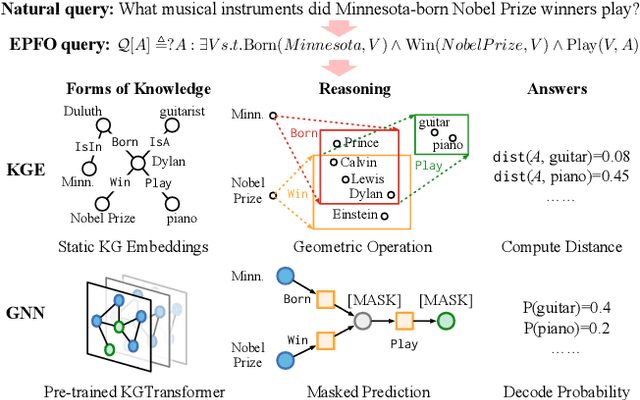
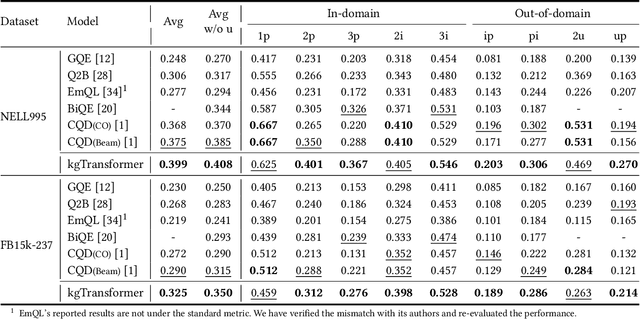
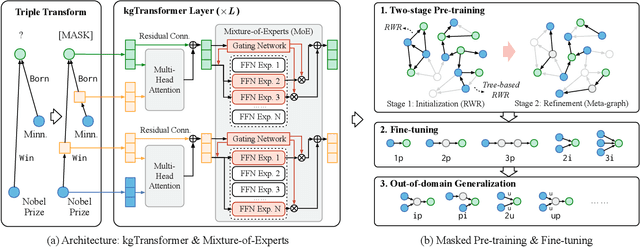
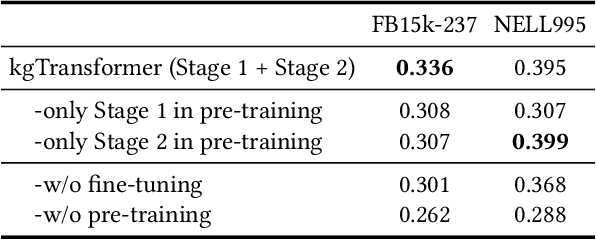
Knowledge graph (KG) embeddings have been a mainstream approach for reasoning over incomplete KGs. However, limited by their inherently shallow and static architectures, they can hardly deal with the rising focus on complex logical queries, which comprise logical operators, imputed edges, multiple source entities, and unknown intermediate entities. In this work, we present the Knowledge Graph Transformer (kgTransformer) with masked pre-training and fine-tuning strategies. We design a KG triple transformation method to enable Transformer to handle KGs, which is further strengthened by the Mixture-of-Experts (MoE) sparse activation. We then formulate the complex logical queries as masked prediction and introduce a two-stage masked pre-training strategy to improve transferability and generalizability. Extensive experiments on two benchmarks demonstrate that kgTransformer can consistently outperform both KG embedding-based baselines and advanced encoders on nine in-domain and out-of-domain reasoning tasks. Additionally, kgTransformer can reason with explainability via providing the full reasoning paths to interpret given answers.
