 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaTriplet-RA: Domain Matching via Adaptive Triplet and Reinforced Attention for Unsupervised Domain Adaptation
Nov 16, 2022Unsupervised domain adaption (UDA) is a transfer learning task where the data and annotations of the source domain are available but only have access to the unlabeled target data during training. Most previous methods try to minimise the domain gap by performing distribution alignment between the source and target domains, which has a notable limitation, i.e., operating at the domain level, but neglecting the sample-level differences. To mitigate this weakness, we propose to improve the unsupervised domain adaptation task with an inter-domain sample matching scheme. We apply the widely-used and robust Triplet loss to match the inter-domain samples. To reduce the catastrophic effect of the inaccurate pseudo-labels generated during training, we propose a novel uncertainty measurement method to select reliable pseudo-labels automatically and progressively refine them. We apply the advanced discrete relaxation Gumbel Softmax technique to realise an adaptive Topk scheme to fulfil the functionality. In addition, to enable the global ranking optimisation within one batch for the domain matching, the whole model is optimised via a novel reinforced attention mechanism with supervision from the policy gradient algorithm, using the Average Precision (AP) as the reward. Our model (termed \textbf{\textit{AdaTriplet-RA}}) achieves State-of-the-art results on several public benchmark datasets, and its effectiveness is validated via comprehensive ablation studies. Our method improves the accuracy of the baseline by 9.7\% (ResNet-101) and 6.2\% (ResNet-50) on the VisDa dataset and 4.22\% (ResNet-50) on the Domainnet dataset. {The source code is publicly available at \textit{https://github.com/shuxy0120/AdaTriplet-RA}}.
Misspecified Phase Retrieval with Generative Priors
Oct 11, 2022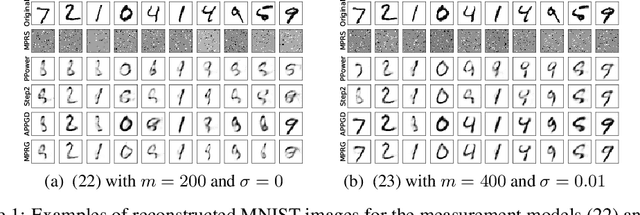
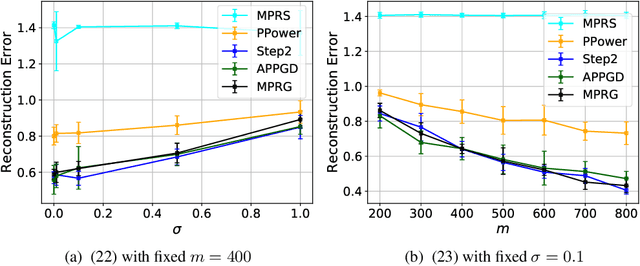
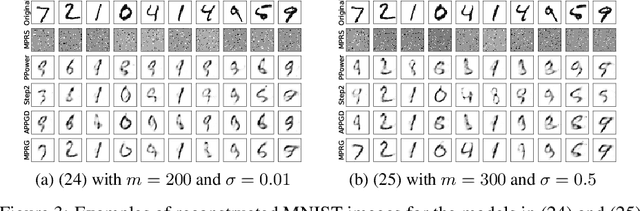
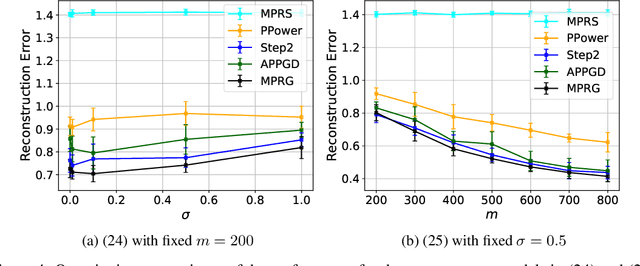
In this paper, we study phase retrieval under model misspecification and generative priors. In particular, we aim to estimate an $n$-dimensional signal $\mathbf{x}$ from $m$ i.i.d.~realizations of the single index model $y = f(\mathbf{a}^T\mathbf{x})$, where $f$ is an unknown and possibly random nonlinear link function and $\mathbf{a} \in \mathbb{R}^n$ is a standard Gaussian vector. We make the assumption $\mathrm{Cov}[y,(\mathbf{a}^T\mathbf{x})^2] \ne 0$, which corresponds to the misspecified phase retrieval problem. In addition, the underlying signal $\mathbf{x}$ is assumed to lie in the range of an $L$-Lipschitz continuous generative model with bounded $k$-dimensional inputs. We propose a two-step approach, for which the first step plays the role of spectral initialization and the second step refines the estimated vector produced by the first step iteratively. We show that both steps enjoy a statistical rate of order $\sqrt{(k\log L)\cdot (\log m)/m}$ under suitable conditions. Experiments on image datasets are performed to demonstrate that our approach performs on par with or even significantly outperforms several competing methods.
