 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE-ViL 2.0: Multi-view Contrastive Learning for Image-Text Pre-training
Sep 30, 2022
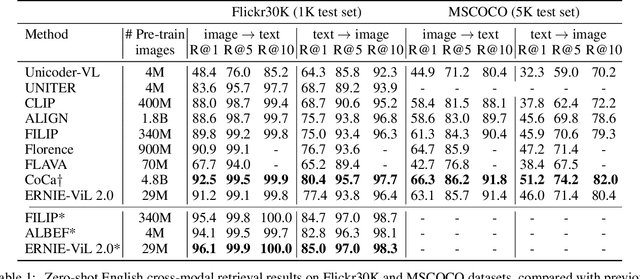
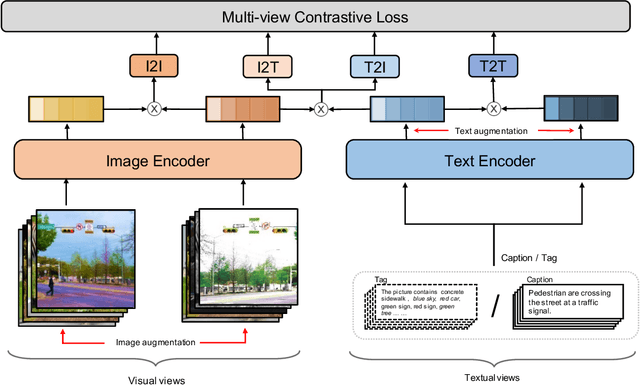
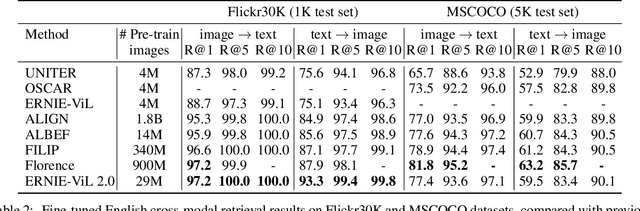
Recent Vision-Language Pre-trained (VLP) models based on dual encoder have attracted extensive attention from academia and industry due to their superior performance on various cross-modal tasks and high computational efficiency. They attempt to learn cross-modal representation using contrastive learning on image-text pairs, however, the built inter-modal correlations only rely on a single view for each modality. Actually, an image or a text contains various potential views, just as humans could capture a real-world scene via diverse descriptions or photos. In this paper, we propose ERNIE-ViL 2.0, a Multi-View Contrastive learning framework to build intra-modal and inter-modal correlations between diverse views simultaneously, aiming at learning a more robust cross-modal representation. Specifically, we construct multiple views within each modality to learn the intra-modal correlation for enhancing the single-modal representation. Besides the inherent visual/textual views, we construct sequences of object tags as a special textual view to narrow the cross-modal semantic gap on noisy image-text pairs. Pre-trained with 29M publicly available datasets, ERNIE-ViL 2.0 achieves competitive results on English cross-modal retrieval. Additionally, to generalize our method to Chinese cross-modal tasks, we train ERNIE-ViL 2.0 through scaling up the pre-training datasets to 1.5B Chinese image-text pairs, resulting in significant improvements compared to previous SOTA results on Chinese cross-modal retrieval. We release our pre-trained models in https://github.com/PaddlePaddle/ERNIE.
