 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActVAR: Activating Mixtures of Weights and Tokens for Efficient Visual Autoregressive Generation
Nov 17, 2025Visual Autoregressive (VAR) models enable efficient image generation via next-scale prediction but face escalating computational costs as sequence length grows. Existing static pruning methods degrade performance by permanently removing weights or tokens, disrupting pretrained dependencies. To address this, we propose ActVAR, a dynamic activation framework that introduces dual sparsity across model weights and token sequences to enhance efficiency without sacrificing capacity. ActVAR decomposes feedforward networks (FFNs) into lightweight expert sub-networks and employs a learnable router to dynamically select token-specific expert subsets based on content. Simultaneously, a gated token selector identifies high-update-potential tokens for computation while reconstructing unselected tokens to preserve global context and sequence alignment. Training employs a two-stage knowledge distillation strategy, where the original VAR model supervises the learning of routing and gating policies to align with pretrained knowledge. Experiments on the ImageNet $256\times 256$ benchmark demonstrate that ActVAR achieves up to $21.2\%$ FLOPs reduction with minimal performance degradation.
TimeSearch-R: Adaptive Temporal Search for Long-Form Video Understanding via Self-Verification Reinforcement Learning
Nov 07, 2025Temporal search aims to identify a minimal set of relevant frames from tens of thousands based on a given query, serving as a foundation for accurate long-form video understanding. Existing works attempt to progressively narrow the search space. However, these approaches typically rely on a hand-crafted search process, lacking end-to-end optimization for learning optimal search strategies. In this paper, we propose TimeSearch-R, which reformulates temporal search as interleaved text-video thinking, seamlessly integrating searching video clips into the reasoning process through reinforcement learning (RL). However, applying RL training methods, such as Group Relative Policy Optimization (GRPO), to video reasoning can result in unsupervised intermediate search decisions. This leads to insufficient exploration of the video content and inconsistent logical reasoning. To address these issues, we introduce GRPO with Completeness Self-Verification (GRPO-CSV), which gathers searched video frames from the interleaved reasoning process and utilizes the same policy model to verify the adequacy of searched frames, thereby improving the completeness of video reasoning. Additionally, we construct datasets specifically designed for the SFT cold-start and RL training of GRPO-CSV, filtering out samples with weak temporal dependencies to enhance task difficulty and improve temporal search capabilities. Extensive experiments demonstrate that TimeSearch-R achieves significant improvements on temporal search benchmarks such as Haystack-LVBench and Haystack-Ego4D, as well as long-form video understanding benchmarks like VideoMME and MLVU. Notably, TimeSearch-R establishes a new state-of-the-art on LongVideoBench with 4.1% improvement over the base model Qwen2.5-VL and 2.0% over the advanced video reasoning model Video-R1. Our code is available at https://github.com/Time-Search/TimeSearch-R.
iFlyBot-VLM Technical Report
Nov 07, 2025



We introduce iFlyBot-VLM, a general-purpose Vision-Language Model (VLM) used to improve the domain of Embodied Intelligence. The central objective of iFlyBot-VLM is to bridge the cross-modal semantic gap between high-dimensional environmental perception and low-level robotic motion control. To this end, the model abstracts complex visual and spatial information into a body-agnostic and transferable Operational Language, thereby enabling seamless perception-action closed-loop coordination across diverse robotic platforms. The architecture of iFlyBot-VLM is systematically designed to realize four key functional capabilities essential for embodied intelligence: 1) Spatial Understanding and Metric Reasoning; 2) Interactive Target Grounding; 3) Action Abstraction and Control Parameter Generation; 4) Task Planning and Skill Sequencing. We envision iFlyBot-VLM as a scalable and generalizable foundation model for embodied AI, facilitating the progression from specialized task-oriented systems toward generalist, cognitively capable agents. We conducted evaluations on 10 current mainstream embodied intelligence-related VLM benchmark datasets, such as Blink and Where2Place, and achieved optimal performance while preserving the model's general capabilities. We will publicly release both the training data and model weights to foster further research and development in the field of Embodied Intelligence.