ProSelfLC: Progressive Self Label Correction Towards A Low-Temperature Entropy State
Jun 30, 2022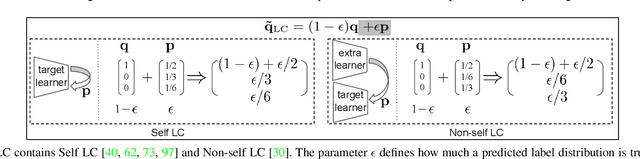

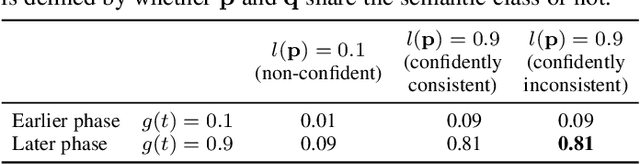
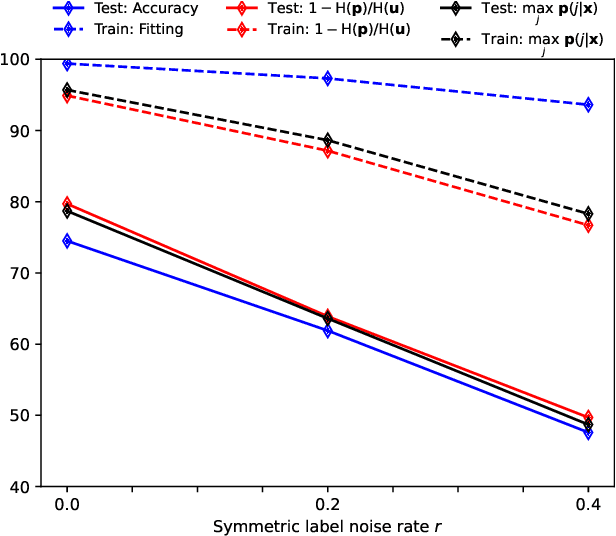
To train robust deep neural networks (DNNs), we systematically study several target modification approaches, which include output regularisation, self and non-self label correction (LC). Three key issues are discovered: (1) Self LC is the most appealing as it exploits its own knowledge and requires no extra models. However, how to automatically decide the trust degree of a learner as training goes is not well answered in the literature. (2) Some methods penalise while the others reward low-entropy predictions, prompting us to ask which one is better. (3) Using the standard training setting, a trained network is of low confidence when severe noise exists, making it hard to leverage its high-entropy self knowledge. To resolve the issue (1), taking two well-accepted propositions--deep neural networks learn meaningful patterns before fitting noise and minimum entropy regularisation principle--we propose a novel end-to-end method named ProSelfLC, which is designed according to learning time and entropy. Specifically, given a data point, we progressively increase trust in its predicted label distribution versus its annotated one if a model has been trained for enough time and the prediction is of low entropy (high confidence). For the issue (2), according to ProSelfLC, we empirically prove that it is better to redefine a meaningful low-entropy status and optimise the learner toward it. This serves as a defence of entropy minimisation. To address the issue (3), we decrease the entropy of self knowledge using a low temperature before exploiting it to correct labels, so that the revised labels redefine a low-entropy target state. We demonstrate the effectiveness of ProSelfLC through extensive experiments in both clean and noisy settings, and on both image and protein datasets. Furthermore, our source code is available at https://github.com/XinshaoAmosWang/ProSelfLC-AT.