ERNIE-mmLayout: Multi-grained MultiModal Transformer for Document Understanding
Sep 18, 2022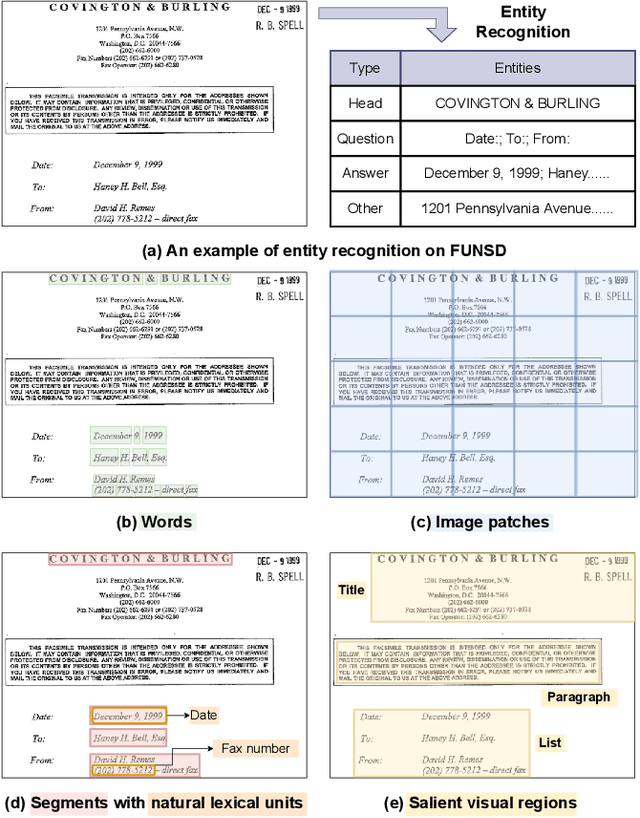
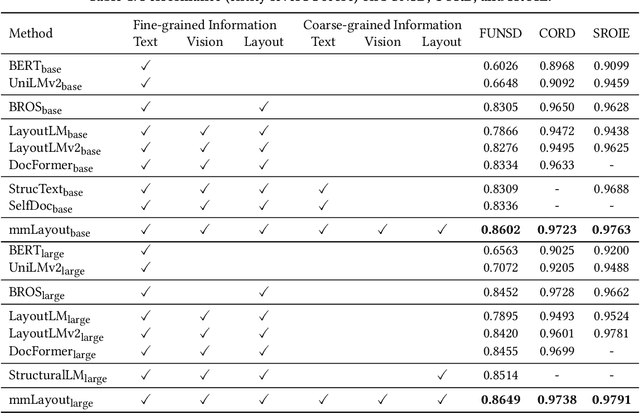
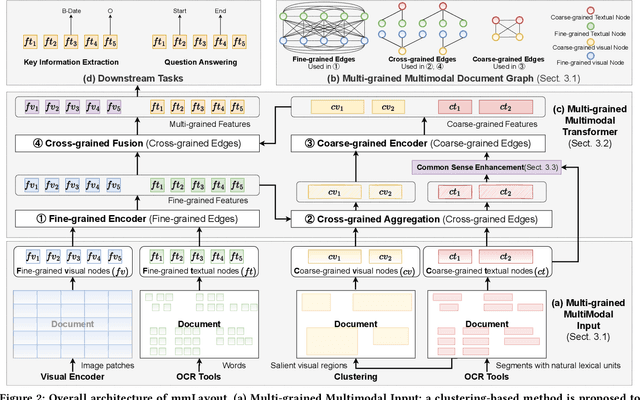
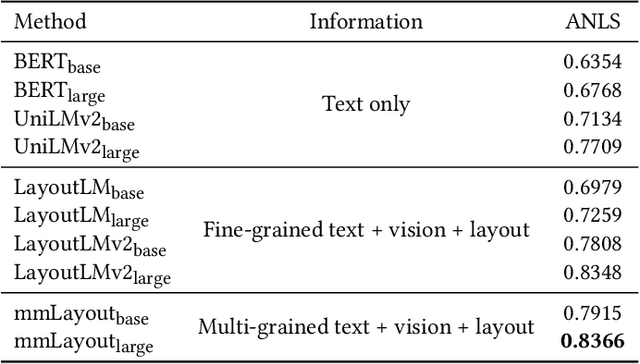
Recent efforts of multimodal Transformers have improved Visually Rich Document Understanding (VrDU) tasks via incorporating visual and textual information. However, existing approaches mainly focus on fine-grained elements such as words and document image patches, making it hard for them to learn from coarse-grained elements, including natural lexical units like phrases and salient visual regions like prominent image regions. In this paper, we attach more importance to coarse-grained elements containing high-density information and consistent semantics, which are valuable for document understanding. At first, a document graph is proposed to model complex relationships among multi-grained multimodal elements, in which salient visual regions are detected by a cluster-based method. Then, a multi-grained multimodal Transformer called mmLayout is proposed to incorporate coarse-grained information into existing pre-trained fine-grained multimodal Transformers based on the graph. In mmLayout, coarse-grained information is aggregated from fine-grained, and then, after further processing, is fused back into fine-grained for final prediction. Furthermore, common sense enhancement is introduced to exploit the semantic information of natural lexical units. Experimental results on four tasks, including information extraction and document question answering, show that our method can improve the performance of multimodal Transformers based on fine-grained elements and achieve better performance with fewer parameters. Qualitative analyses show that our method can capture consistent semantics in coarse-grained elements.
