 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKD-NVC: A Search-and-Distill Framework to Accelerate Neural Video Coding
Jun 03, 2026While neural video coding (NVC) has achieved remarkable rate-distortion performance, real-time decoding on edge devices has become an important demand but remains limited by high complexity. Knowledge distillation (KD) is widely used for model acceleration, yet its application to NVC faces critical challenges. Specifically, the heterogeneity of NVC sub-modules renders uniform architectural reduction suboptimal, necessitating a per-module design for better rate-distortion-speed trade-off. However, searching for diverse architectures via existing neural architecture search (NAS) algorithms is unaffordable due to the expensive training cost of neural video codecs. Moreover, after the lightweight architecture is determined, existing distillation methods overlook the feature-energy sparsity induced by the rate-constraint, which is essential for maintaining compression performance. To address these issues, we propose a two-stage distillation framework KD-NVC. In the first stage, we introduce an acceleration-efficiency-based neural architecture search (AE-NAS) algorithm. It explores the module-wise Pareto frontier to adaptively allocate the acceleration budget across heterogeneous modules. Also, it introduces the acceleration-efficiency metric to determine the final student architecture without practically training all architecture-level candidates. In the second stage, we design an energy-aware feature distillation (EFD) loss that aligns the spatially-aggregated feature-energy signatures between the teacher and student codecs, transferring the rate-induced sparsity patterns for better compression efficiency. Experimental results demonstrate that the proposed framework consistently outperforms existing codec-oriented distillation methods, and achieves 69 FPS decoding at 1080p on RTX 5060 while maintaining comparable RD performance to VTM-LDB.
GT-PCQA: Geometry-Texture Decoupled Point Cloud Quality Assessment with MLLM
Mar 16, 2026With the rapid advancement of Multi-modal Large Language Models (MLLMs), MLLM-based Image Quality Assessment (IQA) methods have shown promising generalization. However, directly extending these MLLM-based IQA methods to PCQA remains challenging. On the one hand, existing PCQA datasets are limited in scale, which hinders stable and effective instruction tuning of MLLMs. On the other hand, due to large-scale image-text pretraining, MLLMs tend to rely on texture-dominant reasoning and are insufficiently sensitive to geometric structural degradations that are critical for PCQA. To address these gaps, we propose a novel MLLM-based no-reference PCQA framework, termed GT-PCQA, which is built upon two key strategies. First, to enable stable and effective instruction tuning under scarce PCQA supervision, a 2D-3D joint training strategy is proposed. This strategy formulates PCQA as a relative quality comparison problem to unify large-scale IQA datasets with limited PCQA datasets. It incorporates a parameter-efficient Low-Rank Adaptation (LoRA) scheme to support instruction tuning. Second, a geometry-texture decoupling strategy is presented, which integrates a dual-prompt mechanism with an alternating optimization scheme to mitigate the inherent texture-dominant bias of pre-trained MLLMs, while enhancing sensitivity to geometric structural degradations. Extensive experiments demonstrate that GT-PCQA achieves competitive performance and exhibits strong generalization.
R4-CGQA: Retrieval-based Vision Language Models for Computer Graphics Image Quality Assessment
Mar 11, 2026Immersive Computer Graphics (CGs) rendering has become ubiquitous in modern daily life. However, comprehensively evaluating CG quality remains challenging for two reasons: First, existing CG datasets lack systematic descriptions of rendering quality; and second existing CG quality assessment methods cannot provide reasonable text-based explanations. To address these issues, we first identify six key perceptual dimensions of CG quality from the user perspective and construct a dataset of 3500 CG images with corresponding quality descriptions. Each description covers CG style, content, and perceived quality along the selected dimensions. Furthermore, we use a subset of the dataset to build several question-answer benchmarks based on the descriptions in order to evaluate the responses of existing Vision Language Models (VLMs). We find that current VLMs are not sufficiently accurate in judging fine-grained CG quality, but that descriptions of visually similar images can significantly improve a VLM's understanding of a given CG image. Motivated by this observation, we adopt retrieval-augmented generation and propose a two-stream retrieval framework that effectively enhances the CG quality assessment capabilities of VLMs. Experiments on several representative VLMs demonstrate that our method substantially improves their performance on CG quality assessment.