OmniHuman-1.5: Instilling an Active Mind in Avatars via Cognitive Simulation
Aug 26, 2025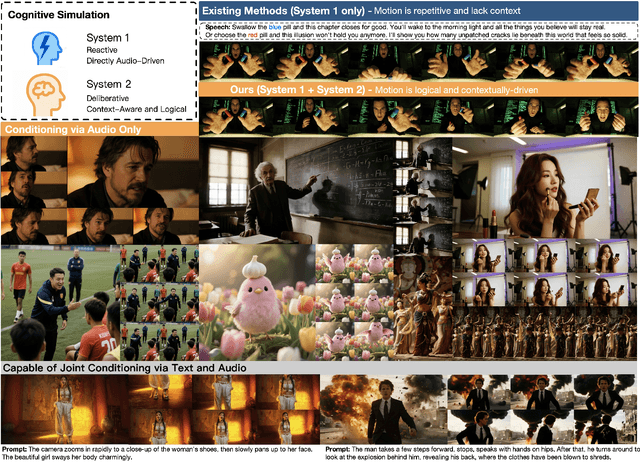
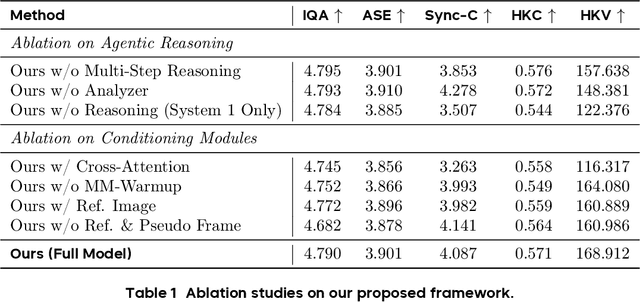
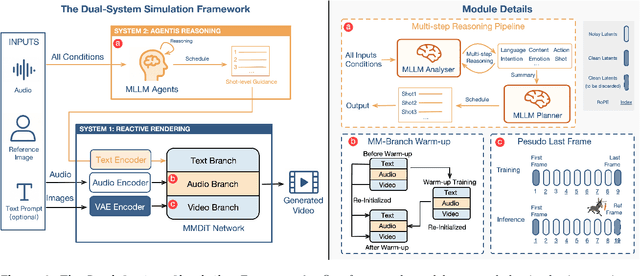

Existing video avatar models can produce fluid human animations, yet they struggle to move beyond mere physical likeness to capture a character's authentic essence. Their motions typically synchronize with low-level cues like audio rhythm, lacking a deeper semantic understanding of emotion, intent, or context. To bridge this gap, \textbf{we propose a framework designed to generate character animations that are not only physically plausible but also semantically coherent and expressive.} Our model, \textbf{OmniHuman-1.5}, is built upon two key technical contributions. First, we leverage Multimodal Large Language Models to synthesize a structured textual representation of conditions that provides high-level semantic guidance. This guidance steers our motion generator beyond simplistic rhythmic synchronization, enabling the production of actions that are contextually and emotionally resonant. Second, to ensure the effective fusion of these multimodal inputs and mitigate inter-modality conflicts, we introduce a specialized Multimodal DiT architecture with a novel Pseudo Last Frame design. The synergy of these components allows our model to accurately interpret the joint semantics of audio, images, and text, thereby generating motions that are deeply coherent with the character, scene, and linguistic content. Extensive experiments demonstrate that our model achieves leading performance across a comprehensive set of metrics, including lip-sync accuracy, video quality, motion naturalness and semantic consistency with textual prompts. Furthermore, our approach shows remarkable extensibility to complex scenarios, such as those involving multi-person and non-human subjects. Homepage: \href{https://omnihuman-lab.github.io/v1_5/}
THAT: Token-wise High-frequency Augmentation Transformer for Hyperspectral Pansharpening
Aug 11, 2025Transformer-based methods have demonstrated strong potential in hyperspectral pansharpening by modeling long-range dependencies. However, their effectiveness is often limited by redundant token representations and a lack of multi-scale feature modeling. Hyperspectral images exhibit intrinsic spectral priors (e.g., abundance sparsity) and spatial priors (e.g., non-local similarity), which are critical for accurate reconstruction. From a spectral-spatial perspective, Vision Transformers (ViTs) face two major limitations: they struggle to preserve high-frequency components--such as material edges and texture transitions--and suffer from attention dispersion across redundant tokens. These issues stem from the global self-attention mechanism, which tends to dilute high-frequency signals and overlook localized details. To address these challenges, we propose the Token-wise High-frequency Augmentation Transformer (THAT), a novel framework designed to enhance hyperspectral pansharpening through improved high-frequency feature representation and token selection. Specifically, THAT introduces: (1) Pivotal Token Selective Attention (PTSA) to prioritize informative tokens and suppress redundancy; (2) a Multi-level Variance-aware Feed-forward Network (MVFN) to enhance high-frequency detail learning. Experiments on standard benchmarks show that THAT achieves state-of-the-art performance with improved reconstruction quality and efficiency. The source code is available at https://github.com/kailuo93/THAT.
DiffCap: Diffusion-based Real-time Human Motion Capture using Sparse IMUs and a Monocular Camera
Aug 08, 2025



Combining sparse IMUs and a monocular camera is a new promising setting to perform real-time human motion capture. This paper proposes a diffusion-based solution to learn human motion priors and fuse the two modalities of signals together seamlessly in a unified framework. By delicately considering the characteristics of the two signals, the sequential visual information is considered as a whole and transformed into a condition embedding, while the inertial measurement is concatenated with the noisy body pose frame by frame to construct a sequential input for the diffusion model. Firstly, we observe that the visual information may be unavailable in some frames due to occlusions or subjects moving out of the camera view. Thus incorporating the sequential visual features as a whole to get a single feature embedding is robust to the occasional degenerations of visual information in those frames. On the other hand, the IMU measurements are robust to occlusions and always stable when signal transmission has no problem. So incorporating them frame-wisely could better explore the temporal information for the system. Experiments have demonstrated the effectiveness of the system design and its state-of-the-art performance in pose estimation compared with the previous works. Our codes are available for research at https://shaohua-pan.github.io/diffcap-page.
