 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKairos: A Native World Model Stack for Physical AI
Jun 16, 2026World models are transitioning from passive visual generators to foundational, operational infrastructure for Physical AI: they must natively acquire world knowledge from heterogeneous experience, maintain persistent states over long horizons, and execute efficiently within real deployment constraints. We introduce Kairos, a native world model stack designed around these requirements. (1) Kairos learns the world by pioneering a Native Pre-training Paradigm governed by a Cross-Embodiment Data Curriculum, which organizes open-world videos, human behavioral data, and robot interactions into a progressive developmental pathway. (2) Kairos maintains the world by unified world understanding, generation, and prediction within a Native Unified Architecture equipped with Hybrid Linear Temporal Attention, where sliding-window attention captures local dynamics, dilated sliding windows capture mid-range dependencies, and gated linear attention maintains persistent global memory. We establish formal theoretical bounds demonstrating that this temporal factorization strictly limits error accumulation, mathematically guaranteeing state propagation across extended horizons. (3) Kairos runs the world by incorporating a Deployment-Aware System Co-Design to support low-latency rollout generation on server and consumer-grade hardware for real-world observation-action-feedback loops. Experiments on embodied world-model, long-horizon, and action-policy benchmarks show that Kairos achieves top level performance while offering a strong efficiency-capability trade-off. Together, these results position Kairos as a cohesive operational foundation for future self-evolving physical intelligence.
Test-Time Scaling in Multimodal Foundation Models: A Comprehensive Survey of Generation and Reasoning
Jun 06, 2026Test-time Scaling (TTS) has emerged as a pivotal research direction for enhancing model performance by dynamically allocating computational resources during inference. Recent advancements have adapted this paradigm to Multimodal Foundation Models (MFMs), unlocking their potential in multimodal reasoning and generation. Despite rapid progress, the field lacks a systematic survey and unified theoretical framework to delineate the developmental landscape of multimodal TTS. To bridge this gap, we present the first comprehensive review of TTS research for MFMs, proposing a unified taxonomic framework that categorizes existing methodologies into three distinct strategies: sampling-based, feedback-based, and search-based approaches. We further summarize representative applications and benchmarks commonly utilized to evaluate multimodal TTS capabilities in generation and reasoning tasks. Finally, this survey discusses open challenges and outlines future research directions, providing a systematic roadmap for subsequent studies in this rapidly evolving field.
ProSR: Process-Shaped Spatial Reasoning for Reliable Chain-of-Thought in VLMs
May 25, 2026Reliable spatial reasoning remains a core bottleneck for vision-language models (VLMs). Existing mainstream training paradigms for spatial reasoning largely rely on outcome alignment or process imitation, lacking explicit constraints on the reasoning process, and therefore struggle to ensure genuine visual dependence and stable reasoning trajectories. In this paper, we construct a high-quality CoT dataset covering diverse spatial phenomena and diagnose the model's reasoning process, revealing two typical types of process degradation during reinforcement learning optimization: Spurious Grounding, which bypasses visual evidence, and Tail Instability, where uncertainty abnormally rises in the later stage of reasoning. To address these issues, we propose ProSR, a process-shaping optimization framework for spatial reasoning. Through a Counterfactual Invariance Penalty and a Tail Drift Penalty, ProSR extends the optimization objective from single answer correctness to two process-level dimensions: visual dependence and trajectory stability. Experiments on multiple complex and out-of-distribution spatial reasoning benchmarks show that ProSR improves answer accuracy while generating reasoning trajectories that are more stable and more dependent on visual evidence.
