 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaTriplet-RA: Domain Matching via Adaptive Triplet and Reinforced Attention for Unsupervised Domain Adaptation
Nov 16, 2022Unsupervised domain adaption (UDA) is a transfer learning task where the data and annotations of the source domain are available but only have access to the unlabeled target data during training. Most previous methods try to minimise the domain gap by performing distribution alignment between the source and target domains, which has a notable limitation, i.e., operating at the domain level, but neglecting the sample-level differences. To mitigate this weakness, we propose to improve the unsupervised domain adaptation task with an inter-domain sample matching scheme. We apply the widely-used and robust Triplet loss to match the inter-domain samples. To reduce the catastrophic effect of the inaccurate pseudo-labels generated during training, we propose a novel uncertainty measurement method to select reliable pseudo-labels automatically and progressively refine them. We apply the advanced discrete relaxation Gumbel Softmax technique to realise an adaptive Topk scheme to fulfil the functionality. In addition, to enable the global ranking optimisation within one batch for the domain matching, the whole model is optimised via a novel reinforced attention mechanism with supervision from the policy gradient algorithm, using the Average Precision (AP) as the reward. Our model (termed \textbf{\textit{AdaTriplet-RA}}) achieves State-of-the-art results on several public benchmark datasets, and its effectiveness is validated via comprehensive ablation studies. Our method improves the accuracy of the baseline by 9.7\% (ResNet-101) and 6.2\% (ResNet-50) on the VisDa dataset and 4.22\% (ResNet-50) on the Domainnet dataset. {The source code is publicly available at \textit{https://github.com/shuxy0120/AdaTriplet-RA}}.
A Comprehensive Survey on Distributed Training of Graph Neural Networks
Nov 11, 2022Graph neural networks (GNNs) have been demonstrated to be a powerful algorithmic model in broad application fields for their effectiveness in learning over graphs. To scale GNN training up for large-scale and ever-growing graphs, the most promising solution is distributed training which distributes the workload of training across multiple computing nodes. However, the workflows, computational patterns, communication patterns, and optimization techniques of distributed GNN training remain preliminarily understood. In this paper, we provide a comprehensive survey of distributed GNN training by investigating various optimization techniques used in distributed GNN training. First, distributed GNN training is classified into several categories according to their workflows. In addition, their computational patterns and communication patterns, as well as the optimization techniques proposed by recent work are introduced. Second, the software frameworks and hardware platforms of distributed GNN training are also introduced for a deeper understanding. Third, distributed GNN training is compared with distributed training of deep neural networks, emphasizing the uniqueness of distributed GNN training. Finally, interesting issues and opportunities in this field are discussed.
Rethinking the Metric in Few-shot Learning: From an Adaptive Multi-Distance Perspective
Nov 02, 2022



Few-shot learning problem focuses on recognizing unseen classes given a few labeled images. In recent effort, more attention is paid to fine-grained feature embedding, ignoring the relationship among different distance metrics. In this paper, for the first time, we investigate the contributions of different distance metrics, and propose an adaptive fusion scheme, bringing significant improvements in few-shot classification. We start from a naive baseline of confidence summation and demonstrate the necessity of exploiting the complementary property of different distance metrics. By finding the competition problem among them, built upon the baseline, we propose an Adaptive Metrics Module (AMM) to decouple metrics fusion into metric-prediction fusion and metric-losses fusion. The former encourages mutual complementary, while the latter alleviates metric competition via multi-task collaborative learning. Based on AMM, we design a few-shot classification framework AMTNet, including the AMM and the Global Adaptive Loss (GAL), to jointly optimize the few-shot task and auxiliary self-supervised task, making the embedding features more robust. In the experiment, the proposed AMM achieves 2% higher performance than the naive metrics fusion module, and our AMTNet outperforms the state-of-the-arts on multiple benchmark datasets.