GACT: Activation Compressed Training for General Architectures
Jun 28, 2022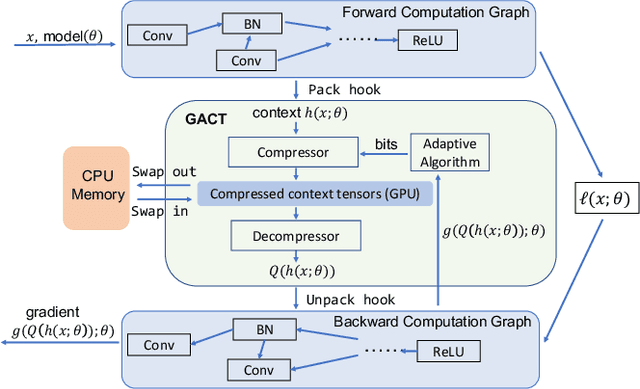
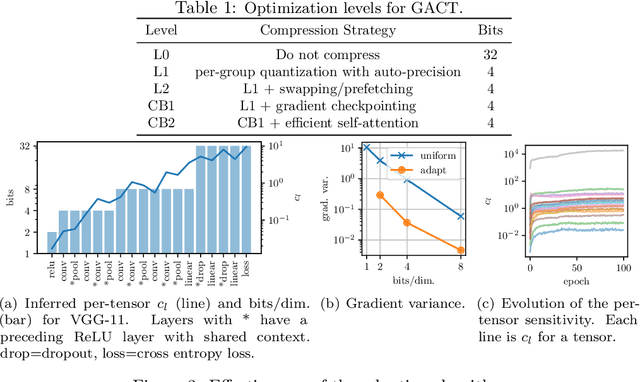

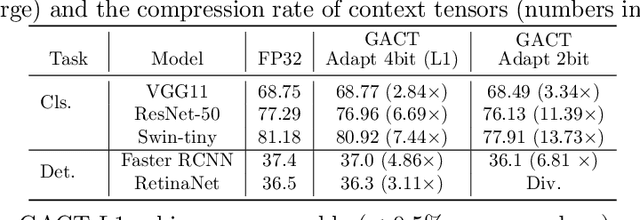
Training large neural network (NN) models requires extensive memory resources, and Activation Compressed Training (ACT) is a promising approach to reduce training memory footprint. This paper presents GACT, an ACT framework to support a broad range of machine learning tasks for generic NN architectures with limited domain knowledge. By analyzing a linearized version of ACT's approximate gradient, we prove the convergence of GACT without prior knowledge on operator type or model architecture. To make training stable, we propose an algorithm that decides the compression ratio for each tensor by estimating its impact on the gradient at run time. We implement GACT as a PyTorch library that readily applies to any NN architecture. GACT reduces the activation memory for convolutional NNs, transformers, and graph NNs by up to 8.1x, enabling training with a 4.2x to 24.7x larger batch size, with negligible accuracy loss.
Rethinking the Setting of Semi-supervised Learning on Graphs
May 28, 2022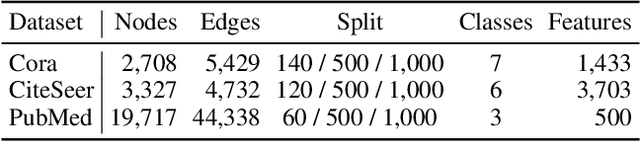
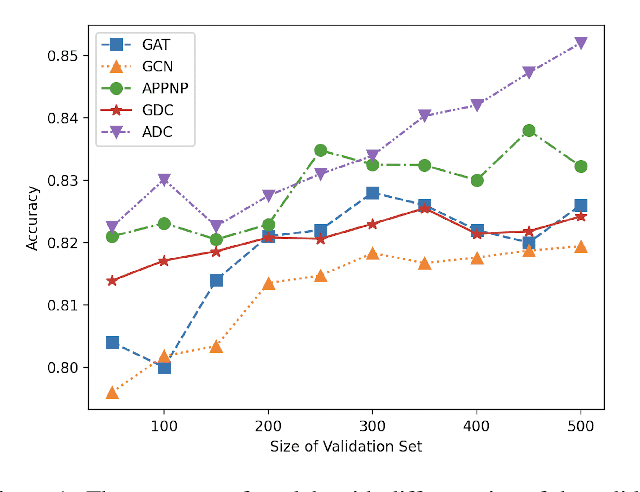
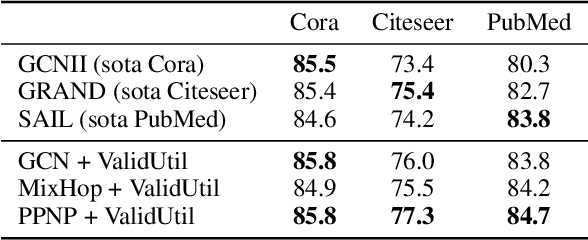
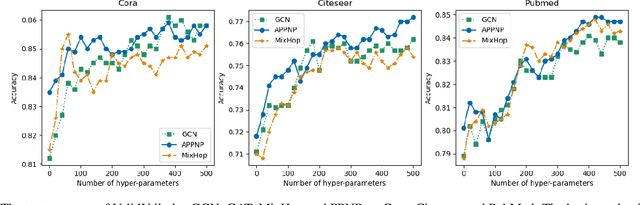
We argue that the present setting of semisupervised learning on graphs may result in unfair comparisons, due to its potential risk of over-tuning hyper-parameters for models. In this paper, we highlight the significant influence of tuning hyper-parameters, which leverages the label information in the validation set to improve the performance. To explore the limit of over-tuning hyperparameters, we propose ValidUtil, an approach to fully utilize the label information in the validation set through an extra group of hyper-parameters. With ValidUtil, even GCN can easily get high accuracy of 85.8% on Cora. To avoid over-tuning, we merge the training set and the validation set and construct an i.i.d. graph benchmark (IGB) consisting of 4 datasets. Each dataset contains 100 i.i.d. graphs sampled from a large graph to reduce the evaluation variance. Our experiments suggest that IGB is a more stable benchmark than previous datasets for semisupervised learning on graphs.
