 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Preferences Are Created Equal: Stability-Aware and Gradient-Efficient Alignment for Reasoning Models
Feb 01, 2026Preference-based alignment is pivotal for training large reasoning models; however, standard methods like Direct Preference Optimization (DPO) typically treat all preference pairs uniformly, overlooking the evolving utility of training instances. This static approach often leads to inefficient or unstable optimization, as it wastes computation on trivial pairs with negligible gradients and suffers from noise induced by samples near uncertain decision boundaries. Facing these challenges, we propose SAGE (Stability-Aware Gradient Efficiency), a dynamic framework designed to enhance alignment reliability by maximizing the Signal-to-Noise Ratio of policy updates. Concretely, SAGE integrates a coarse-grained curriculum mechanism that refreshes candidate pools based on model competence with a fine-grained, stability-aware scoring function that prioritizes informative, confident errors while filtering out unstable samples. Experiments on multiple mathematical reasoning benchmarks demonstrate that SAGE significantly accelerates convergence and outperforms static baselines, highlighting the critical role of policy-aware, stability-conscious data selection in reasoning alignment.
DTP: A Simple yet Effective Distracting Token Pruning Framework for Vision-Language Action Models
Jan 22, 2026Vision-Language Action (VLA) models have shown remarkable progress in robotic manipulation by leveraging the powerful perception abilities of Vision-Language Models (VLMs) to understand environments and directly output actions. However, by default, VLA models may overly attend to image tokens in the task-irrelevant region, which we describe as 'distracting tokens'. This behavior can disturb the model from the generation of the desired action tokens in each step, affecting the success rate of tasks. In this paper, we introduce a simple yet effective plug-and-play Distracting Token Pruning (DTP) framework, which dynamically detects and prunes these distracting image tokens. By correcting the model's visual attention patterns, we aim to improve the task success rate, as well as exploring the performance upper boundaries of the model without altering its original architecture or adding additional inputs. Experiments on the SIMPLER Benchmark (Li et al., 2024) show that our method consistently achieving relative improvements in task success rates across different types of novel VLA models, demonstrating generalizability to transformer-based VLAs. Further analysis reveals a negative correlation between the task success rate and the amount of attentions in the task-irrelevant region for all models tested, highlighting a common phenomenon of VLA models that could guide future research. We also publish our code at: https://anonymous.4open.science/r/CBD3.
Dr. Assistant: Enhancing Clinical Diagnostic Inquiry via Structured Diagnostic Reasoning Data and Reinforcement Learning
Jan 20, 2026Clinical Decision Support Systems (CDSSs) provide reasoning and inquiry guidance for physicians, yet they face notable challenges, including high maintenance costs and low generalization capability. Recently, Large Language Models (LLMs) have been widely adopted in healthcare due to their extensive knowledge reserves, retrieval, and communication capabilities. While LLMs show promise and excel at medical benchmarks, their diagnostic reasoning and inquiry skills are constrained. To mitigate this issue, we propose (1) Clinical Diagnostic Reasoning Data (CDRD) structure to capture abstract clinical reasoning logic, and a pipeline for its construction, and (2) the Dr. Assistant, a clinical diagnostic model equipped with clinical reasoning and inquiry skills. Its training involves a two-stage process: SFT, followed by RL with a tailored reward function. We also introduce a benchmark to evaluate both diagnostic reasoning and inquiry. Our experiments demonstrate that the Dr. Assistant outperforms open-source models and achieves competitive performance to closed-source models, providing an effective solution for clinical diagnostic inquiry guidance.
Agentic-R: Learning to Retrieve for Agentic Search
Jan 17, 2026Agentic search has recently emerged as a powerful paradigm, where an agent interleaves multi-step reasoning with on-demand retrieval to solve complex questions. Despite its success, how to design a retriever for agentic search remains largely underexplored. Existing search agents typically rely on similarity-based retrievers, while similar passages are not always useful for final answer generation. In this paper, we propose a novel retriever training framework tailored for agentic search. Unlike retrievers designed for single-turn retrieval-augmented generation (RAG) that only rely on local passage utility, we propose to use both local query-passage relevance and global answer correctness to measure passage utility in a multi-turn agentic search. We further introduce an iterative training strategy, where the search agent and the retriever are optimized bidirectionally and iteratively. Different from RAG retrievers that are only trained once with fixed questions, our retriever is continuously improved using evolving and higher-quality queries from the agent. Extensive experiments on seven single-hop and multi-hop QA benchmarks demonstrate that our retriever, termed \ours{}, consistently outperforms strong baselines across different search agents. Our codes are available at: https://github.com/8421BCD/Agentic-R.