QD-PCQA: Quality-Aware Domain Adaptation for Point Cloud Quality Assessment
Mar 04, 2026No-Reference Point Cloud Quality Assessment (NR-PCQA) still struggles with generalization, primarily due to the scarcity of annotated point cloud datasets. Since the Human Visual System (HVS) drives perceptual quality assessment independently of media types, prior knowledge on quality learned from images can be repurposed for point clouds. This insight motivates adopting Unsupervised Domain Adaptation (UDA) to transfer quality-relevant priors from labeled images to unlabeled point clouds. However, existing UDA-based PCQA methods often overlook key characteristics of perceptual quality, such as sensitivity to quality ranking and quality-aware feature alignment, thereby limiting their effectiveness. To address these issues, we propose a novel Quality-aware Domain adaptation framework for PCQA, termed QD-PCQA. The framework comprises two main components: i) a Rank-weighted Conditional Alignment (RCA) strategy that aligns features under consistent quality levels and adaptively emphasizes misranked samples to reinforce perceptual quality ranking awareness; and ii) a Quality-guided Feature Augmentation (QFA) strategy, which includes quality-guided style mixup, multi-layer extension, and dual-domain augmentation modules to augment perceptual feature alignment. Extensive cross-domain experiments demonstrate that QD-PCQA significantly improves generalization in NR-PCQA tasks. The code is available at https://github.com/huhu-code/QD-PCQA.
Scaling Audio-Visual Quality Assessment Dataset via Crowdsourcing
Feb 26, 2026Audio-visual quality assessment (AVQA) research has been stalled by limitations of existing datasets: they are typically small in scale, with insufficient diversity in content and quality, and annotated only with overall scores. These shortcomings provide limited support for model development and multimodal perception research. We propose a practical approach for AVQA dataset construction. First, we design a crowdsourced subjective experiment framework for AVQA, breaks the constraints of in-lab settings and achieves reliable annotation across varied environments. Second, a systematic data preparation strategy is further employed to ensure broad coverage of both quality levels and semantic scenarios. Third, we extend the dataset with additional annotations, enabling research on multimodal perception mechanisms and their relation to content. Finally, we validate this approach through YT-NTU-AVQ, the largest and most diverse AVQA dataset to date, consisting of 1,620 user-generated audio and video (A/V) sequences. The dataset and platform code are available at https://github.com/renyu12/YT-NTU-AVQ
MUGSQA: Novel Multi-Uncertainty-Based Gaussian Splatting Quality Assessment Method, Dataset, and Benchmarks
Nov 10, 2025



Gaussian Splatting (GS) has recently emerged as a promising technique for 3D object reconstruction, delivering high-quality rendering results with significantly improved reconstruction speed. As variants continue to appear, assessing the perceptual quality of 3D objects reconstructed with different GS-based methods remains an open challenge. To address this issue, we first propose a unified multi-distance subjective quality assessment method that closely mimics human viewing behavior for objects reconstructed with GS-based methods in actual applications, thereby better collecting perceptual experiences. Based on it, we also construct a novel GS quality assessment dataset named MUGSQA, which is constructed considering multiple uncertainties of the input data. These uncertainties include the quantity and resolution of input views, the view distance, and the accuracy of the initial point cloud. Moreover, we construct two benchmarks: one to evaluate the robustness of various GS-based reconstruction methods under multiple uncertainties, and the other to evaluate the performance of existing quality assessment metrics. Our dataset and benchmark code will be released soon.