GraphMAE: Self-Supervised Masked Graph Autoencoders
May 24, 2022
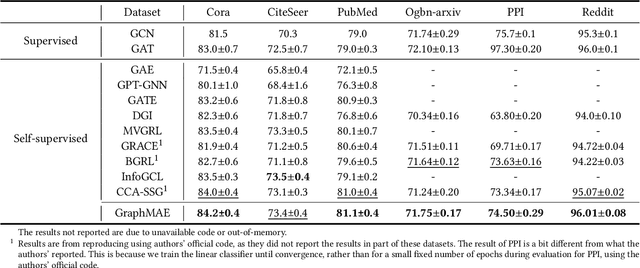
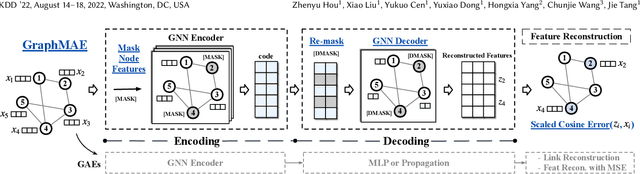
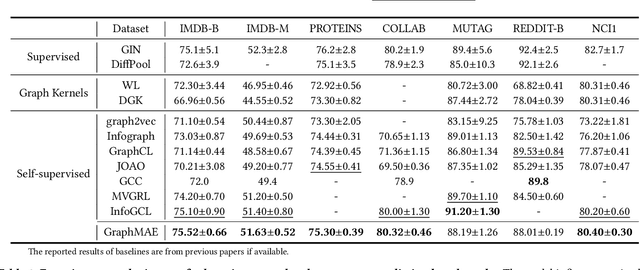
Self-supervised learning (SSL) has been extensively explored in recent years. Particularly, generative SSL has seen emerging success in natural language processing and other fields, such as the wide adoption of BERT and GPT. Despite this, contrastive learning--which heavily relies on structural data augmentation and complicated training strategies--has been the dominant approach in graph SSL, while the progress of generative SSL on graphs, especially graph autoencoders (GAEs), has thus far not reached the potential as promised in other fields. In this paper, we identify and examine the issues that negatively impact the development of GAEs, including their reconstruction objective, training robustness, and error metric. We present a masked graph autoencoder GraphMAE that mitigates these issues for generative self-supervised graph learning. Instead of reconstructing structures, we propose to focus on feature reconstruction with both a masking strategy and scaled cosine error that benefit the robust training of GraphMAE. We conduct extensive experiments on 21 public datasets for three different graph learning tasks. The results manifest that GraphMAE--a simple graph autoencoder with our careful designs--can consistently generate outperformance over both contrastive and generative state-of-the-art baselines. This study provides an understanding of graph autoencoders and demonstrates the potential of generative self-supervised learning on graphs.