Not All Knowledge Is Created Equal
Jun 02, 2021
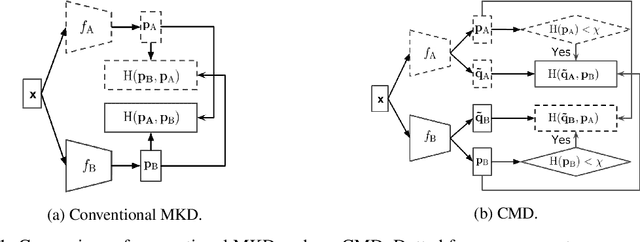

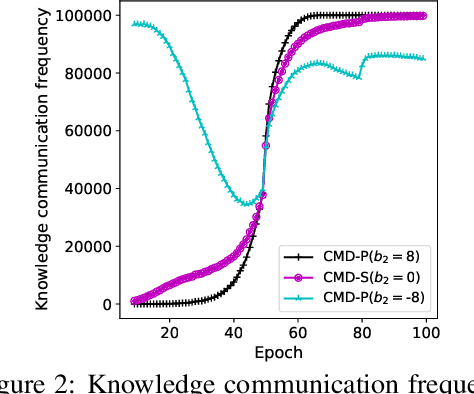
Mutual knowledge distillation (MKD) improves a model by distilling knowledge from another model. However, not all knowledge is certain and correct, especially under adverse conditions. For example, label noise usually leads to less reliable models due to the undesired memorisation [1, 2]. Wrong knowledge misleads the learning rather than helps. This problem can be handled by two aspects: (i) improving the reliability of a model where the knowledge is from (i.e., knowledge source's reliability); (ii) selecting reliable knowledge for distillation. In the literature, making a model more reliable is widely studied while selective MKD receives little attention. Therefore, we focus on studying selective MKD and highlight its importance in this work. Concretely, a generic MKD framework, Confident knowledge selection followed by Mutual Distillation (CMD), is designed. The key component of CMD is a generic knowledge selection formulation, making the selection threshold either static (CMD-S) or progressive (CMD-P). Additionally, CMD covers two special cases: zero knowledge and all knowledge, leading to a unified MKD framework. We empirically find CMD-P performs better than CMD-S. The main reason is that a model's knowledge upgrades and becomes confident as the training progresses. Extensive experiments are present to demonstrate the effectiveness of CMD and thoroughly justify the design of CMD. For example, CMD-P obtains new state-of-the-art results in robustness against label noise.
ProSelfLC: Progressive Self Label Correction for Training Robust Deep Neural Networks
Jun 08, 2020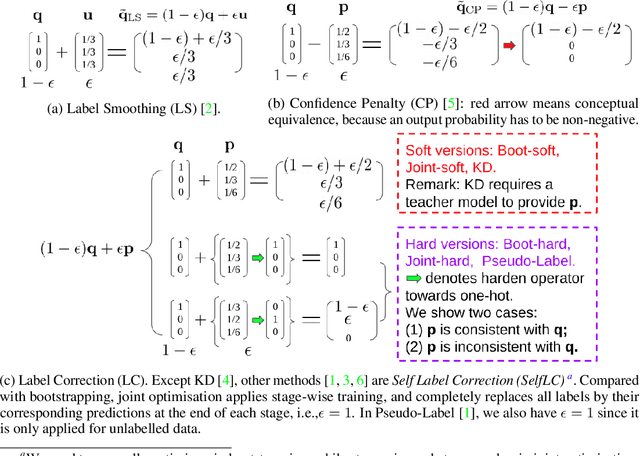

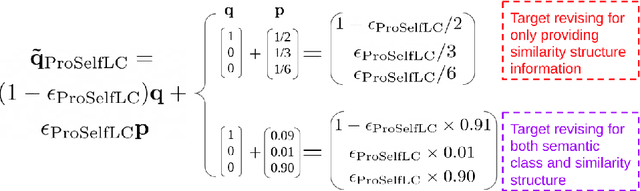
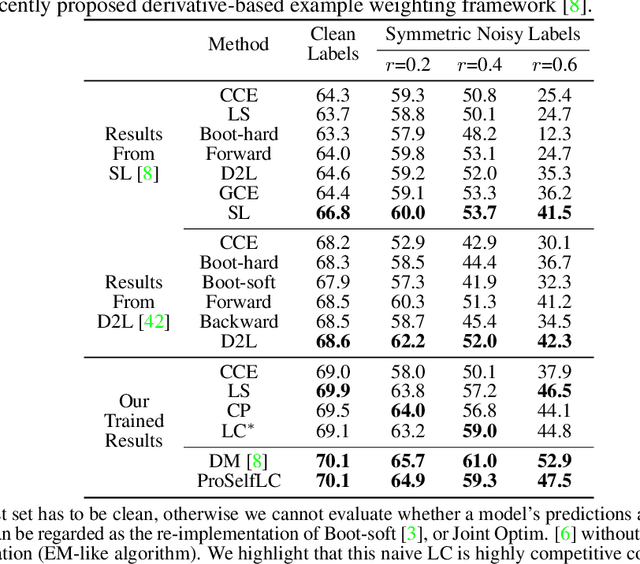
We systematically study popular target modification approaches in supervised learning. We show that they can be connected mathematically through entropy and KL divergence. This uncovers that some methods penalise while the others reward low entropy. Additionally, some of them are suboptimal because they do not leverage the knowledge of a model itself; some rely on extra learners or stage-wise training that may require a human intervention thus being difficult to optimise; most importantly, there does not exist an automatic way to decide how much we trust a predicted