Test-Time Training with Masked Autoencoders
Sep 15, 2022
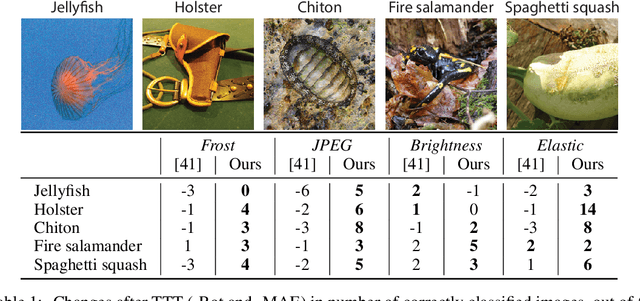
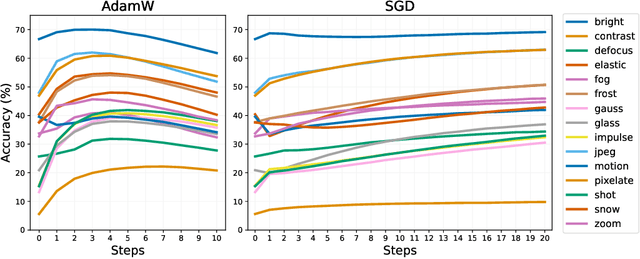

Test-time training adapts to a new test distribution on the fly by optimizing a model for each test input using self-supervision. In this paper, we use masked autoencoders for this one-sample learning problem. Empirically, our simple method improves generalization on many visual benchmarks for distribution shifts. Theoretically, we characterize this improvement in terms of the bias-variance trade-off.
WOC: A Handy Webcam-based 3D Online Chatroom
Sep 02, 2022
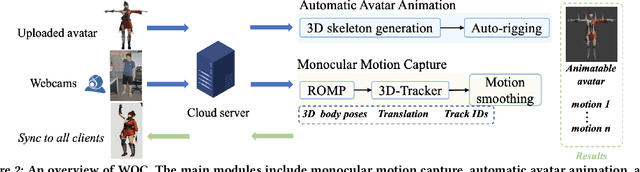
We develop WOC, a webcam-based 3D virtual online chatroom for multi-person interaction, which captures the 3D motion of users and drives their individual 3D virtual avatars in real-time. Compared to the existing wearable equipment-based solution, WOC offers convenient and low-cost 3D motion capture with a single camera. To promote the immersive chat experience, WOC provides high-fidelity virtual avatar manipulation, which also supports the user-defined characters. With the distributed data flow service, the system delivers highly synchronized motion and voice for all users. Deployed on the website and no installation required, users can freely experience the virtual online chat at https://yanch.cloud.