Adversarial Yet Cooperative: Multi-Perspective Reasoning in Retrieved-Augmented Language Models
Jan 08, 2026Recent advances in synergizing large reasoning models (LRMs) with retrieval-augmented generation (RAG) have shown promising results, yet two critical challenges remain: (1) reasoning models typically operate from a single, unchallenged perspective, limiting their ability to conduct deep, self-correcting reasoning over external documents, and (2) existing training paradigms rely excessively on outcome-oriented rewards, which provide insufficient signal for shaping the complex, multi-step reasoning process. To address these issues, we propose an Reasoner-Verifier framework named Adversarial Reasoning RAG (ARR). The Reasoner and Verifier engage in reasoning on retrieved evidence and critiquing each other's logic while being guided by process-aware advantage that requires no external scoring model. This reward combines explicit observational signals with internal model uncertainty to jointly optimize reasoning fidelity and verification rigor. Experiments on multiple benchmarks demonstrate the effectiveness of our method.
Mortar: Evolving Mechanics for Automatic Game Design
Dec 31, 2025We present Mortar, a system for autonomously evolving game mechanics for automatic game design. Game mechanics define the rules and interactions that govern gameplay, and designing them manually is a time-consuming and expert-driven process. Mortar combines a quality-diversity algorithm with a large language model to explore a diverse set of mechanics, which are evaluated by synthesising complete games that incorporate both evolved mechanics and those drawn from an archive. The mechanics are evaluated by composing complete games through a tree search procedure, where the resulting games are evaluated by their ability to preserve a skill-based ordering over players -- that is, whether stronger players consistently outperform weaker ones. We assess the mechanics based on their contribution towards the skill-based ordering score in the game. We demonstrate that Mortar produces games that appear diverse and playable, and mechanics that contribute more towards the skill-based ordering score in the game. We perform ablation studies to assess the role of each system component and a user study to evaluate the games based on human feedback.
Solver-Independent Automated Problem Formulation via LLMs for High-Cost Simulation-Driven Design
Dec 21, 2025In the high-cost simulation-driven design domain, translating ambiguous design requirements into a mathematical optimization formulation is a bottleneck for optimizing product performance. This process is time-consuming and heavily reliant on expert knowledge. While large language models (LLMs) offer potential for automating this task, existing approaches either suffer from poor formalization that fails to accurately align with the design intent or rely on solver feedback for data filtering, which is unavailable due to the high simulation costs. To address this challenge, we propose APF, a framework for solver-independent, automated problem formulation via LLMs designed to automatically convert engineers' natural language requirements into executable optimization models. The core of this framework is an innovative pipeline for automatically generating high-quality data, which overcomes the difficulty of constructing suitable fine-tuning datasets in the absence of high-cost solver feedback with the help of data generation and test instance annotation. The generated high-quality dataset is used to perform supervised fine-tuning on LLMs, significantly enhancing their ability to generate accurate and executable optimization problem formulations. Experimental results on antenna design demonstrate that APF significantly outperforms the existing methods in both the accuracy of requirement formalization and the quality of resulting radiation efficiency curves in meeting the design goals.
Efficient Thought Space Exploration through Strategic Intervention
Nov 13, 2025While large language models (LLMs) demonstrate emerging reasoning capabilities, current inference-time expansion methods incur prohibitive computational costs by exhaustive sampling. Through analyzing decoding trajectories, we observe that most next-token predictions align well with the golden output, except for a few critical tokens that lead to deviations. Inspired by this phenomenon, we propose a novel Hint-Practice Reasoning (HPR) framework that operationalizes this insight through two synergistic components: 1) a hinter (powerful LLM) that provides probabilistic guidance at critical decision points, and 2) a practitioner (efficient smaller model) that executes major reasoning steps. The framework's core innovation lies in Distributional Inconsistency Reduction (DIR), a theoretically-grounded metric that dynamically identifies intervention points by quantifying the divergence between practitioner's reasoning trajectory and hinter's expected distribution in a tree-structured probabilistic space. Through iterative tree updates guided by DIR, HPR reweights promising reasoning paths while deprioritizing low-probability branches. Experiments across arithmetic and commonsense reasoning benchmarks demonstrate HPR's state-of-the-art efficiency-accuracy tradeoffs: it achieves comparable performance to self-consistency and MCTS baselines while decoding only 1/5 tokens, and outperforms existing methods by at most 5.1% absolute accuracy while maintaining similar or lower FLOPs.
