 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedGuards: Multi-Agent System for Reliable Medical Error Detection and Correction
Jun 24, 2026As Large Language Models (LLMs) are increasingly deployed in healthcare settings, accurate error detection and correction in generated or existing text becomes critical, as even minor mistakes can pose risks to patient safety. Existing methods for error detection and correction, including automated checks and heuristic-based approaches, do not generalize well across unseen datasets. In this paper, we propose MedGuards as a medical safety guardrail, which is a new framework that treats medical error detection and correction as a multi-agent in-context learning task. Specialized agents separately detect, localize, and correct errors, while a confidence-guided arbitration mechanism resolves disagreements using reasoning traces and confidence scores. This design enhances interpretability, robustness, and adaptability, without requiring additional training of the base LLMs. Additionally, we introduce the Keyword-Prioritized Correction Score (KPCS), a new evaluation metric that considers whether critical keywords within the reference text are generated correctly, providing a more comprehensive assessment than conventional metrics. Experiments across four multilingual medical datasets consisting of clinical notes demonstrate significant improvements by the proposed framework across several metrics and models. Our aim is to enable safer deployment of LLMs in real-world healthcare applications. For reproducibility, we make our code publicly available at https://github.com/congboma/MedErrBench.
Polyphony: Diffusion-based Dual-Hand Action Segmentation with Alternating Vision Transformer and Semantic Conditioning
May 29, 2026Dual-hand action segmentation, densely predicting actions for both hands from untrimmed videos, is essential for understanding complex bimanual activities. However, it poses several unique challenges: complex inter-hand dependencies, visual asymmetry between hands, representation conflicts where the dominant hand monopolizes gradients, and semantic ambiguity in fine-grained actions. We propose Polyphony, a three-stage method to address these challenges through: (1) an Alternating Dual-Hand Vision Transformer that alternates training between left- and right-hand mini-batches to ensure balanced gradient contributions from both hands while sharing a spatio-temporal encoder; (2) Semantic Feature Conditioning that aligns visual features with structured, compositional action descriptions to enhance discrimination of semantically similar actions; and (3) Diffusion-Based Segmentation with cross-hand feature fusion for inter-hand coordination and adaptive loss weighting for balancing performance. Polyphony achieves state-of-the-art on both dual-hand datasets (HA-ViD, ATTACH) with improvements up to 16.8 points, and on the single-stream Breakfast dataset (82.5%), outperforming the prior best method that uses a 12x larger backbone. Notably, our unified model with a single shared backbone surpasses baselines requiring separate per-hand models. Code is at https://github.com/x-labs-xyz/Polyphony-Dual-hand-Action-Segmentation.
FACTOR: Counterfactual Training-Free Test-Time Adaptation for Open-Vocabulary Object Detection
May 05, 2026Open-vocabulary object detection often fails under distribution shifts, as it can be misled by spurious correlations between non-causal visual attributes (e.g., brightness, texture) and object categories. Existing test-time adaptation (TTA) methods either depend on costly online optimization or perform global calibration, overlooking the attribute-specific nature of these failures. To address this, we propose FACTOR (counterFACtual training-free Test-time adaptation for Open-vocabulaRy object detection), a lightweight framework grounded in counterfactual reasoning. By perturbing test images along non-causal attributes and comparing region-level predictions between original and counterfactual views, FACTOR quantifies attribute sensitivity, semantic relevance, and prediction variation to selectively suppress attribute-dependent predictions-without parameter updates. Experiments on PASCAL-C, COCO-C, and FoggyCityscapes show that FACTOR consistently outperforms prior TTA methods, demonstrating that explicit counterfactual reasoning effectively improves robustness under distribution shifts.
T3: Test-Time Model Merging in VLMs for Zero-Shot Medical Imaging Analysis
Oct 31, 2025



In medical imaging, vision-language models face a critical duality: pretrained networks offer broad robustness but lack subtle, modality-specific characteristics, while fine-tuned expert models achieve high in-distribution accuracy yet falter under modality shift. Existing model-merging techniques, designed for natural-image benchmarks, are simple and efficient but fail to deliver consistent gains across diverse medical modalities; their static interpolation limits reliability in varied clinical tasks. To address this, we introduce Test-Time Task adaptive merging (T^3), a backpropagation-free framework that computes per-sample interpolation coefficients via the Jensen-Shannon divergence between the two models' output distributions. T^3 dynamically preserves local precision when models agree and defers to generalist robustness under drift. To overcome the inference costs of sample-wise merging, we further propose a batch-wise extension, T^3_B, that computes a merging coefficient across a batch of samples, dramatically reducing computational bottleneck. Recognizing the lack of a standardized medical-merging benchmark, we present a rigorous cross-evaluation protocol spanning in-domain, base-to-novel, and corruptions across four modalities. Empirically, T^3 sets new state-of-the-art in Top-1 accuracy and error reduction, outperforming strong baselines while maintaining efficiency, paving the way for adaptive MVLM deployment in clinical settings. Our code is available at https://github.com/Razaimam45/TCube.