An Embarrassingly Easy but Strong Baseline for Nested Named Entity Recognition
Aug 19, 2022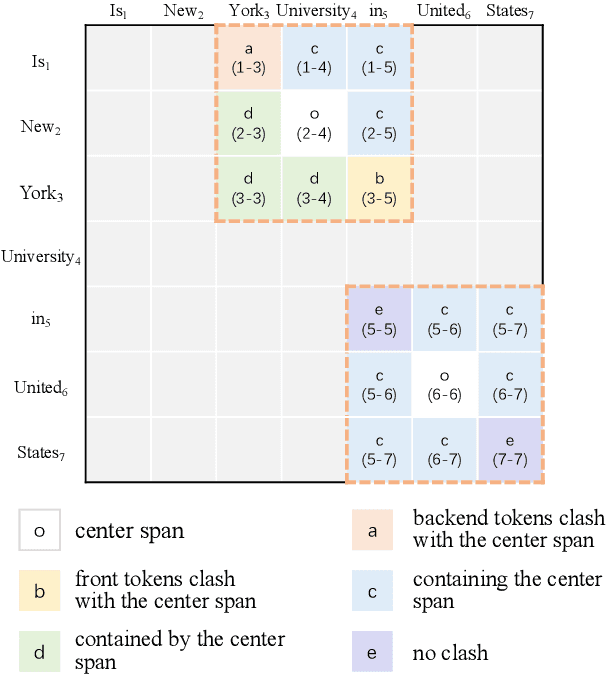
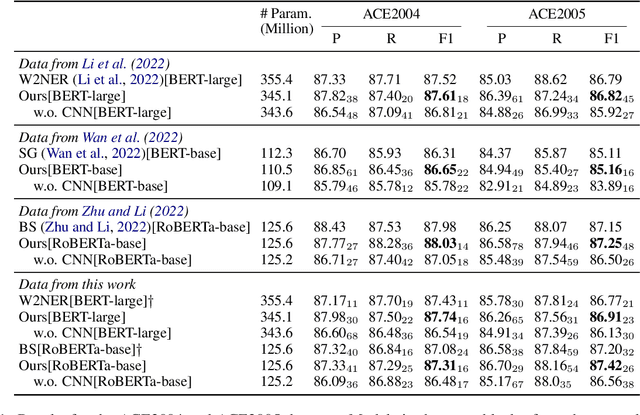
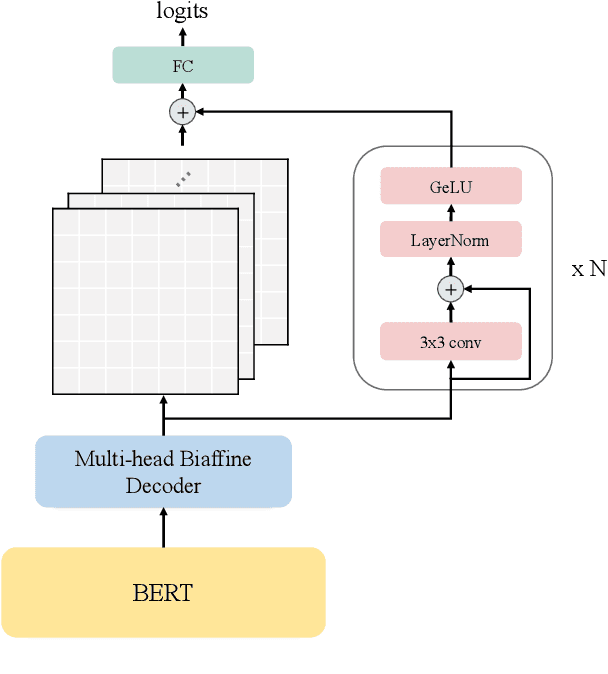
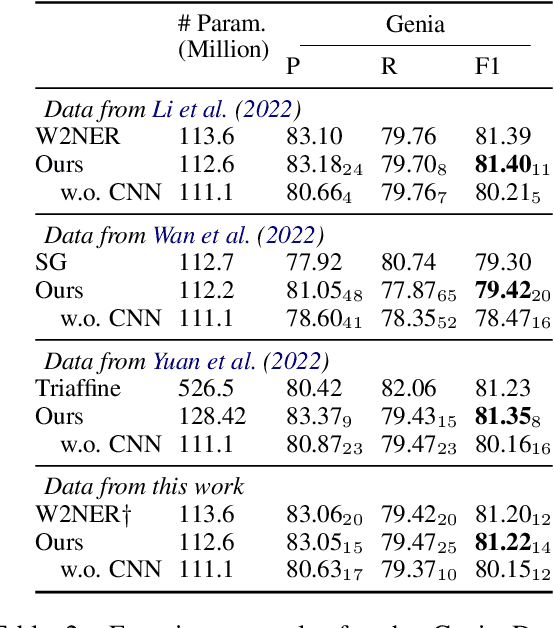
Named entity recognition (NER) is the task to detect and classify the entity spans in the text. When entity spans overlap between each other, this problem is named as nested NER. Span-based methods have been widely used to tackle the nested NER. Most of these methods will get a score $n \times n$ matrix, where $n$ means the length of sentence, and each entry corresponds to a span. However, previous work ignores spatial relations in the score matrix. In this paper, we propose using Convolutional Neural Network (CNN) to model these spatial relations in the score matrix. Despite being simple, experiments in three commonly used nested NER datasets show that our model surpasses several recently proposed methods with the same pre-trained encoders. Further analysis shows that using CNN can help the model find nested entities more accurately. Besides, we found that different papers used different sentence tokenizations for the three nested NER datasets, which will influence the comparison. Thus, we release a pre-processing script to facilitate future comparison.