label distribution, let alone exploiting it. To resolve these issues, taking two well-accepted expertise: deep neural networks learn meaningful patterns before fitting noise [1] and minimum entropy regularisation principle [2], we propose a simple end-to-end method named ProSelfLC, which is endorsed by long learning time and high prediction confidence. Specifically, given a data point, we progressively trust more its predicted label distribution than its annotated one if a model has been trained for a long time and outputs a highly confident prediction (low entropy). By extensive experiments, we show: (1) ProSelfLC can revise an example's one-hot label distribution by adding the perceptual similarity structure information so that its learning target becomes structured and soft; (2) When being applied to noisy labels, it can correct their semantic classes; (3) It outperforms existing methods with the lowest entropy, which indicates it is right for a learner to be confident in correct patterns.
Instance Cross Entropy for Deep Metric Learning
Nov 22, 2019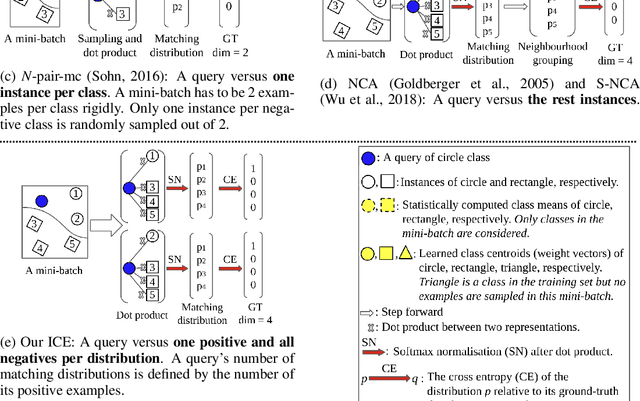
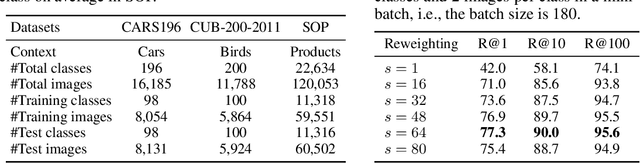

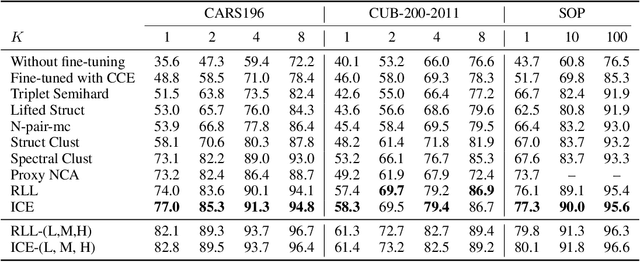
Loss functions play a crucial role in deep metric learning thus a variety of them have been proposed. Some supervise the learning process by pairwise or tripletwise similarity constraints while others take advantage of structured similarity information among multiple data points. In this work, we approach deep metric learning from a novel perspective. We propose instance cross entropy (ICE) which measures the difference between an estimated instance-level matching distribution and its ground-truth one. ICE has three main appealing properties. Firstly, similar to categorical cross entropy (CCE), ICE has clear probabilistic interpretation and exploits structured semantic similarity information for learning supervision. Secondly, ICE is scalable to infinite training data as it learns on mini-batches iteratively and is independent of the training set size. Thirdly, motivated by our relative weight analysis, seamless sample reweighting is incorporated. It rescales samples' gradients to control the differentiation degree over training examples instead of truncating them by sample mining. In addition to its simplicity and intuitiveness, extensive experiments on three real-world benchmarks demonstrate the superiority of ICE.