UGD-IML: A Unified Generative Diffusion-based Framework for Constrained and Unconstrained Image Manipulation Localization
Aug 08, 2025In the digital age, advanced image editing tools pose a serious threat to the integrity of visual content, making image forgery detection and localization a key research focus. Most existing Image Manipulation Localization (IML) methods rely on discriminative learning and require large, high-quality annotated datasets. However, current datasets lack sufficient scale and diversity, limiting model performance in real-world scenarios. To overcome this, recent studies have explored Constrained IML (CIML), which generates pixel-level annotations through algorithmic supervision. However, existing CIML approaches often depend on complex multi-stage pipelines, making the annotation process inefficient. In this work, we propose a novel generative framework based on diffusion models, named UGD-IML, which for the first time unifies both IML and CIML tasks within a single framework. By learning the underlying data distribution, generative diffusion models inherently reduce the reliance on large-scale labeled datasets, allowing our approach to perform effectively even under limited data conditions. In addition, by leveraging a class embedding mechanism and a parameter-sharing design, our model seamlessly switches between IML and CIML modes without extra components or training overhead. Furthermore, the end-to-end design enables our model to avoid cumbersome steps in the data annotation process. Extensive experimental results on multiple datasets demonstrate that UGD-IML outperforms the SOTA methods by an average of 9.66 and 4.36 in terms of F1 metrics for IML and CIML tasks, respectively. Moreover, the proposed method also excels in uncertainty estimation, visualization and robustness.
LatexBlend: Scaling Multi-concept Customized Generation with Latent Textual Blending
Mar 10, 2025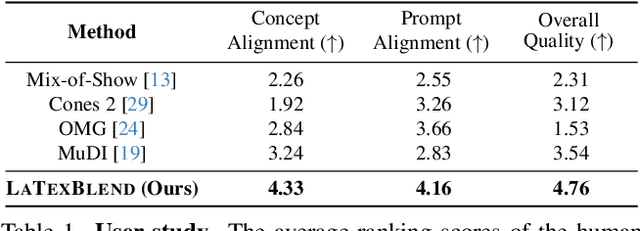
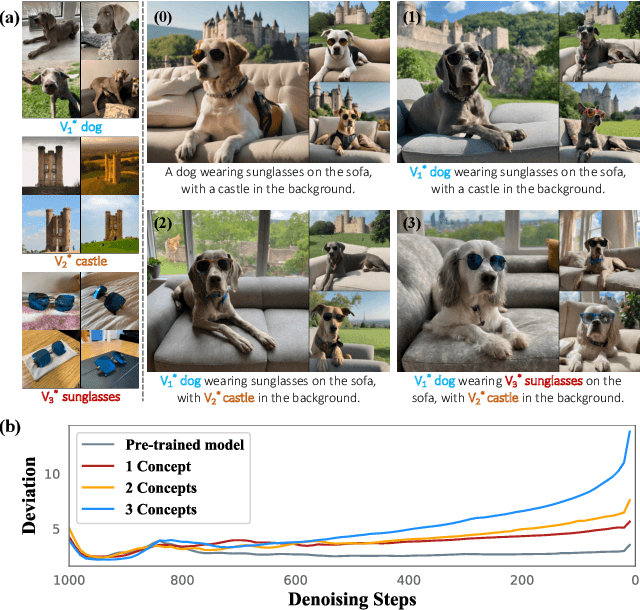
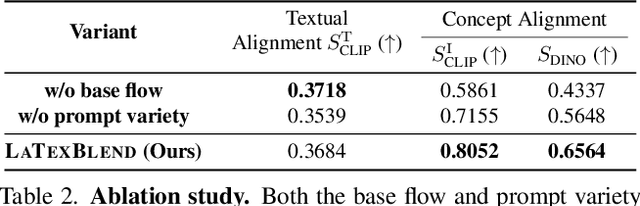
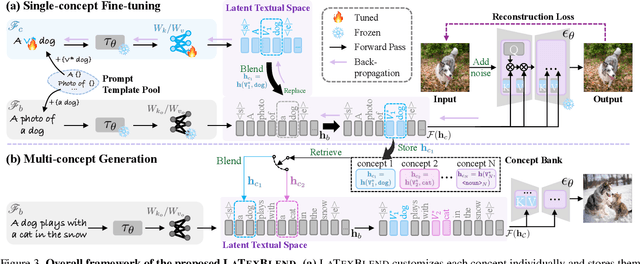
Customized text-to-image generation renders user-specified concepts into novel contexts based on textual prompts. Scaling the number of concepts in customized generation meets a broader demand for user creation, whereas existing methods face challenges with generation quality and computational efficiency. In this paper, we propose LaTexBlend, a novel framework for effectively and efficiently scaling multi-concept customized generation. The core idea of LaTexBlend is to represent single concepts and blend multiple concepts within a Latent Textual space, which is positioned after the text encoder and a linear projection. LaTexBlend customizes each concept individually, storing them in a concept bank with a compact representation of latent textual features that captures sufficient concept information to ensure high fidelity. At inference, concepts from the bank can be freely and seamlessly combined in the latent textual space, offering two key merits for multi-concept generation: 1) excellent scalability, and 2) significant reduction of denoising deviation, preserving coherent layouts. Extensive experiments demonstrate that LaTexBlend can flexibly integrate multiple customized concepts with harmonious structures and high subject fidelity, substantially outperforming baselines in both generation quality and computational efficiency. Our code will be publicly available.