Approximate Task Tree Retrieval in a Knowledge Network for Robotic Cooking
Jul 08, 2022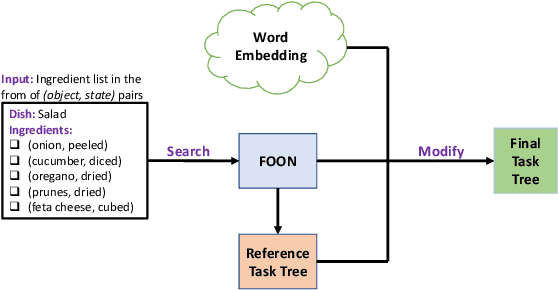
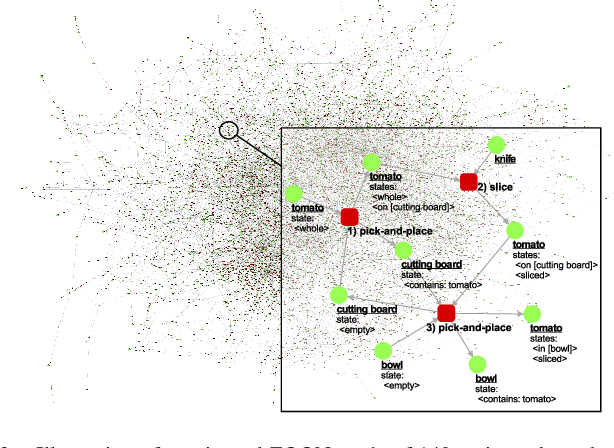
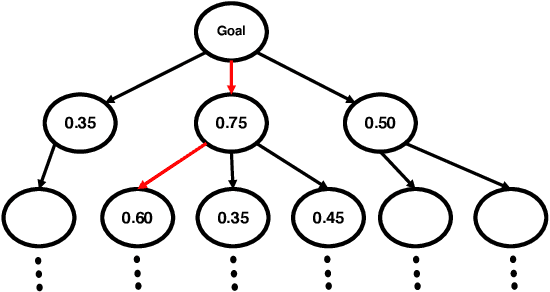
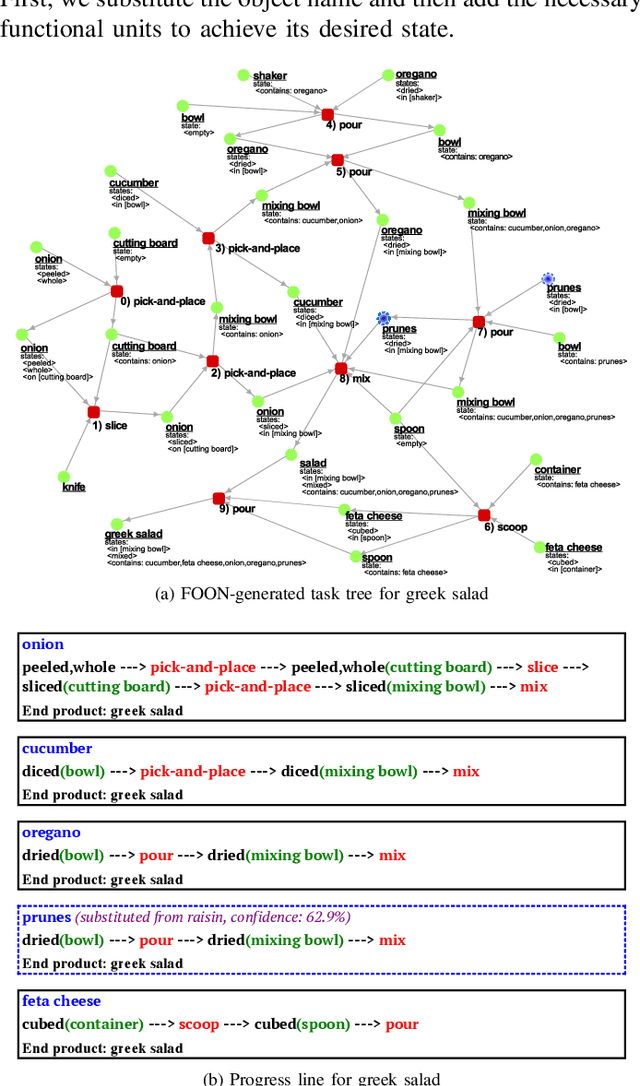
Flexible task planning continues to pose a difficult challenge for robots, where a robot is unable to creatively adapt their task plans to new or unseen problems, which is mainly due to the limited knowledge it has about its actions and world. Motivated by a human's ability to adapt, we explore how task plans from a knowledge graph, known as the Functional Object- Oriented Network (FOON), can be generated for novel problems requiring concepts that are not readily available to the robot in its knowledge base. Knowledge from 140 cooking recipes are structured in a FOON knowledge graph, which is used for acquiring task plan sequences known as task trees. Task trees can be modified to replicate recipes in a FOON knowledge graph format, which can be useful for enriching FOON with new recipes containing unknown object and state combinations, by relying upon semantic similarity. We demonstrate the power of task tree generation to create task trees with never-before-seen ingredient and state combinations as seen in recipes from the