ID-aware Quality for Set-based Person Re-identification
Nov 20, 2019
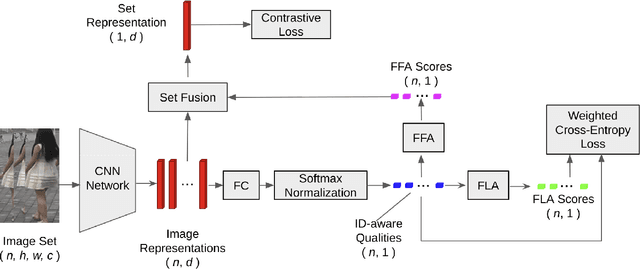
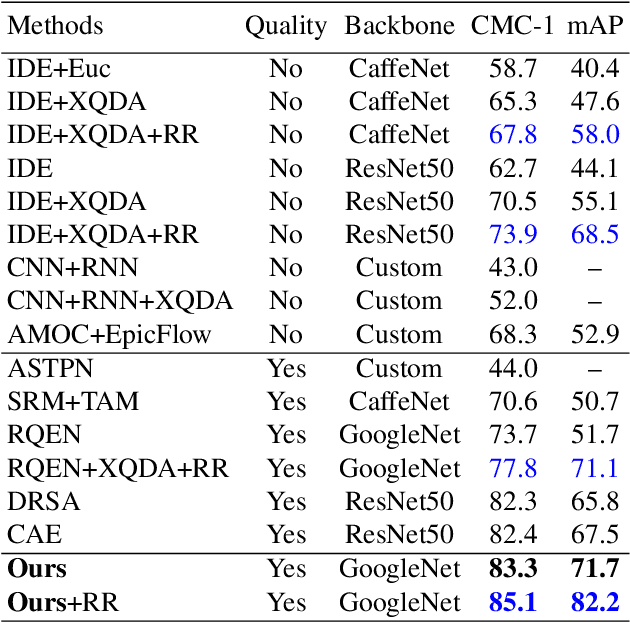
Set-based person re-identification (SReID) is a matching problem that aims to verify whether two sets are of the same identity (ID). Existing SReID models typically generate a feature representation per image and aggregate them to represent the set as a single embedding. However, they can easily be perturbed by noises--perceptually/semantically low quality images--which are inevitable due to imperfect tracking/detection systems, or overfit to trivial images. In this work, we present a novel and simple solution to this problem based on ID-aware quality that measures the perceptual and semantic quality of images guided by their ID information. Specifically, we propose an ID-aware Embedding that consists of two key components: (1) Feature learning attention that aims to learn robust image embeddings by focusing on 'medium' hard images. This way it can prevent overfitting to trivial images, and alleviate the influence of outliers. (2) Feature fusion attention is to fuse image embeddings in the set to obtain the set-level embedding. It ignores noisy information and pays more attention to discriminative images to aggregate more discriminative information. Experimental results on four datasets show that our method outperforms state-of-the-art approaches despite the simplicity of our approach.
Emphasis Regularisation by Gradient Rescaling for Training Deep Neural Networks with Noisy Labels
May 27, 2019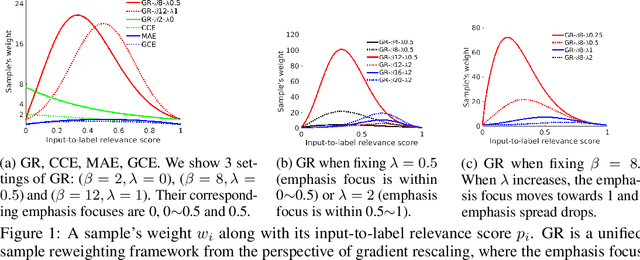

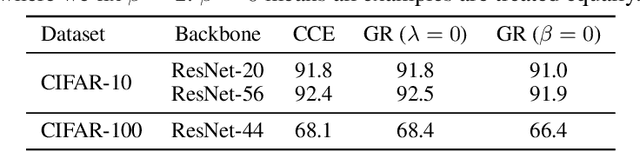
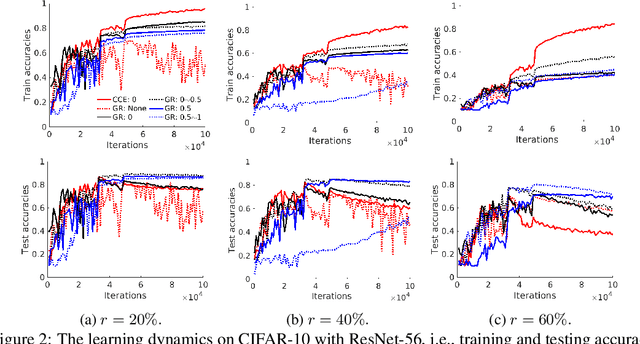
It is fundamental and challenging to train robust and accurate Deep Neural Networks (DNNs) when noisy labels exist. Although great progress has been made, there is still one crucial research question which is not thoroughly explored yet: What training examples should be focused and how much more should they be emphasised when training DNNs under label noise? In this work, we study this question and propose gradient rescaling (GR) to solve it. GR modifies the magnitude of logit vector's gradient to emphasise on relatively easier training data points when severe noise exists, which functions as explicit emphasis regularisation to improve the