Faith: An Efficient Framework for Transformer Verification on GPUs
Sep 23, 2022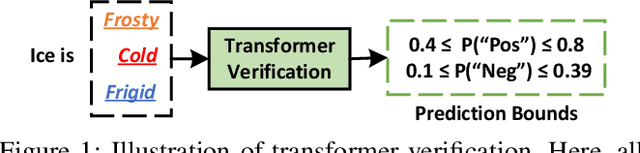

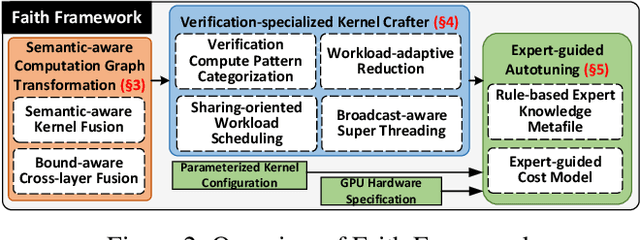
Transformer verification draws increasing attention in machine learning research and industry. It formally verifies the robustness of transformers against adversarial attacks such as exchanging words in a sentence with synonyms. However, the performance of transformer verification is still not satisfactory due to bound-centric computation which is significantly different from standard neural networks. In this paper, we propose Faith, an efficient framework for transformer verification on GPUs. We first propose a semantic-aware computation graph transformation to identify semantic information such as bound computation in transformer verification. We exploit such semantic information to enable efficient kernel fusion at the computation graph level. Second, we propose a verification-specialized kernel crafter to efficiently map transformer verification to modern GPUs. This crafter exploits a set of GPU hardware supports to accelerate verification specialized operations which are usually memory-intensive. Third, we propose an expert-guided autotuning to incorporate expert knowledge on GPU backends to facilitate large search space exploration. Extensive evaluations show that Faith achieves $2.1\times$ to $3.4\times$ ($2.6\times$ on average) speedup over state-of-the-art frameworks.
Image Understands Point Cloud: Weakly Supervised 3D Semantic Segmentation via Association Learning
Sep 16, 2022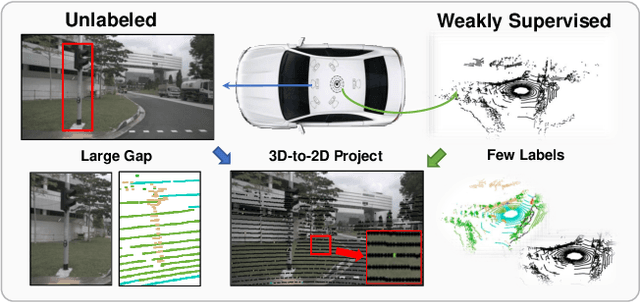
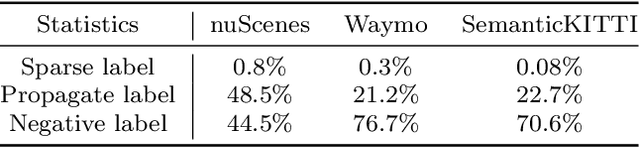

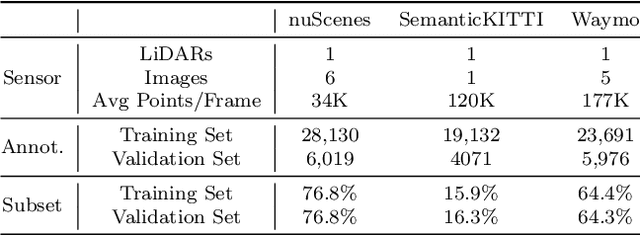
Weakly supervised point cloud semantic segmentation methods that require 1\% or fewer labels, hoping to realize almost the same performance as fully supervised approaches, which recently, have attracted extensive research attention. A typical solution in this framework is to use self-training or pseudo labeling to mine the supervision from the point cloud itself, but ignore the critical information from images. In fact, cameras widely exist in LiDAR scenarios and this complementary information seems to be greatly important for 3D applications. In this paper, we propose a novel cross-modality weakly supervised method for 3D segmentation, incorporating complementary information from unlabeled images. Basically, we design a dual-branch network equipped with an active labeling strategy, to maximize the power of tiny parts of labels and directly realize 2D-to-3D knowledge transfer. Afterwards, we establish a cross-modal self-training framework in an Expectation-Maximum (EM) perspective, which iterates between pseudo labels estimation and parameters updating. In the M-Step, we propose a cross-modal association learning to mine complementary supervision from images by reinforcing the cycle-consistency between 3D points and 2D superpixels. In the E-step, a pseudo label self-rectification mechanism is derived to filter noise labels thus providing more accurate labels for the networks to get fully trained. The extensive experimental results demonstrate that our method even outperforms the state-of-the-art fully supervised competitors with less than 1\% actively selected annotations.