Recipe1M+ dataset, with which we evaluate the quality of the trees based on how accurately they depict newly added ingredients. Our experimental results show that our system is able to provide task sequences with 76% correctness.
Multi-Object Grasping -- Types and Taxonomy
May 30, 2022

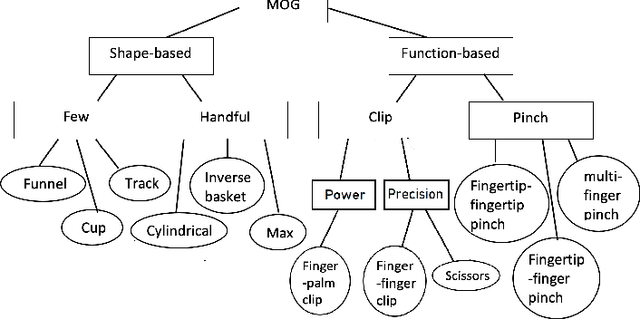

This paper proposes 12 multi-object grasps (MOGs) types from a human and robot grasping data set. The grasp types are then analyzed and organized into a MOG taxonomy. This paper first presents three MOG data collection setups: a human finger tracking setup for multi-object grasping demonstrations, a real system with Barretthand, UR5e arm, and a MOG algorithm, a simulation system with the same settings as the real system. Then the paper describes a novel stochastic grasping routine designed based on a biased random walk to explore the robotic hand's configuration space for feasible MOGs. Based on observations in both the human demonstrations and robotic MOG solutions, this paper proposes 12 MOG types in two groups: shape-based types and function-based types. The new MOG types are compared using six characteristics and then compiled into a taxonomy. This paper then introduces the observed MOG type combinations and shows examples of 16 different combinations.