Retrieve-then-Steer: Online Success Memory for Test-Time Adaptation of Generative VLAs
May 11, 2026Vision-Language-Action (VLA) models show strong potential for general-purpose robotic manipulation, yet their closed-loop reliability often degrades under local deployment conditions. Existing evaluations typically treat test episodes as independent zero-shot trials. However, real robots often operate repeatedly in the same or slowly changing environments, where successful executions provide environment-verified evidence of reliable behavior patterns. We study this persistent-deployment setting, asking whether a partially competent frozen VLA can improve its reliability by reusing its successful test-time experience. We propose an online success-memory guided test-time adaptation framework for generative VLAs. During deployment, the robot stores progress-calibrated successful observation-action segments in a long-term memory. At inference, it retrieves state-relevant action chunks, filters inconsistent candidates via trajectory-level consistency, and aggregates them into an elite action prior. To incorporate this prior into action generation, we introduce confidence-adaptive prior guidance, which injects the elite prior into an intermediate state of the flow-matching action sampler and adjusts the guidance strength based on retrieval confidence. This design allows the frozen VLA to exploit environment-specific successful experience while preserving observation-conditioned generative refinement. This retrieve-then-steer mechanism enables lightweight, non-parametric test-time adaptation without requiring parameter updates. Simulation and real-world experiments show improved task success and closed-loop stability, especially in long-horizon and multi-stage tasks.
Trajectory-Diversity-Driven Robust Vision-and-Language Navigation
Mar 16, 2026Vision-and-Language Navigation (VLN) requires agents to navigate photo-realistic environments following natural language instructions. Current methods predominantly rely on imitation learning, which suffers from limited generalization and poor robustness to execution perturbations. We present NavGRPO, a reinforcement learning framework that learns goal-directed navigation policies through Group Relative Policy Optimization. By exploring diverse trajectories and optimizing via within-group performance comparisons, our method enables agents to distinguish effective strategies beyond expert paths without requiring additional value networks. Built on ScaleVLN, NavGRPO achieves superior robustness on R2R and REVERIE benchmarks with +3.0% and +1.71% SPL improvements in unseen environments. Under extreme early-stage perturbations, we demonstrate +14.89% SPL gain over the baseline, confirming that goal-directed RL training builds substantially more robust navigation policies. Code and models will be released.
ReMoT: Reinforcement Learning with Motion Contrast Triplets
Feb 28, 2026We present ReMoT, a unified training paradigm to systematically address the fundamental shortcomings of VLMs in spatio-temporal consistency -- a critical failure point in navigation, robotics, and autonomous driving. ReMoT integrates two core components: (1) A rule-based automatic framework that generates ReMoT-16K, a large-scale (16.5K triplets) motion-contrast dataset derived from video meta-annotations, surpassing costly manual or model-based generation. (2) Group Relative Policy Optimization, which we empirically validate yields optimal performance and data efficiency for learning this contrastive reasoning, far exceeding standard Supervised Fine-Tuning. We also construct the first benchmark for fine-grained motion contrast triplets to measure a VLM's discrimination of subtle motion attributes (e.g., opposing directions). The resulting model achieves state-of-the-art performance on our new benchmark and multiple standard VLM benchmarks, culminating in a remarkable 25.1% performance leap on spatio-temporal reasoning tasks.
CanonSwap: High-Fidelity and Consistent Video Face Swapping via Canonical Space Modulation
Jul 03, 2025Video face swapping aims to address two primary challenges: effectively transferring the source identity to the target video and accurately preserving the dynamic attributes of the target face, such as head poses, facial expressions, lip-sync, \etc. Existing methods mainly focus on achieving high-quality identity transfer but often fall short in maintaining the dynamic attributes of the target face, leading to inconsistent results. We attribute this issue to the inherent coupling of facial appearance and motion in videos. To address this, we propose CanonSwap, a novel video face-swapping framework that decouples motion information from appearance information. Specifically, CanonSwap first eliminates motion-related information, enabling identity modification within a unified canonical space. Subsequently, the swapped feature is reintegrated into the original video space, ensuring the preservation of the target face's dynamic attributes. To further achieve precise identity transfer with minimal artifacts and enhanced realism, we design a Partial Identity Modulation module that adaptively integrates source identity features using a spatial mask to restrict modifications to facial regions. Additionally, we introduce several fine-grained synchronization metrics to comprehensively evaluate the performance of video face swapping methods. Extensive experiments demonstrate that our method significantly outperforms existing approaches in terms of visual quality, temporal consistency, and identity preservation. Our project page are publicly available at https://luoxyhappy.github.io/CanonSwap/.