Improving the Training of Graph Neural Networks with Consistency Regularization
Dec 08, 2021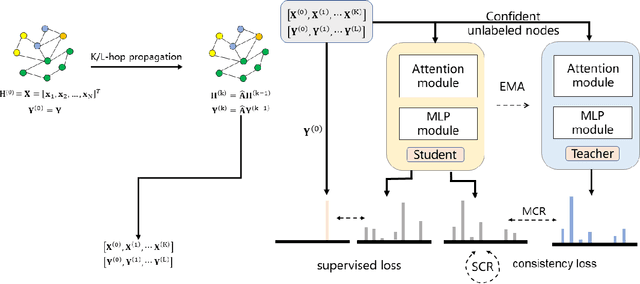
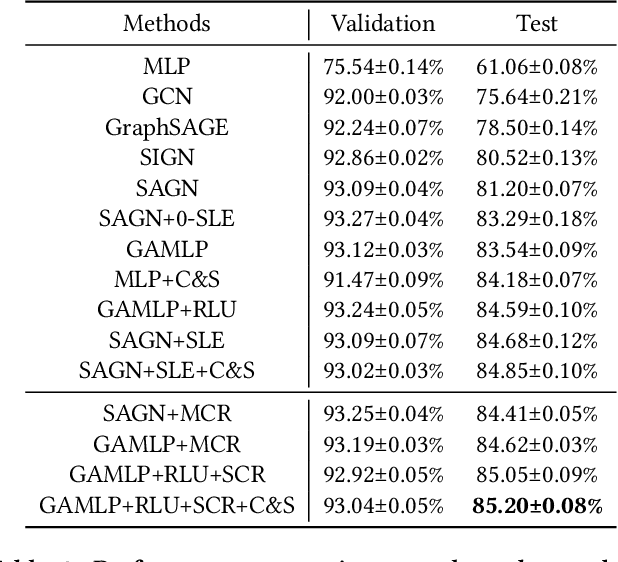
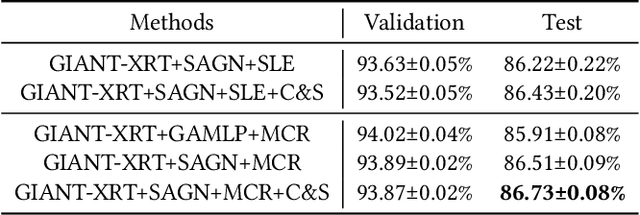
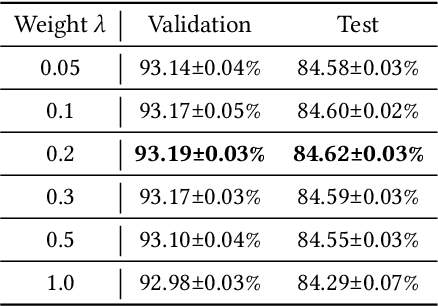
Graph neural networks (GNNs) have achieved notable success in the semi-supervised learning scenario. The message passing mechanism in graph neural networks helps unlabeled nodes gather supervision signals from their labeled neighbors. In this work, we investigate how consistency regularization, one of widely adopted semi-supervised learning methods, can help improve the performance of graph neural networks. We revisit two methods of consistency regularization for graph neural networks. One is simple consistency regularization (SCR), and the other is mean-teacher consistency regularization (MCR). We combine the consistency regularization methods with two state-of-the-art GNNs and conduct experiments on the ogbn-products dataset. With the consistency regularization, the performance of state-of-the-art GNNs can be improved by 0.3% on the ogbn-products dataset of Open Graph Benchmark (OGB) both with and without external data.
