 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt2Auto: From Motion Prompt to Automated Control via Geometry-Invariant One-Shot Gaussian Process Learning
Sep 17, 2025Learning from demonstration allows robots to acquire complex skills from human demonstrations, but conventional approaches often require large datasets and fail to generalize across coordinate transformations. In this paper, we propose Prompt2Auto, a geometry-invariant one-shot Gaussian process (GeoGP) learning framework that enables robots to perform human-guided automated control from a single motion prompt. A dataset-construction strategy based on coordinate transformations is introduced that enforces invariance to translation, rotation, and scaling, while supporting multi-step predictions. Moreover, GeoGP is robust to variations in the user's motion prompt and supports multi-skill autonomy. We validate the proposed approach through numerical simulations with the designed user graphical interface and two real-world robotic experiments, which demonstrate that the proposed method is effective, generalizes across tasks, and significantly reduces the demonstration burden. Project page is available at: https://prompt2auto.github.io
Constraint-Consistent Control of Task-Based and Kinematic RCM Constraints for Surgical Robots
Sep 17, 2025Robotic-assisted minimally invasive surgery (RAMIS) requires precise enforcement of the remote center of motion (RCM) constraint to ensure safe tool manipulation through a trocar. Achieving this constraint under dynamic and interactive conditions remains challenging, as existing control methods either lack robustness at the torque level or do not guarantee consistent RCM constraint satisfaction. This paper proposes a constraint-consistent torque controller that treats the RCM as a rheonomic holonomic constraint and embeds it into a projection-based inverse-dynamics framework. The method unifies task-level and kinematic formulations, enabling accurate tool-tip tracking while maintaining smooth and efficient torque behavior. The controller is validated both in simulation and on a RAMIS training platform, and is benchmarked against state-of-the-art approaches. Results show improved RCM constraint satisfaction, reduced required torque, and robust performance by improving joint torque smoothness through the consistency formulation under clinically relevant scenarios, including spiral trajectories, variable insertion depths, moving trocars, and human interaction. These findings demonstrate the potential of constraint-consistent torque control to enhance safety and reliability in surgical robotics. The project page is available at: https://rcmpc-cube.github.io
Linear Preference Optimization: Decoupled Gradient Control via Absolute Regularization
Aug 20, 2025DPO (Direct Preference Optimization) has become a widely used offline preference optimization algorithm due to its simplicity and training stability. However, DPO is prone to overfitting and collapse. To address these challenges, we propose Linear Preference Optimization (LPO), a novel alignment framework featuring three key innovations. First, we introduce gradient decoupling by replacing the log-sigmoid function with an absolute difference loss, thereby isolating the optimization dynamics. Second, we improve stability through an offset constraint combined with a positive regularization term to preserve the chosen response quality. Third, we implement controllable rejection suppression using gradient separation with straightforward estimation and a tunable coefficient that linearly regulates the descent of the rejection probability. Through extensive experiments, we demonstrate that LPO consistently improves performance on various tasks, including general text tasks, math tasks, and text-to-speech (TTS) tasks. These results establish LPO as a robust and tunable paradigm for preference alignment, and we release the source code, models, and training data publicly.
UGD-IML: A Unified Generative Diffusion-based Framework for Constrained and Unconstrained Image Manipulation Localization
Aug 08, 2025In the digital age, advanced image editing tools pose a serious threat to the integrity of visual content, making image forgery detection and localization a key research focus. Most existing Image Manipulation Localization (IML) methods rely on discriminative learning and require large, high-quality annotated datasets. However, current datasets lack sufficient scale and diversity, limiting model performance in real-world scenarios. To overcome this, recent studies have explored Constrained IML (CIML), which generates pixel-level annotations through algorithmic supervision. However, existing CIML approaches often depend on complex multi-stage pipelines, making the annotation process inefficient. In this work, we propose a novel generative framework based on diffusion models, named UGD-IML, which for the first time unifies both IML and CIML tasks within a single framework. By learning the underlying data distribution, generative diffusion models inherently reduce the reliance on large-scale labeled datasets, allowing our approach to perform effectively even under limited data conditions. In addition, by leveraging a class embedding mechanism and a parameter-sharing design, our model seamlessly switches between IML and CIML modes without extra components or training overhead. Furthermore, the end-to-end design enables our model to avoid cumbersome steps in the data annotation process. Extensive experimental results on multiple datasets demonstrate that UGD-IML outperforms the SOTA methods by an average of 9.66 and 4.36 in terms of F1 metrics for IML and CIML tasks, respectively. Moreover, the proposed method also excels in uncertainty estimation, visualization and robustness.