Prototype-Aware Heterogeneous Task for Point Cloud Completion
Sep 05, 2022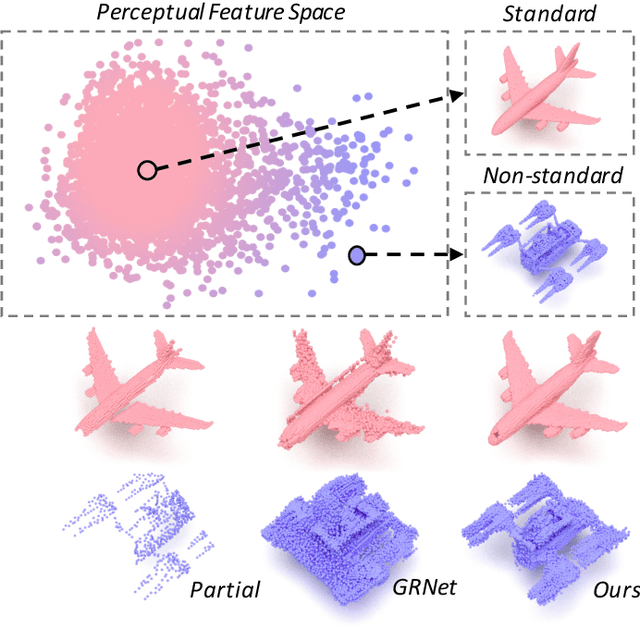
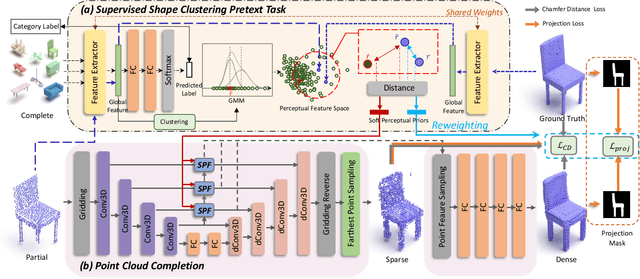

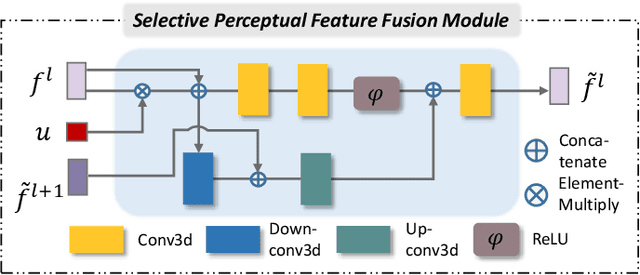
Point cloud completion, which aims at recovering original shape information from partial point clouds, has attracted attention on 3D vision community. Existing methods usually succeed in completion for standard shape, while failing to generate local details of point clouds for some non-standard shapes. To achieve desirable local details, guidance from global shape information is of critical importance. In this work, we design an effective way to distinguish standard/non-standard shapes with the help of intra-class shape prototypical representation, which can be calculated by the proposed supervised shape clustering pretext task, resulting in a heterogeneous component w.r.t completion network. The representative prototype, defined as feature centroid of shape categories, can provide global shape guidance, which is referred to as soft-perceptual prior, to inject into downstream completion network by the desired selective perceptual feature fusion module in a multi-scale manner. Moreover, for effective training, we consider difficulty-based sampling strategy to encourage the network to pay more attention to some partial point clouds with fewer geometric information. Experimental results show that our method outperforms other state-of-the-art methods and has strong ability on completing complex geometric shapes.