MedReadCtrl: Personalizing medical text generation with readability-controlled instruction learning
Jul 10, 2025Generative AI has demonstrated strong potential in healthcare, from clinical decision support to patient-facing chatbots that improve outcomes. A critical challenge for deployment is effective human-AI communication, where content must be both personalized and understandable. We introduce MedReadCtrl, a readability-controlled instruction tuning framework that enables LLMs to adjust output complexity without compromising meaning. Evaluations of nine datasets and three tasks across medical and general domains show that MedReadCtrl achieves significantly lower readability instruction-following errors than GPT-4 (e.g., 1.39 vs. 1.59 on ReadMe, p<0.001) and delivers substantial gains on unseen clinical tasks (e.g., +14.7 ROUGE-L, +6.18 SARI on MTSamples). Experts consistently preferred MedReadCtrl (71.7% vs. 23.3%), especially at low literacy levels. These gains reflect MedReadCtrl's ability to restructure clinical content into accessible, readability-aligned language while preserving medical intent, offering a scalable solution to support patient education and expand equitable access to AI-enabled care.
Beyond Attention or Similarity: Maximizing Conditional Diversity for Token Pruning in MLLMs
Jun 12, 2025



In multimodal large language models (MLLMs), the length of input visual tokens is often significantly greater than that of their textual counterparts, leading to a high inference cost. Many works aim to address this issue by removing redundant visual tokens. However, current approaches either rely on attention-based pruning, which retains numerous duplicate tokens, or use similarity-based pruning, overlooking the instruction relevance, consequently causing suboptimal performance. In this paper, we go beyond attention or similarity by proposing a novel visual token pruning method named CDPruner, which maximizes the conditional diversity of retained tokens. We first define the conditional similarity between visual tokens conditioned on the instruction, and then reformulate the token pruning problem with determinantal point process (DPP) to maximize the conditional diversity of the selected subset. The proposed CDPruner is training-free and model-agnostic, allowing easy application to various MLLMs. Extensive experiments across diverse MLLMs show that CDPruner establishes new state-of-the-art on various vision-language benchmarks. By maximizing conditional diversity through DPP, the selected subset better represents the input images while closely adhering to user instructions, thereby preserving strong performance even with high reduction ratios. When applied to LLaVA, CDPruner reduces FLOPs by 95\% and CUDA latency by 78\%, while maintaining 94\% of the original accuracy. Our code is available at https://github.com/Theia-4869/CDPruner.
Fast ECoT: Efficient Embodied Chain-of-Thought via Thoughts Reuse
Jun 09, 2025Embodied Chain-of-Thought (ECoT) reasoning enhances vision-language-action (VLA) models by improving performance and interpretability through intermediate reasoning steps. However, its sequential autoregressive token generation introduces significant inference latency, limiting real-time deployment. We propose Fast ECoT, an inference-time acceleration method that exploits the structured and repetitive nature of ECoT to (1) cache and reuse high-level reasoning across timesteps and (2) parallelise the generation of modular reasoning steps. Additionally, we introduce an asynchronous scheduler that decouples reasoning from action decoding, further boosting responsiveness. Fast ECoT requires no model changes or additional training and integrates easily into existing VLA pipelines. Experiments in both simulation (LIBERO) and real-world robot tasks show up to a 7.5% reduction in latency with comparable or improved task success rate and reasoning faithfulness, bringing ECoT policies closer to practical real-time deployment.
PathFL: Multi-Alignment Federated Learning for Pathology Image Segmentation
May 28, 2025Pathology image segmentation across multiple centers encounters significant challenges due to diverse sources of heterogeneity including imaging modalities, organs, and scanning equipment, whose variability brings representation bias and impedes the development of generalizable segmentation models. In this paper, we propose PathFL, a novel multi-alignment Federated Learning framework for pathology image segmentation that addresses these challenges through three-level alignment strategies of image, feature, and model aggregation. Firstly, at the image level, a collaborative style enhancement module aligns and diversifies local data by facilitating style information exchange across clients. Secondly, at the feature level, an adaptive feature alignment module ensures implicit alignment in the representation space by infusing local features with global insights, promoting consistency across heterogeneous client features learning. Finally, at the model aggregation level, a stratified similarity aggregation strategy hierarchically aligns and aggregates models on the server, using layer-specific similarity to account for client discrepancies and enhance global generalization. Comprehensive evaluations on four sets of heterogeneous pathology image datasets, encompassing cross-source, cross-modality, cross-organ, and cross-scanner variations, validate the effectiveness of our PathFL in achieving better performance and robustness against data heterogeneity.