GridShow: Omni Visual Generation
Dec 17, 2024In this paper, we introduce GRID, a novel paradigm that reframes a broad range of visual generation tasks as the problem of arranging grids, akin to film strips. At its core, GRID transforms temporal sequences into grid layouts, enabling image generation models to process visual sequences holistically. To achieve both layout consistency and motion coherence, we develop a parallel flow-matching training strategy that combines layout matching and temporal losses, guided by a coarse-to-fine schedule that evolves from basic layouts to precise motion control. Our approach demonstrates remarkable efficiency, achieving up to 35 faster inference speeds while using 1/1000 of the computational resources compared to specialized models. Extensive experiments show that GRID exhibits exceptional versatility across diverse visual generation tasks, from Text-to-Video to 3D Editing, while maintaining its foundational image generation capabilities. This dual strength in both expanded applications and preserved core competencies establishes GRID as an efficient and versatile omni-solution for visual generation.
Prompt-Agnostic Adversarial Perturbation for Customized Diffusion Models
Aug 20, 2024



Diffusion models have revolutionized customized text-to-image generation, allowing for efficient synthesis of photos from personal data with textual descriptions. However, these advancements bring forth risks including privacy breaches and unauthorized replication of artworks. Previous researches primarily center around using prompt-specific methods to generate adversarial examples to protect personal images, yet the effectiveness of existing methods is hindered by constrained adaptability to different prompts. In this paper, we introduce a Prompt-Agnostic Adversarial