Twofold Debiasing Enhances Fine-Grained Learning with Coarse Labels
Feb 27, 2025



The Coarse-to-Fine Few-Shot (C2FS) task is designed to train models using only coarse labels, then leverages a limited number of subclass samples to achieve fine-grained recognition capabilities. This task presents two main challenges: coarse-grained supervised pre-training suppresses the extraction of critical fine-grained features for subcategory discrimination, and models suffer from overfitting due to biased distributions caused by limited fine-grained samples. In this paper, we propose the Twofold Debiasing (TFB) method, which addresses these challenges through detailed feature enhancement and distribution calibration. Specifically, we introduce a multi-layer feature fusion reconstruction module and an intermediate layer feature alignment module to combat the model's tendency to focus on simple predictive features directly related to coarse-grained supervision, while neglecting complex fine-grained level details. Furthermore, we mitigate the biased distributions learned by the fine-grained classifier using readily available coarse-grained sample embeddings enriched with fine-grained information. Extensive experiments conducted on five benchmark datasets demonstrate the efficacy of our approach, achieving state-of-the-art results that surpass competitive methods.
Noise May Contain Transferable Knowledge: Understanding Semi-supervised Heterogeneous Domain Adaptation from an Empirical Perspective
Feb 19, 2025



Semi-supervised heterogeneous domain adaptation (SHDA) addresses learning across domains with distinct feature representations and distributions, where source samples are labeled while most target samples are unlabeled, with only a small fraction labeled. Moreover, there is no one-to-one correspondence between source and target samples. Although various SHDA methods have been developed to tackle this problem, the nature of the knowledge transferred across heterogeneous domains remains unclear. This paper delves into this question from an empirical perspective. We conduct extensive experiments on about 330 SHDA tasks, employing two supervised learning methods and seven representative SHDA methods. Surprisingly, our observations indicate that both the category and feature information of source samples do not significantly impact the performance of the target domain. Additionally, noise drawn from simple distributions, when used as source samples, may contain transferable knowledge. Based on this insight, we perform a series of experiments to uncover the underlying principles of transferable knowledge in SHDA. Specifically, we design a unified Knowledge Transfer Framework (KTF) for SHDA. Based on the KTF, we find that the transferable knowledge in SHDA primarily stems from the transferability and discriminability of the source domain. Consequently, ensuring those properties in source samples, regardless of their origin (e.g., image, text, noise), can enhance the effectiveness of knowledge transfer in SHDA tasks. The codes and datasets are available at https://github.com/yyyaoyuan/SHDA.