Graph Robustness Benchmark: Benchmarking the Adversarial Robustness of Graph Machine Learning
Nov 08, 2021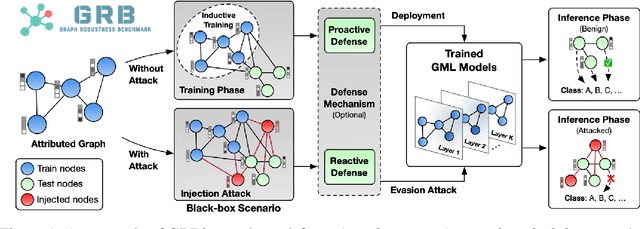

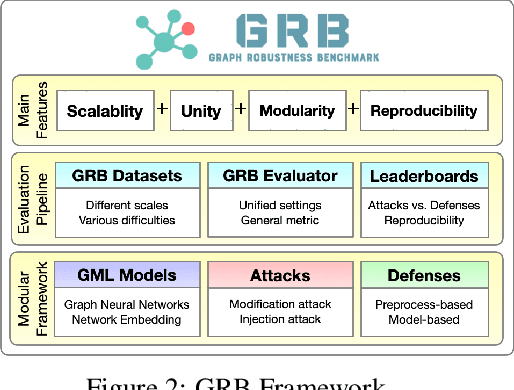
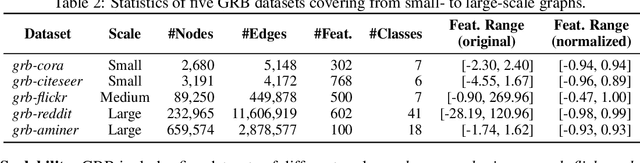
Adversarial attacks on graphs have posed a major threat to the robustness of graph machine learning (GML) models. Naturally, there is an ever-escalating arms race between attackers and defenders. However, the strategies behind both sides are often not fairly compared under the same and realistic conditions. To bridge this gap, we present the Graph Robustness Benchmark (GRB) with the goal of providing a scalable, unified, modular, and reproducible evaluation for the adversarial robustness of GML models. GRB standardizes the process of attacks and defenses by 1) developing scalable and diverse datasets, 2) modularizing the attack and defense implementations, and 3) unifying the evaluation protocol in refined scenarios. By leveraging the GRB pipeline, the end-users can focus on the development of robust GML models with automated data processing and experimental evaluations. To support open and reproducible research on graph adversarial learning, GRB also hosts public leaderboards across different scenarios. As a starting point, we conduct extensive experiments to benchmark baseline techniques. GRB is open-source and welcomes contributions from the community. Datasets, codes, leaderboards are available at https://cogdl.ai/grb/home.
CogDL: An Extensive Toolkit for Deep Learning on Graphs
Mar 01, 2021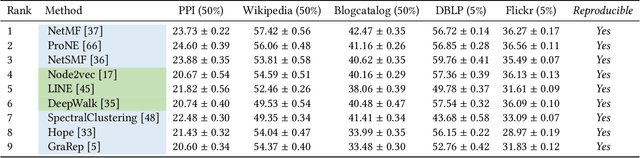
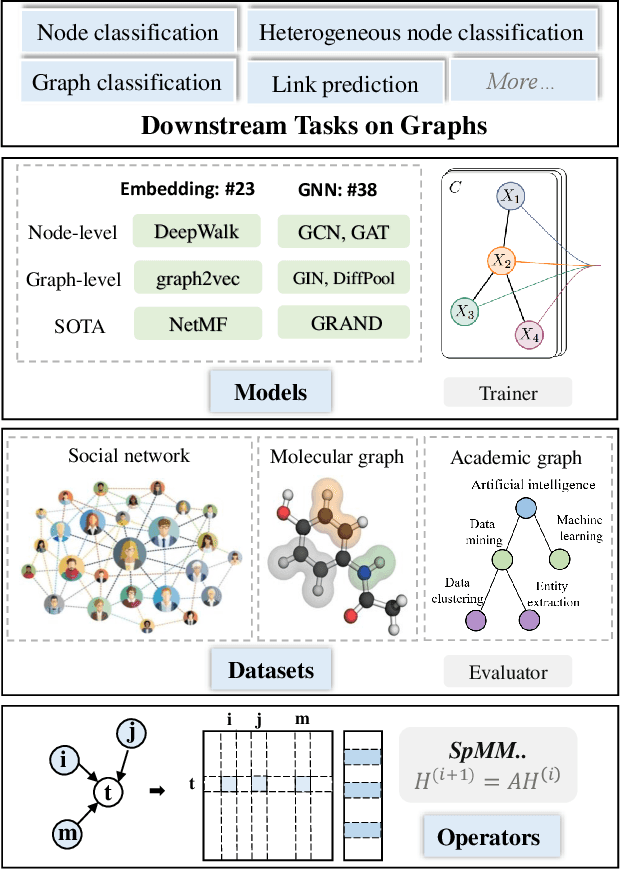
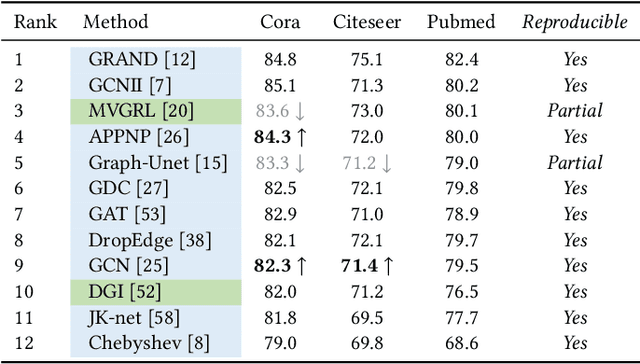
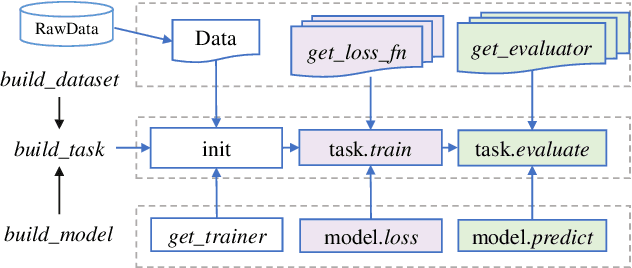
Graph representation learning aims to learn low-dimensional node embeddings for graphs. It is used in several real-world applications such as social network analysis and large-scale recommender systems. In this paper, we introduce CogDL, an extensive research toolkit for deep learning on graphs that allows researchers and developers to easily conduct experiments and build applications. It provides standard training and evaluation for the most important tasks in the graph domain, including node classification, link prediction, graph classification, and