generalisation performance of DNNs. Apart from regularisation, we also interpret GR from the perspectives of sample reweighting and designing robust loss functions. Therefore, our proposed GR helps connect these three approaches in the literature. We empirically demonstrate that GR is highly noise-robust and outperforms the state-of-the-art noise-tolerant algorithms by a large margin, e.g., increasing 7% on CIFAR-100 with 40% noisy labels. It is also significantly superior to standard regularisors. Furthermore, we present comprehensive ablation studies to explore the behaviours of GR under different cases, which is informative for applying GR in real-world scenarios.
Improving MAE against CCE under Label Noise
Apr 19, 2019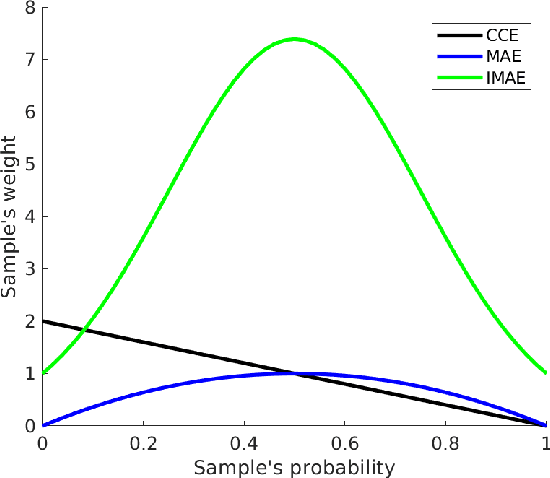
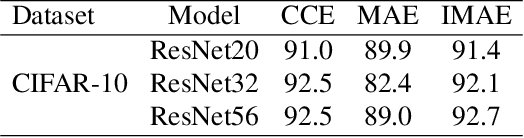
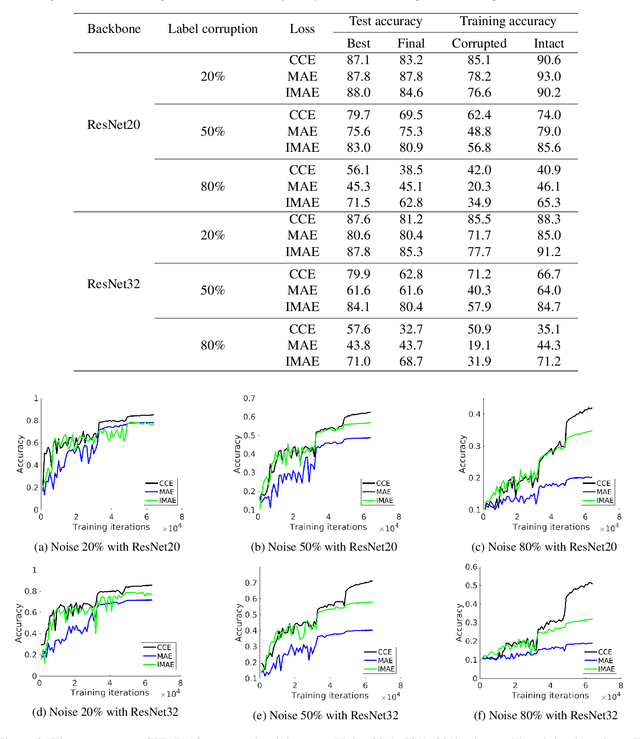
Label noise is inherent in many deep learning tasks when the training set becomes large. A typical approach to tackle noisy labels is using robust loss functions. Categorical cross entropy (CCE) is a successful loss function in many applications. However, CCE is also notorious for fitting samples with corrupted labels easily. In contrast, mean absolute error (MAE) is noise-tolerant theoretically, but it generally works much worse than CCE in practice. In this work, we have three main points. First, to explain why MAE generally performs much worse than CCE, we introduce a new understanding of them fundamentally by exposing their intrinsic sample weighting schemes from the perspective of every sample's gradient magnitude with respect to logit vector. Consequently, we find that MAE's differentiation degree over training examples is too small so that informative ones cannot contribute enough against the non-informative during training. Therefore, MAE generally underfits training data when noise rate is high. Second, based on our finding, we propose an improved MAE (IMAE), which inherits MAE's good noise-robustness. Moreover, the differentiation degree over training data points is controllable so that IMAE addresses the underfitting problem of MAE. Third, the effectiveness of IMAE against CCE and MAE is evaluated empirically with extensive experiments, which focus on image classification under synthetic corrupted labels and video retrieval under real noisy labels.