AdaSwitch: Adaptive Switching Generation for Knowledge Distillation
Oct 09, 2025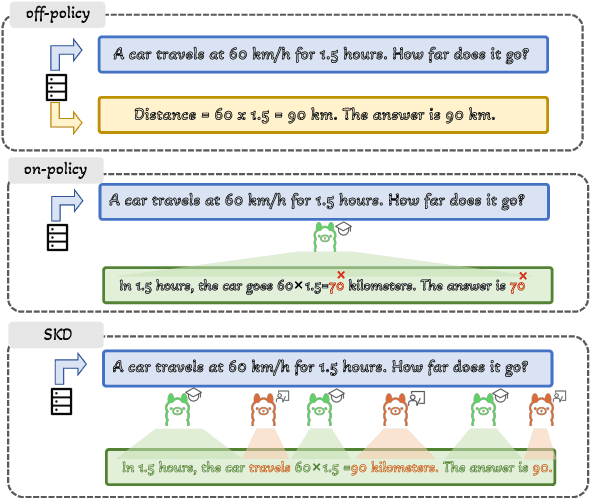
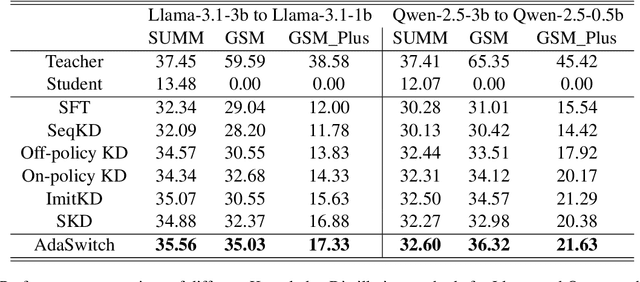
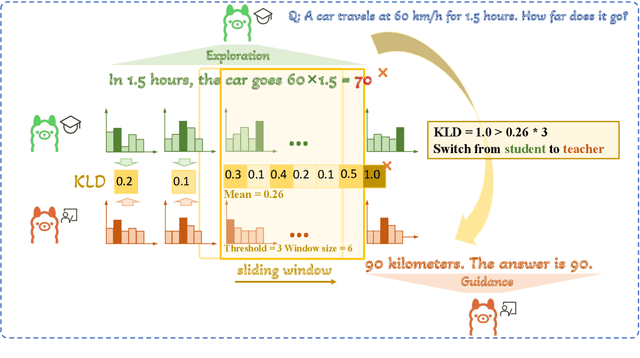
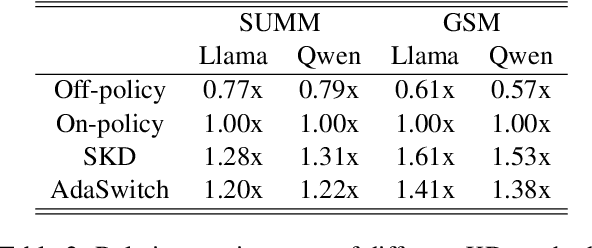
Small language models (SLMs) are crucial for applications with strict latency and computational constraints, yet achieving high performance remains challenging. Knowledge distillation (KD) can transfer capabilities from large teacher models, but existing methods involve trade-offs: off-policy distillation provides high-quality supervision but introduces a training-inference mismatch, while on-policy approaches maintain consistency but rely on low-quality student outputs. To address these issues, we propose AdaSwitch, a novel approach that dynamically combines on-policy and off-policy generation at the token level. AdaSwitch allows the student to first explore its own predictions and then selectively integrate teacher guidance based on real-time quality assessment. This approach simultaneously preserves consistency and maintains supervision quality. Experiments on three datasets with two teacher-student LLM pairs demonstrate that AdaSwitch consistently improves accuracy, offering a practical and effective method for distilling SLMs with acceptable additional overhead.
OS-R1: Agentic Operating System Kernel Tuning with Reinforcement Learning
Aug 18, 2025Linux kernel tuning is essential for optimizing operating system (OS) performance. However, existing methods often face challenges in terms of efficiency, scalability, and generalization. This paper introduces OS-R1, an agentic Linux kernel tuning framework powered by rule-based reinforcement learning (RL). By abstracting the kernel configuration space as an RL environment, OS-R1 facilitates efficient exploration by large language models (LLMs) and ensures accurate configuration modifications. Additionally, custom reward functions are designed to enhance reasoning standardization, configuration modification accuracy, and system performance awareness of the LLMs. Furthermore, we propose a two-phase training process that accelerates convergence and minimizes retraining across diverse tuning scenarios. Experimental results show that OS-R1 significantly outperforms existing baseline methods, achieving up to 5.6% performance improvement over heuristic tuning and maintaining high data efficiency. Notably, OS-R1 is adaptable across various real-world applications, demonstrating its potential for practical deployment in diverse environments. Our dataset and code are publicly available at https://github.com/LHY-24/OS-R1.