Attentive pooling for Group Activity Recognition
Aug 31, 2022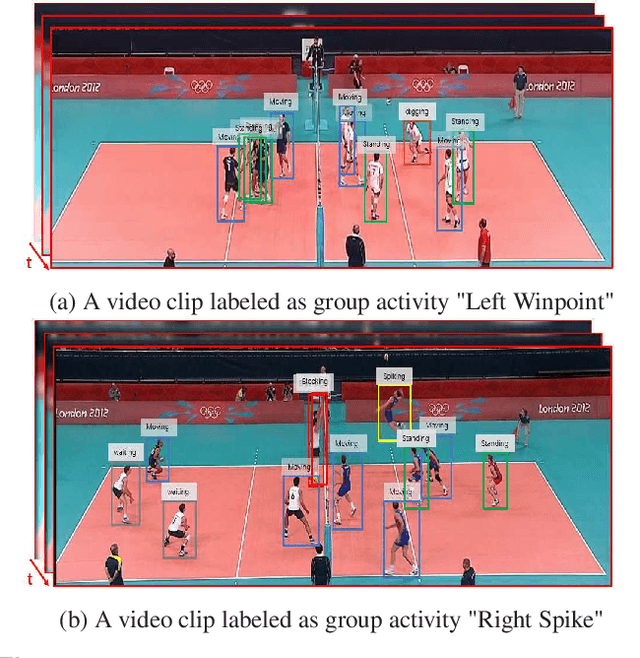

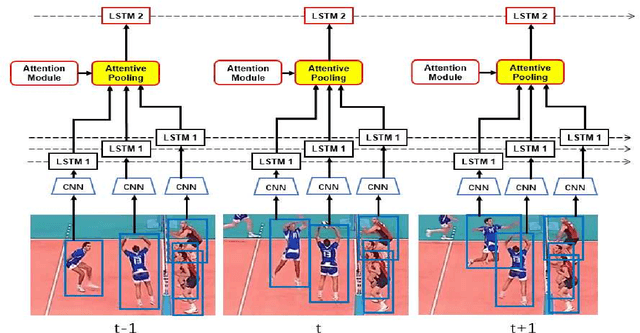
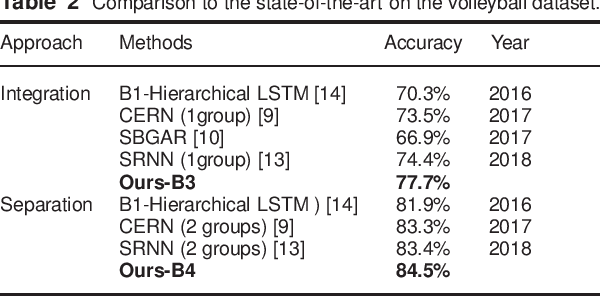
In group activity recognition, hierarchical framework is widely adopted to represent the relationships between individuals and their corresponding group, and has achieved promising performance. However, the existing methods simply employed max/average pooling in this framework, which ignored the distinct contributions of different individuals to the group activity recognition. In this paper, we propose a new contextual pooling scheme, named attentive pooling, which enables the weighted information transition from individual actions to group activity. By utilizing the attention mechanism, the attentive pooling is intrinsically interpretable and able to embed member context into the existing hierarchical model. In order to verify the effectiveness of the proposed scheme, two specific attentive pooling methods, i.e., global attentive pooling (GAP) and hierarchical attentive pooling (HAP) are designed. GAP rewards the individuals that are significant to group activity, while HAP further considers the hierarchical division by introducing subgroup structure. The experimental results on the benchmark dataset demonstrate that our proposal is significantly superior beyond the baseline and is comparable to the state-of-the-art methods.