Ranked List Loss for Deep Metric Learning
Apr 16, 2019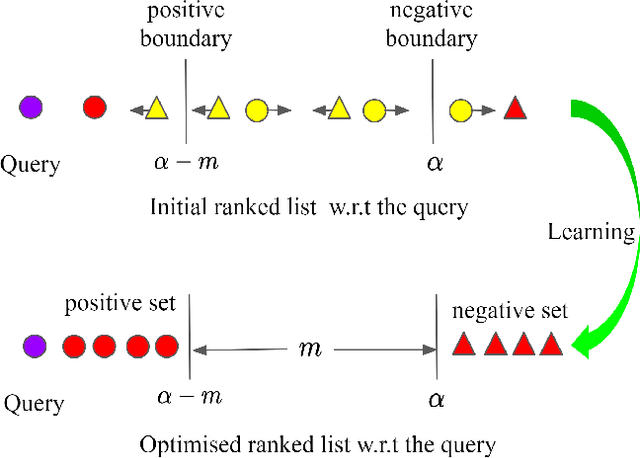
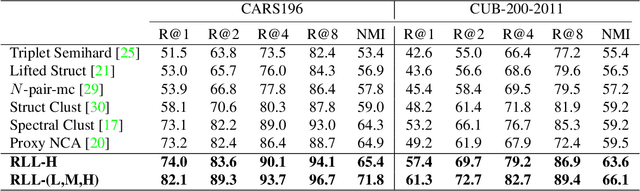

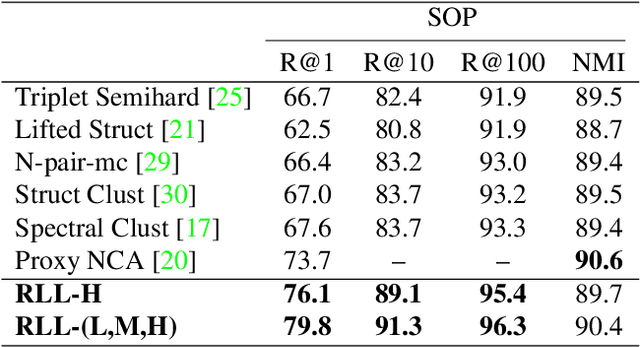
The objective of deep metric learning (DML) is to learn embeddings that can capture semantic similarity information among data points. Existing pairwise or tripletwise loss functions used in DML are known to suffer from slow convergence due to a large proportion of trivial pairs or triplets as the model improves. To improve this, rankingmotivated structured losses are proposed recently to incorporate multiple examples and exploit the structured information among them. They converge faster and achieve state-of-the-art performance. In this work, we present two limitations of existing ranking-motivated structured losses and propose a novel ranked list loss to solve both of them. First, given a query, only a fraction of data points is incorporated to build the similarity structure. Consequently, some useful examples are ignored and the structure is less informative. To address this, we propose to build a setbased similarity structure by exploiting all instances in the gallery. The samples are split into a positive set and a negative set. Our objective is to make the query closer to the positive set than to the negative set by a margin. Second, previous methods aim to pull positive pairs as close as possible in the embedding space. As a result, the intraclass data distribution might be dropped. In contrast, we propose to learn a hypersphere for each class in order to preserve the similarity structure inside it. Our extensive experiments show that the proposed method achieves state-of-the-art performance on three widely used benchmarks.