Explicit and Implicit Data Augmentation for Social Event Detection
Sep 04, 2025Social event detection involves identifying and categorizing important events from social media, which relies on labeled data, but annotation is costly and labor-intensive. To address this problem, we propose Augmentation framework for Social Event Detection (SED-Aug), a plug-and-play dual augmentation framework, which combines explicit text-based and implicit feature-space augmentation to enhance data diversity and model robustness. The explicit augmentation utilizes large language models to enhance textual information through five diverse generation strategies. For implicit augmentation, we design five novel perturbation techniques that operate in the feature space on structural fused embeddings. These perturbations are crafted to keep the semantic and relational properties of the embeddings and make them more diverse. Specifically, SED-Aug outperforms the best baseline model by approximately 17.67% on the Twitter2012 dataset and by about 15.57% on the Twitter2018 dataset in terms of the average F1 score. The code is available at GitHub: https://github.com/congboma/SED-Aug.
Advancing Fetal Ultrasound Image Quality Assessment in Low-Resource Settings
Jul 30, 2025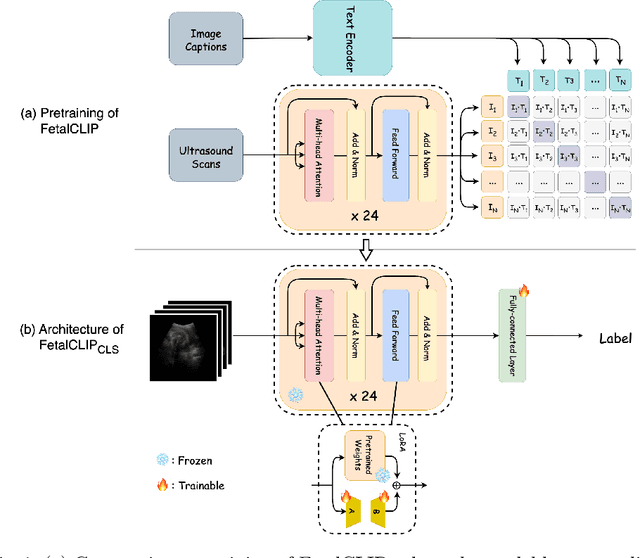
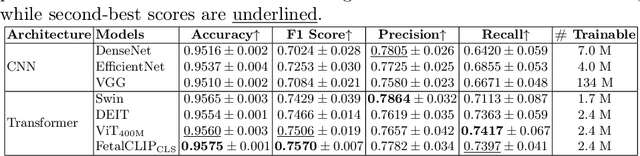


Accurate fetal biometric measurements, such as abdominal circumference, play a vital role in prenatal care. However, obtaining high-quality ultrasound images for these measurements heavily depends on the expertise of sonographers, posing a significant challenge in low-income countries due to the scarcity of trained personnel. To address this issue, we leverage FetalCLIP, a vision-language model pretrained on a curated dataset of over 210,000 fetal ultrasound image-caption pairs, to perform automated fetal ultrasound image quality assessment (IQA) on blind-sweep ultrasound data. We introduce FetalCLIP$_{CLS}$, an IQA model adapted from FetalCLIP using Low-Rank Adaptation (LoRA), and evaluate it on the ACOUSLIC-AI dataset against six CNN and Transformer baselines. FetalCLIP$_{CLS}$ achieves the highest F1 score of 0.757. Moreover, we show that an adapted segmentation model, when repurposed for classification, further improves performance, achieving an F1 score of 0.771. Our work demonstrates how parameter-efficient fine-tuning of fetal ultrasound foundation models can enable task-specific adaptations, advancing prenatal care in resource-limited settings. The experimental code is available at: https://github.com/donglihe-hub/FetalCLIP-IQA.