Graph Federated Learning for Personalized Privacy Recommendation
Aug 08, 2025Federated recommendation systems (FedRecs) have gained significant attention for providing privacy-preserving recommendation services. However, existing FedRecs assume that all users have the same requirements for privacy protection, i.e., they do not upload any data to the server. The approaches overlook the potential to enhance the recommendation service by utilizing publicly available user data. In real-world applications, users can choose to be private or public. Private users' interaction data is not shared, while public users' interaction data can be shared. Inspired by the issue, this paper proposes a novel Graph Federated Learning for Personalized Privacy Recommendation (GFed-PP) that adapts to different privacy requirements while improving recommendation performance. GFed-PP incorporates the interaction data of public users to build a user-item interaction graph, which is then used to form a user relationship graph. A lightweight graph convolutional network (GCN) is employed to learn each user's user-specific personalized item embedding. To protect user privacy, each client learns the user embedding and the scoring function locally. Additionally, GFed-PP achieves optimization of the federated recommendation framework through the initialization of item embedding on clients and the aggregation of the user relationship graph on the server. Experimental results demonstrate that GFed-PP significantly outperforms existing methods for five datasets, offering superior recommendation accuracy without compromising privacy. This framework provides a practical solution for accommodating varying privacy preferences in federated recommendation systems.
Q-CLIP: Unleashing the Power of Vision-Language Models for Video Quality Assessment through Unified Cross-Modal Adaptation
Aug 08, 2025Accurate and efficient Video Quality Assessment (VQA) has long been a key research challenge. Current mainstream VQA methods typically improve performance by pretraining on large-scale classification datasets (e.g., ImageNet, Kinetics-400), followed by fine-tuning on VQA datasets. However, this strategy presents two significant challenges: (1) merely transferring semantic knowledge learned from pretraining is insufficient for VQA, as video quality depends on multiple factors (e.g., semantics, distortion, motion, aesthetics); (2) pretraining on large-scale datasets demands enormous computational resources, often dozens or even hundreds of times greater than training directly on VQA datasets. Recently, Vision-Language Models (VLMs) have shown remarkable generalization capabilities across a wide range of visual tasks, and have begun to demonstrate promising potential in quality assessment. In this work, we propose Q-CLIP, the first fully VLMs-based framework for VQA. Q-CLIP enhances both visual and textual representations through a Shared Cross-Modal Adapter (SCMA), which contains only a minimal number of trainable parameters and is the only component that requires training. This design significantly reduces computational cost. In addition, we introduce a set of five learnable quality-level prompts to guide the VLMs in perceiving subtle quality variations, thereby further enhancing the model's sensitivity to video quality. Furthermore, we investigate the impact of different frame sampling strategies on VQA performance, and find that frame-difference-based sampling leads to better generalization performance across datasets. Extensive experiments demonstrate that Q-CLIP exhibits excellent performance on several VQA datasets.