Boosting Night-time Scene Parsing with Learnable Frequency
Aug 30, 2022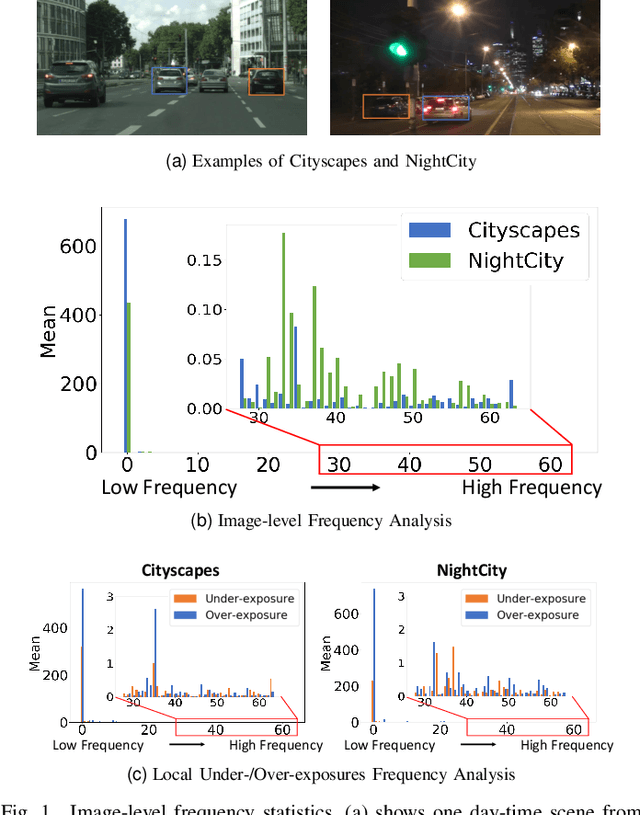
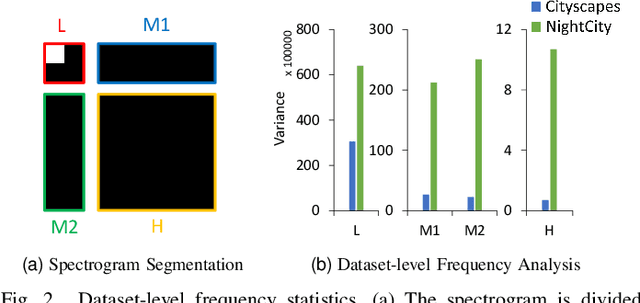
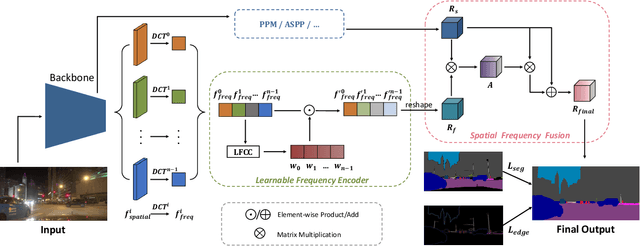
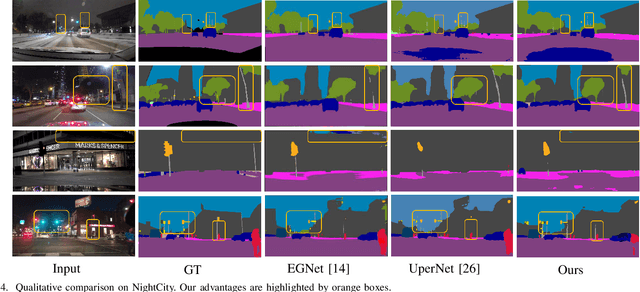
Night-Time Scene Parsing (NTSP) is essential to many vision applications, especially for autonomous driving. Most of the existing methods are proposed for day-time scene parsing. They rely on modeling pixel intensity-based spatial contextual cues under even illumination. Hence, these methods do not perform well in night-time scenes as such spatial contextual cues are buried in the over-/under-exposed regions in night-time scenes. In this paper, we first conduct an image frequency-based statistical experiment to interpret the day-time and night-time scene discrepancies. We find that image frequency distributions differ significantly between day-time and night-time scenes, and understanding such frequency distributions is critical to NTSP problem. Based on this, we propose to exploit the image frequency distributions for night-time scene parsing. First, we propose a Learnable Frequency Encoder (LFE) to model the relationship between different frequency coefficients to measure all frequency components dynamically. Second, we propose a Spatial Frequency Fusion module (SFF) that fuses both spatial and frequency information to guide the extraction of spatial context features. Extensive experiments show that our method performs favorably against the state-of-the-art methods on the NightCity, NightCity+ and BDD100K-night datasets. In addition, we demonstrate that our method can be applied to existing day-time scene parsing methods and boost their performance on night-time scenes.