Perturbation (PAP) method for customized diffusion models. PAP first models the prompt distribution using a Laplace Approximation, and then produces prompt-agnostic perturbations by maximizing a disturbance expectation based on the modeled distribution. This approach effectively tackles the prompt-agnostic attacks, leading to improved defense stability. Extensive experiments in face privacy and artistic style protection, demonstrate the superior generalization of our method in comparison to existing techniques.
A novel sentence embedding based topic detection method for micro-blog
Jun 10, 2020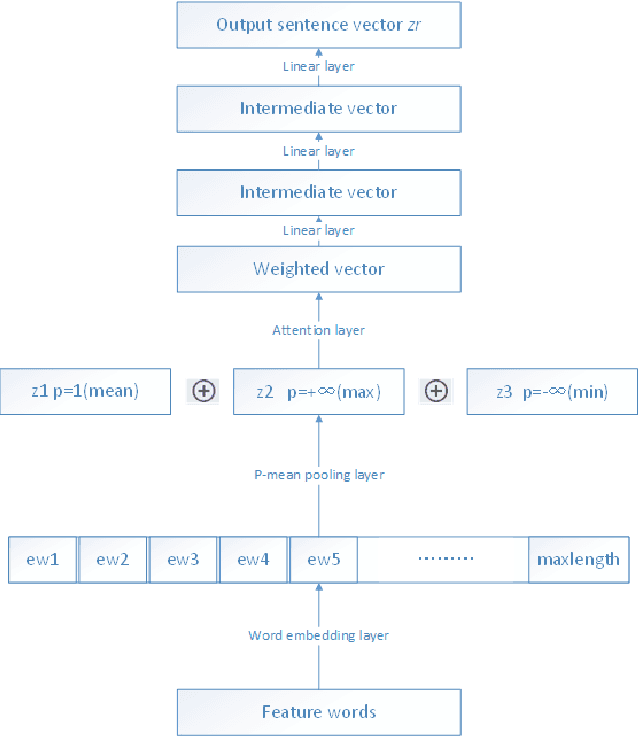
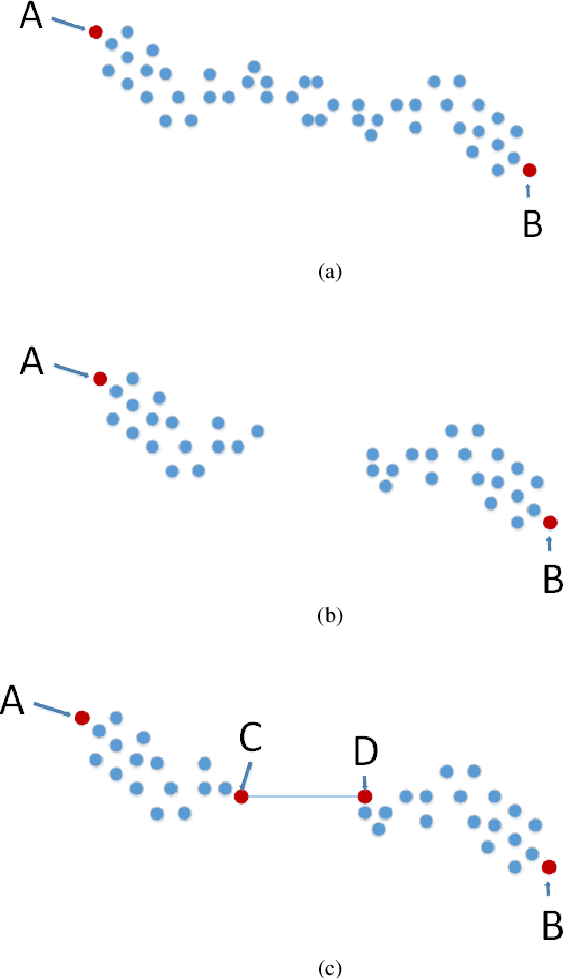
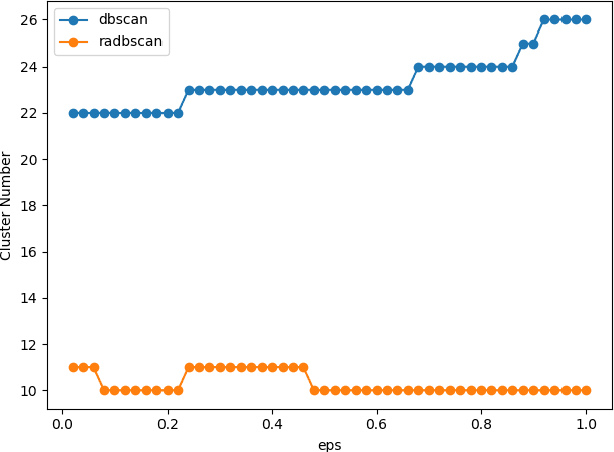
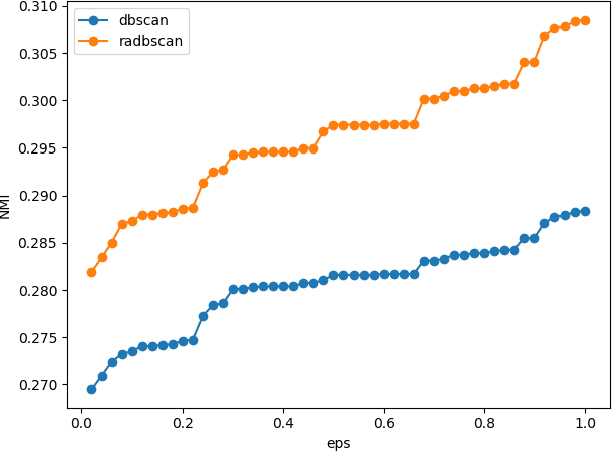
Topic detection is a challenging task, especially without knowing the exact number of topics. In this paper, we present a novel approach based on neural network to detect topics in the micro-blogging dataset. We use an unsupervised neural sentence embedding model to map the blogs to an embedding space. Our model is a weighted power mean word embedding model, and the weights are calculated by attention mechanism. Experimental result shows our embedding method performs better than baselines in sentence clustering. In addition, we propose an improved clustering algorithm referred as relationship-aware DBSCAN (RADBSCAN). It can discover topics from a micro-blogging dataset, and the topic number depends on dataset character itself. Moreover, in order to solve the problem of parameters sensitive, we take blog forwarding relationship as a bridge of two independent clusters. Finally, we validate our approach on a dataset from sina micro-blog. The result shows that we can detect all the topics successfully and extract keywords in each topic.