HiD-VAE: Interpretable Generative Recommendation via Hierarchical and Disentangled Semantic IDs
Aug 06, 2025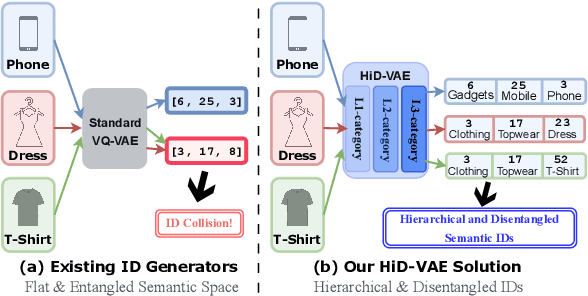
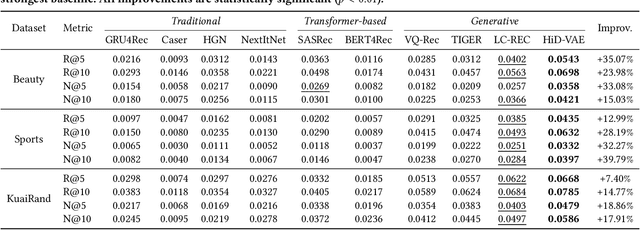
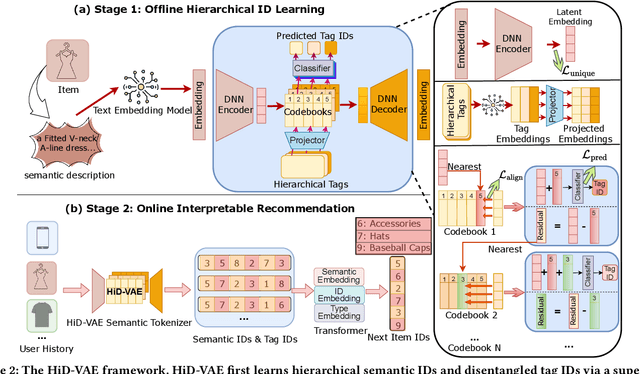
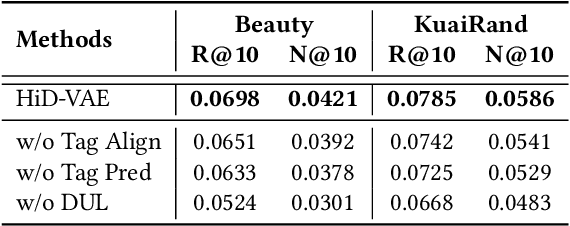
Recommender systems are indispensable for helping users navigate the immense item catalogs of modern online platforms. Recently, generative recommendation has emerged as a promising paradigm, unifying the conventional retrieve-and-rank pipeline into an end-to-end model capable of dynamic generation. However, existing generative methods are fundamentally constrained by their unsupervised tokenization, which generates semantic IDs suffering from two critical flaws: (1) they are semantically flat and uninterpretable, lacking a coherent hierarchy, and (2) they are prone to representation entanglement (i.e., ``ID collisions''), which harms recommendation accuracy and diversity. To overcome these limitations, we propose HiD-VAE, a novel framework that learns hierarchically disentangled item representations through two core innovations. First, HiD-VAE pioneers a hierarchically-supervised quantization process that aligns discrete codes with multi-level item tags, yielding more uniform and disentangled IDs. Crucially, the trained codebooks can predict hierarchical tags, providing a traceable and interpretable semantic path for each recommendation. Second, to combat representation entanglement, HiD-VAE incorporates a novel uniqueness loss that directly penalizes latent space overlap. This mechanism not only resolves the critical ID collision problem but also promotes recommendation diversity by ensuring a more comprehensive utilization of the item representation space. These high-quality, disentangled IDs provide a powerful foundation for downstream generative models. Extensive experiments on three public benchmarks validate HiD-VAE's superior performance against state-of-the-art methods. The code is available at https://anonymous.4open.science/r/HiD-VAE-84B2.