MILAN: Masked Image Pretraining on Language Assisted Representation
Aug 15, 2022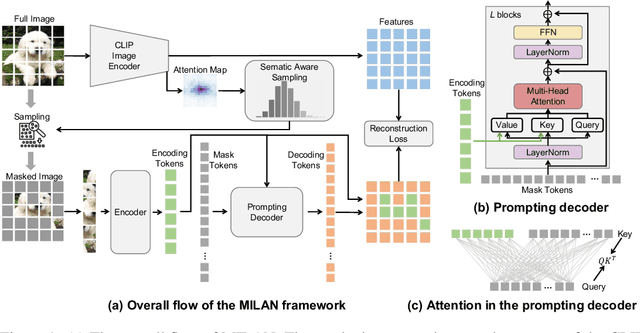
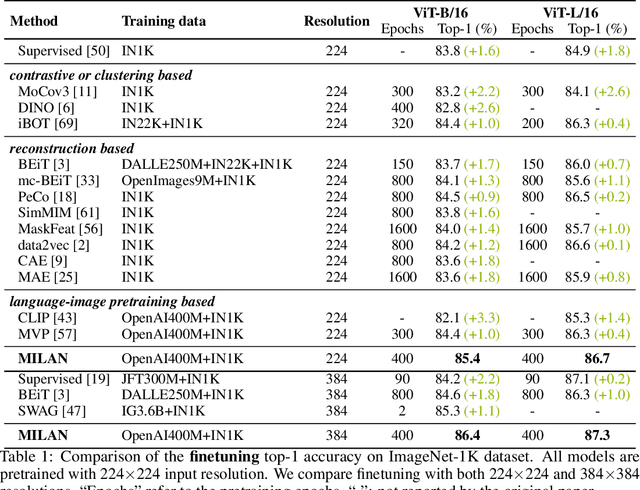

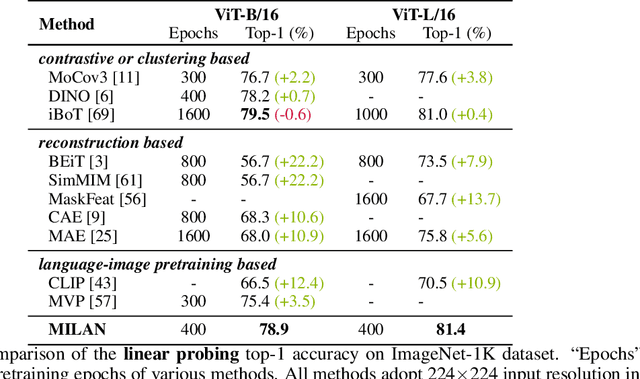
Self-attention based transformer models have been dominating many computer vision tasks in the past few years. Their superb model qualities heavily depend on the excessively large labeled image datasets. In order to reduce the reliance on large labeled datasets, reconstruction based masked autoencoders are gaining popularity, which learn high quality transferable representations from unlabeled images. For the same purpose, recent weakly supervised image pretraining methods explore language supervision from text captions accompanying the images. In this work, we propose masked image pretraining on language assisted representation, dubbed as MILAN. Instead of predicting raw pixels or low level features, our pretraining objective is to reconstruct the image features with substantial semantic signals that are obtained using caption supervision. Moreover, to accommodate our reconstruction target, we propose a more efficient prompting decoder architecture and a semantic aware mask sampling mechanism, which further advance the transfer performance of the pretrained model. Experimental results demonstrate that MILAN delivers higher accuracy than the previous works. When the masked autoencoder is pretrained and finetuned on ImageNet-1K dataset with an input resolution of 224x224, MILAN achieves a top-1 accuracy of 85.4% on ViTB/16, surpassing previous state-of-the-arts by 1%. In the downstream semantic segmentation task, MILAN achieves 52.7 mIoU using ViT-B/16 backbone on ADE20K dataset, outperforming previous masked pretraining results by 4 points.