other graph tasks. For each task, it offers implementations of state-of-the-art models. The models in our toolkit are divided into two major parts, graph embedding methods and graph neural networks. Most of the graph embedding methods learn node-level or graph-level representations in an unsupervised way and preserves the graph properties such as structural information, while graph neural networks capture node features and work in semi-supervised or self-supervised settings. All models implemented in our toolkit can be easily reproducible for leaderboard results. Most models in CogDL are developed on top of PyTorch, and users can leverage the advantages of PyTorch to implement their own models. Furthermore, we demonstrate the effectiveness of CogDL for real-world applications in AMiner, which is a large academic database and system.
Controllable Multi-Interest Framework for Recommendation
May 19, 2020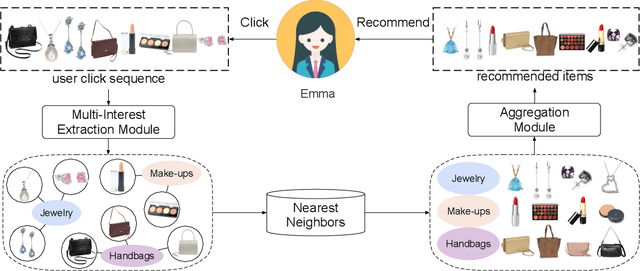
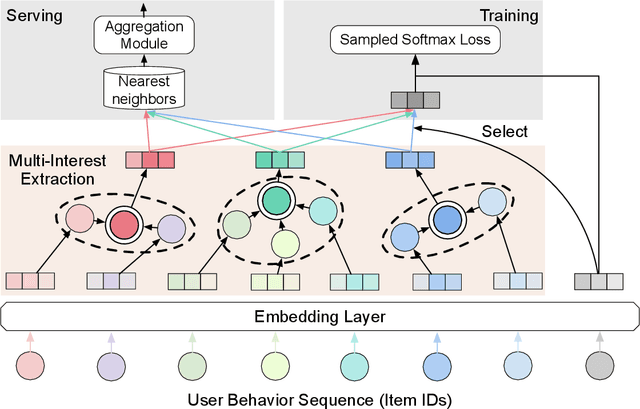

Recently, neural networks have been widely used in e-commerce recommender systems, owing to the rapid development of deep learning. We formalize the recommender system as a sequential recommendation problem, intending to predict the next items that the user might be interacted with. Recent works usually give an overall embedding from a user's behavior sequence. However, a unified user embedding cannot reflect the user's multiple interests during a period. In this paper, we propose a novel controllable multi-interest framework for the sequential recommendation, called ComiRec. Our multi-interest module captures multiple interests from user behavior sequences, which can be exploited for retrieving candidate items from the large-scale item pool. These items are then fed into an aggregation module to obtain the overall recommendation. The aggregation module leverages a controllable factor to balance the recommendation accuracy and diversity. We conduct experiments for the sequential recommendation on two real-world datasets, Amazon and Taobao. Experimental results demonstrate that our framework achieves significant improvements over state-of-the-art models. Our framework has also been successfully deployed on the offline Alibaba distributed cloud platform.