Can One Domain Help Others? A Data-Centric Study on Multi-Domain Reasoning via Reinforcement Learning
Jul 23, 2025Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a powerful paradigm for enhancing the reasoning capabilities of LLMs. Existing research has predominantly concentrated on isolated reasoning domains such as mathematical problem-solving, coding tasks, or logical reasoning. However, real world reasoning scenarios inherently demand an integrated application of multiple cognitive skills. Despite this, the interplay among these reasoning skills under reinforcement learning remains poorly understood. To bridge this gap, we present a systematic investigation of multi-domain reasoning within the RLVR framework, explicitly focusing on three primary domains: mathematical reasoning, code generation, and logical puzzle solving. We conduct a comprehensive study comprising four key components: (1) Leveraging the GRPO algorithm and the Qwen-2.5-7B model family, our study thoroughly evaluates the models' in-domain improvements and cross-domain generalization capabilities when trained on single-domain datasets. (2) Additionally, we examine the intricate interactions including mutual enhancements and conflicts that emerge during combined cross-domain training. (3) To further understand the influence of SFT on RL, we also analyze and compare performance differences between base and instruct models under identical RL configurations. (4) Furthermore, we delve into critical RL training details, systematically exploring the impacts of curriculum learning strategies, variations in reward design, and language-specific factors. Through extensive experiments, our results offer significant insights into the dynamics governing domain interactions, revealing key factors influencing both specialized and generalizable reasoning performance. These findings provide valuable guidance for optimizing RL methodologies to foster comprehensive, multi-domain reasoning capabilities in LLMs.
CanonSwap: High-Fidelity and Consistent Video Face Swapping via Canonical Space Modulation
Jul 03, 2025Video face swapping aims to address two primary challenges: effectively transferring the source identity to the target video and accurately preserving the dynamic attributes of the target face, such as head poses, facial expressions, lip-sync, \etc. Existing methods mainly focus on achieving high-quality identity transfer but often fall short in maintaining the dynamic attributes of the target face, leading to inconsistent results. We attribute this issue to the inherent coupling of facial appearance and motion in videos. To address this, we propose CanonSwap, a novel video face-swapping framework that decouples motion information from appearance information. Specifically, CanonSwap first eliminates motion-related information, enabling identity modification within a unified canonical space. Subsequently, the swapped feature is reintegrated into the original video space, ensuring the preservation of the target face's dynamic attributes. To further achieve precise identity transfer with minimal artifacts and enhanced realism, we design a Partial Identity Modulation module that adaptively integrates source identity features using a spatial mask to restrict modifications to facial regions. Additionally, we introduce several fine-grained synchronization metrics to comprehensively evaluate the performance of video face swapping methods. Extensive experiments demonstrate that our method significantly outperforms existing approaches in terms of visual quality, temporal consistency, and identity preservation. Our project page are publicly available at https://luoxyhappy.github.io/CanonSwap/.
SimpleGVR: A Simple Baseline for Latent-Cascaded Video Super-Resolution
Jun 24, 2025Latent diffusion models have emerged as a leading paradigm for efficient video generation. However, as user expectations shift toward higher-resolution outputs, relying solely on latent computation becomes inadequate. A promising approach involves decoupling the process into two stages: semantic content generation and detail synthesis. The former employs a computationally intensive base model at lower resolutions, while the latter leverages a lightweight cascaded video super-resolution (VSR) model to achieve high-resolution output. In this work, we focus on studying key design principles for latter cascaded VSR models, which are underexplored currently. First, we propose two degradation strategies to generate training pairs that better mimic the output characteristics of the base model, ensuring alignment between the VSR model and its upstream generator. Second, we provide critical insights into VSR model behavior through systematic analysis of (1) timestep sampling strategies, (2) noise augmentation effects on low-resolution (LR) inputs. These findings directly inform our architectural and training innovations. Finally, we introduce interleaving temporal unit and sparse local attention to achieve efficient training and inference, drastically reducing computational overhead. Extensive experiments demonstrate the superiority of our framework over existing methods, with ablation studies confirming the efficacy of each design choice. Our work establishes a simple yet effective baseline for cascaded video super-resolution generation, offering practical insights to guide future advancements in efficient cascaded synthesis systems.