A General Multiple Data Augmentation Based Framework for Training Deep Neural Networks
May 29, 2022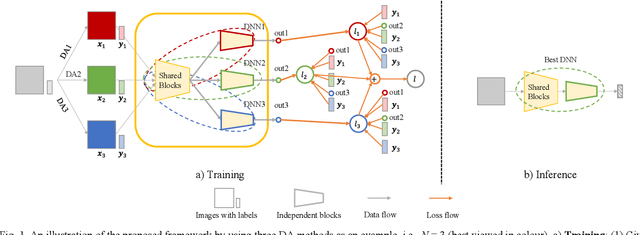

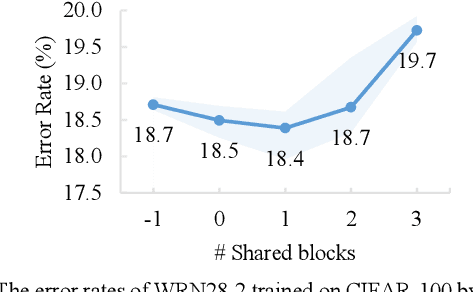
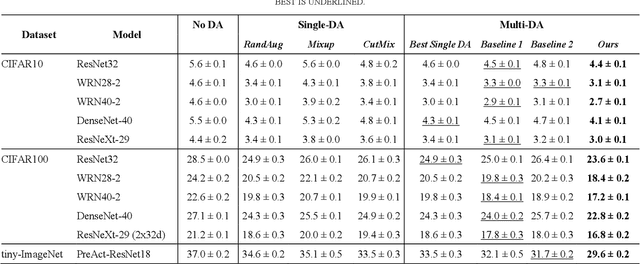
Deep neural networks (DNNs) often rely on massive labelled data for training, which is inaccessible in many applications. Data augmentation (DA) tackles data scarcity by creating new labelled data from available ones. Different DA methods have different mechanisms and therefore using their generated labelled data for DNN training may help improving DNN's generalisation to different degrees. Combining multiple DA methods, namely multi-DA, for DNN training, provides a way to boost generalisation. Among existing multi-DA based DNN training methods, those relying on knowledge distillation (KD) have received great attention. They leverage knowledge transfer to utilise the labelled data sets created by multiple DA methods instead of directly combining them for training DNNs. However, existing KD-based methods can only utilise certain types of DA methods, incapable of utilising the advantages of arbitrary DA methods. We propose a general multi-DA based DNN training framework capable to use arbitrary DA methods. To train a DNN, our framework replicates a certain portion in the latter part of the DNN into multiple copies, leading to multiple DNNs with shared blocks in their former parts and independent blocks in their latter parts. Each of these DNNs is associated with a unique DA and a newly devised loss that allows comprehensively learning from the data generated by all DA methods and the outputs from all DNNs in an online and adaptive way. The overall loss, i.e., the sum of each DNN's loss, is used for training the DNN. Eventually, one of the DNNs with the best validation performance is chosen for inference. We implement the proposed framework by using three distinct DA methods and apply it for training representative DNNs. Experiments on the popular benchmarks of image classification demonstrate the superiority of our method to several existing single-DA and multi-DA based training methods.
Nebula-I: A General Framework for Collaboratively Training Deep Learning Models on Low-Bandwidth Cloud Clusters
May 19, 2022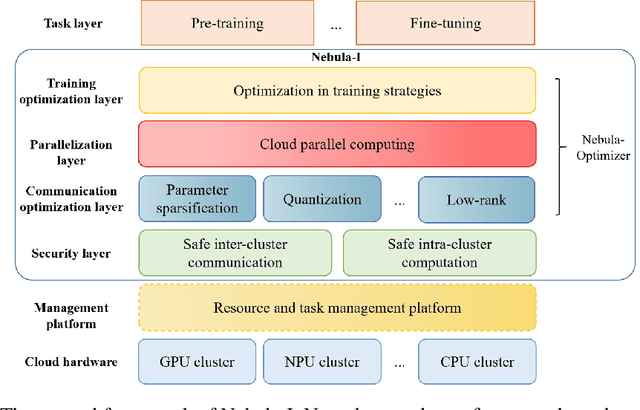
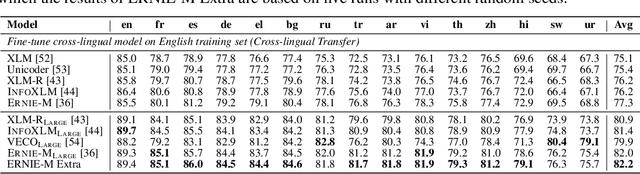
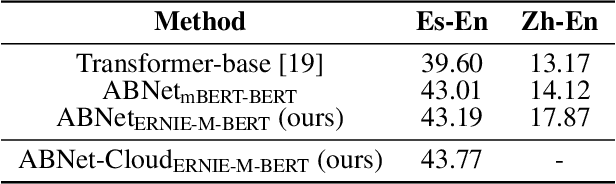
The ever-growing model size and scale of compute have attracted increasing interests in training deep learning models over multiple nodes. However, when it comes to training on cloud clusters, especially across remote clusters, huge challenges are faced. In this work, we introduce a general framework, Nebula-I, for collaboratively training deep learning models over remote heterogeneous clusters, the connections between which are low-bandwidth wide area networks (WANs). We took natural language processing (NLP) as an example to show how Nebula-I works in different training phases that include: a) pre-training a multilingual language model using two remote clusters; and b) fine-tuning a machine translation model using knowledge distilled from pre-trained models, which run through the most popular paradigm of recent deep learning. To balance the accuracy and communication efficiency, in Nebula-I, parameter-efficient training strategies, hybrid parallel computing methods and adaptive communication acceleration techniques are jointly applied. Meanwhile, security strategies are employed to guarantee the safety, reliability and privacy in intra-cluster computation and inter-cluster communication. Nebula-I is implemented with the PaddlePaddle deep learning framework, which can support collaborative training over heterogeneous hardware, e.g. GPU and NPU. Experiments demonstrate that the proposed framework could substantially maximize the training efficiency while preserving satisfactory NLP performance. By using Nebula-I, users can run large-scale training tasks over cloud clusters with minimum developments, and the utility of existed large pre-trained models could be further promoted. We also introduced new state-of-the-art results on cross-lingual natural language inference tasks, which are generated based upon a novel learning framework and Nebula-I.