Predicting the Output Structure of Sparse Matrix Multiplication with Sampled Compression Ratio
Jul 28, 2022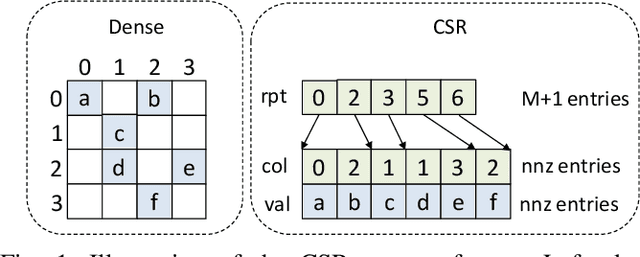
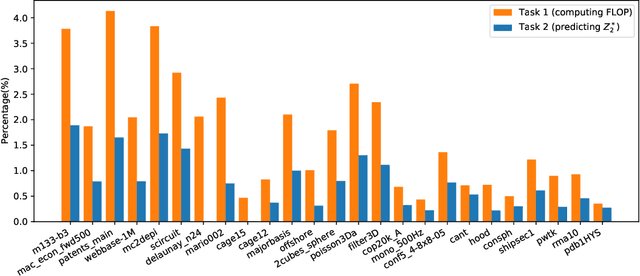
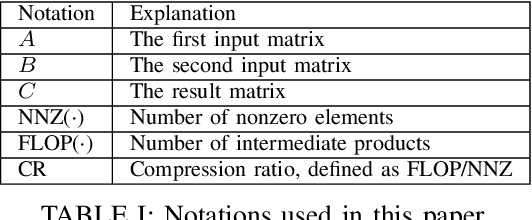
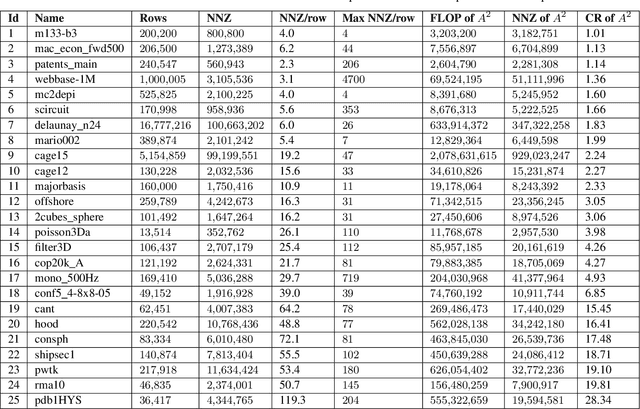
Sparse general matrix multiplication (SpGEMM) is a fundamental building block in numerous scientific applications. One critical task of SpGEMM is to compute or predict the structure of the output matrix (i.e., the number of nonzero elements per output row) for efficient memory allocation and load balance, which impact the overall performance of SpGEMM. Existing work either precisely calculates the output structure or adopts upper-bound or sampling-based methods to predict the output structure. However, these methods either take much execution time or are not accurate enough. In this paper, we propose a novel sampling-based method with better accuracy and low costs compared to the existing sampling-based method. The proposed method first predicts the compression ratio of SpGEMM by leveraging the number of intermediate products (denoted as FLOP) and the number of nonzero elements (denoted as NNZ) of the same sampled result matrix. And then, the predicted output structure is obtained by dividing the FLOP per output row by the predicted compression ratio. We also propose a reference design of the existing sampling-based method with optimized computing overheads to demonstrate the better accuracy of the proposed method. We construct 625 test cases with various matrix dimensions and sparse structures to evaluate the prediction accuracy. Experimental results show that the absolute relative errors of the proposed method and the reference design are 1.56\% and 8.12\%, respectively, on average, and 25\% and 156\%, respectively, in the worst case.