TransPrune: Token Transition Pruning for Efficient Large Vision-Language Model
Jul 28, 2025Large Vision-Language Models (LVLMs) have advanced multimodal learning but face high computational costs due to the large number of visual tokens, motivating token pruning to improve inference efficiency. The key challenge lies in identifying which tokens are truly important. Most existing approaches rely on attention-based criteria to estimate token importance. However, they inherently suffer from certain limitations, such as positional bias. In this work, we explore a new perspective on token importance based on token transitions in LVLMs. We observe that the transition of token representations provides a meaningful signal of semantic information. Based on this insight, we propose TransPrune, a training-free and efficient token pruning method. Specifically, TransPrune progressively prunes tokens by assessing their importance through a combination of Token Transition Variation (TTV)-which measures changes in both the magnitude and direction of token representations-and Instruction-Guided Attention (IGA), which measures how strongly the instruction attends to image tokens via attention. Extensive experiments demonstrate that TransPrune achieves comparable multimodal performance to original LVLMs, such as LLaVA-v1.5 and LLaVA-Next, across eight benchmarks, while reducing inference TFLOPs by more than half. Moreover, TTV alone can serve as an effective criterion without relying on attention, achieving performance comparable to attention-based methods. The code will be made publicly available upon acceptance of the paper at https://github.com/liaolea/TransPrune.
Intriguing Frequency Interpretation of Adversarial Robustness for CNNs and ViTs
Jun 15, 2025Adversarial examples have attracted significant attention over the years, yet understanding their frequency-based characteristics remains insufficient. In this paper, we investigate the intriguing properties of adversarial examples in the frequency domain for the image classification task, with the following key findings. (1) As the high-frequency components increase, the performance gap between adversarial and natural examples becomes increasingly pronounced. (2) The model performance against filtered adversarial examples initially increases to a peak and declines to its inherent robustness. (3) In Convolutional Neural Networks, mid- and high-frequency components of adversarial examples exhibit their attack capabilities, while in Transformers, low- and mid-frequency components of adversarial examples are particularly effective. These results suggest that different network architectures have different frequency preferences and that differences in frequency components between adversarial and natural examples may directly influence model robustness. Based on our findings, we further conclude with three useful proposals that serve as a valuable reference to the AI model security community.
IA-MVS: Instance-Focused Adaptive Depth Sampling for Multi-View Stereo
May 19, 2025Multi-view stereo (MVS) models based on progressive depth hypothesis narrowing have made remarkable advancements. However, existing methods haven't fully utilized the potential that the depth coverage of individual instances is smaller than that of the entire scene, which restricts further improvements in depth estimation precision. Moreover, inevitable deviations in the initial stage accumulate as the process advances. In this paper, we propose Instance-Adaptive MVS (IA-MVS). It enhances the precision of depth estimation by narrowing the depth hypothesis range and conducting refinement on each instance. Additionally, a filtering mechanism based on intra-instance depth continuity priors is incorporated to boost robustness. Furthermore, recognizing that existing confidence estimation can degrade IA-MVS performance on point clouds. We have developed a detailed mathematical model for confidence estimation based on conditional probability. The proposed method can be widely applied in models based on MVSNet without imposing extra training burdens. Our method achieves state-of-the-art performance on the DTU benchmark. The source code is available at https://github.com/KevinWang73106/IA-MVS.
Kalman Filter Enhanced GRPO for Reinforcement Learning-Based Language Model Reasoning
May 12, 2025Reward baseline is important for Reinforcement Learning (RL) algorithms to reduce variance in policy gradient estimates. Recently, for language modeling, Group Relative Policy Optimization (GRPO) is proposed to compute the advantage for each output by subtracting the mean reward, as the baseline, for all outputs in the group. However, it can lead to inaccurate advantage estimates in environments with highly noisy rewards, potentially introducing bias. In this work, we propose a model, called Kalman Filter Enhanced Group Relative Policy Optimization (KRPO), by using lightweight Kalman filtering to dynamically estimate the latent reward mean and variance. This filtering technique replaces the naive batch mean baseline, enabling more adaptive advantage normalization. Our method does not require additional learned parameters over GRPO. This approach offers a simple yet effective way to incorporate multiple outputs of GRPO into advantage estimation, improving policy optimization in settings where highly dynamic reward signals are difficult to model for language models. Through experiments and analyses, we show that using a more adaptive advantage estimation model, KRPO can improve the stability and performance of GRPO. The code is available at https://github.com/billhhh/KRPO_LLMs_RL