Simple and Effective Relation-based Embedding Propagation for Knowledge Representation Learning
May 13, 2022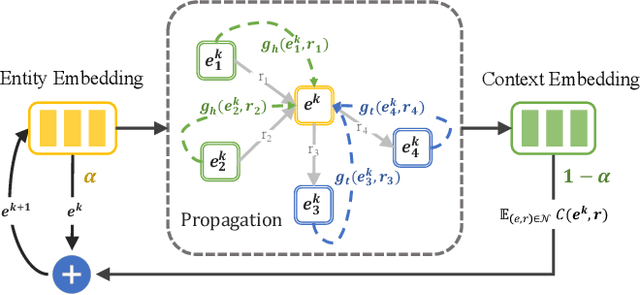

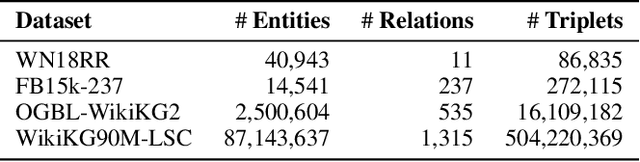
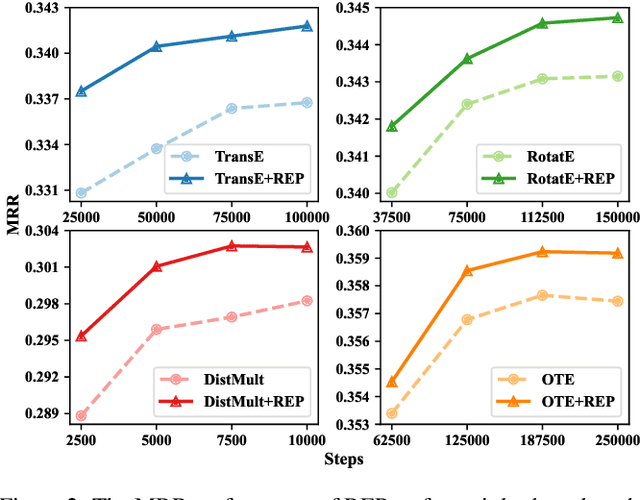
Relational graph neural networks have garnered particular attention to encode graph context in knowledge graphs (KGs). Although they achieved competitive performance on small KGs, how to efficiently and effectively utilize graph context for large KGs remains an open problem. To this end, we propose the Relation-based Embedding Propagation (REP) method. It is a post-processing technique to adapt pre-trained KG embeddings with graph context. As relations in KGs are directional, we model the incoming head context and the outgoing tail context separately. Accordingly, we design relational context functions with no external parameters. Besides, we use averaging to aggregate context information, making REP more computation-efficient. We theoretically prove that such designs can avoid information distortion during propagation. Extensive experiments also demonstrate that REP has significant scalability while improving or maintaining prediction quality. Notably, it averagely brings about 10% relative improvement to triplet-based embedding methods on OGBL-WikiKG2 and takes 5%-83% time to achieve comparable results as the state-of-the-art GC-OTE.