 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoREPA: Learning Physics for Video Generation through Relational Alignment with Foundation Models
May 29, 2025Recent advancements in text-to-video (T2V) diffusion models have enabled high-fidelity and realistic video synthesis. However, current T2V models often struggle to generate physically plausible content due to their limited inherent ability to accurately understand physics. We found that while the representations within T2V models possess some capacity for physics understanding, they lag significantly behind those from recent video self-supervised learning methods. To this end, we propose a novel framework called VideoREPA, which distills physics understanding capability from video understanding foundation models into T2V models by aligning token-level relations. This closes the physics understanding gap and enable more physics-plausible generation. Specifically, we introduce the Token Relation Distillation (TRD) loss, leveraging spatio-temporal alignment to provide soft guidance suitable for finetuning powerful pre-trained T2V models, a critical departure from prior representation alignment (REPA) methods. To our knowledge, VideoREPA is the first REPA method designed for finetuning T2V models and specifically for injecting physical knowledge. Empirical evaluations show that VideoREPA substantially enhances the physics commonsense of baseline method, CogVideoX, achieving significant improvement on relevant benchmarks and demonstrating a strong capacity for generating videos consistent with intuitive physics. More video results are available at https://videorepa.github.io/.
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
May 28, 2025



This paper aims to overcome a major obstacle in scaling RL for reasoning with LLMs, namely the collapse of policy entropy. Such phenomenon is consistently observed across vast RL runs without entropy intervention, where the policy entropy dropped sharply at the early training stage, this diminished exploratory ability is always accompanied with the saturation of policy performance. In practice, we establish a transformation equation R=-a*e^H+b between entropy H and downstream performance R. This empirical law strongly indicates that, the policy performance is traded from policy entropy, thus bottlenecked by its exhaustion, and the ceiling is fully predictable H=0, R=-a+b. Our finding necessitates entropy management for continuous exploration toward scaling compute for RL. To this end, we investigate entropy dynamics both theoretically and empirically. Our derivation highlights that, the change in policy entropy is driven by the covariance between action probability and the change in logits, which is proportional to its advantage when using Policy Gradient-like algorithms. Empirical study shows that, the values of covariance term and entropy differences matched exactly, supporting the theoretical conclusion. Moreover, the covariance term stays mostly positive throughout training, further explaining why policy entropy would decrease monotonically. Through understanding the mechanism behind entropy dynamics, we motivate to control entropy by restricting the update of high-covariance tokens. Specifically, we propose two simple yet effective techniques, namely Clip-Cov and KL-Cov, which clip and apply KL penalty to tokens with high covariances respectively. Experiments show that these methods encourage exploration, thus helping policy escape entropy collapse and achieve better downstream performance.
FGS-Audio: Fixed-Decoder Framework for Audio Steganography with Adversarial Perturbation Generation
May 28, 2025



The rapid development of Artificial Intelligence Generated Content (AIGC) has made high-fidelity generated audio widely available across the Internet, offering an abundant and versatile source of cover signals for covert communication. Driven by advances in deep learning, current audio steganography frameworks are mainly based on encoding-decoding network architectures. While these methods greatly improve the security of audio steganography, they typically employ elaborate training workflows and rely on extensive pre-trained models. To address the aforementioned issues, this paper pioneers a Fixed-Decoder Framework for Audio Steganography with Adversarial Perturbation Generation (FGS-Audio). The adversarial perturbations that carry secret information are embedded into cover audio to generate stego audio. The receiver only needs to share the structure and weights of the fixed decoding network to accurately extract the secret information from the stego audio, thus eliminating the reliance on large pre-trained models. In FGS-Audio, we propose an audio Adversarial Perturbation Generation (APG) strategy and design a lightweight fixed decoder. The fixed decoder guarantees reliable extraction of the hidden message, while the adversarial perturbations are optimized to keep the stego audio perceptually and statistically close to the cover audio, thereby improving resistance to steganalysis. The experimental results show that the method exhibits excellent anti-steganalysis performance under different relative payloads, outperforming existing SOTA approaches. In terms of stego audio quality, FGS-Audio achieves an average PSNR improvement of over 10 dB compared to SOTA method.
Structured Memory Mechanisms for Stable Context Representation in Large Language Models
May 28, 2025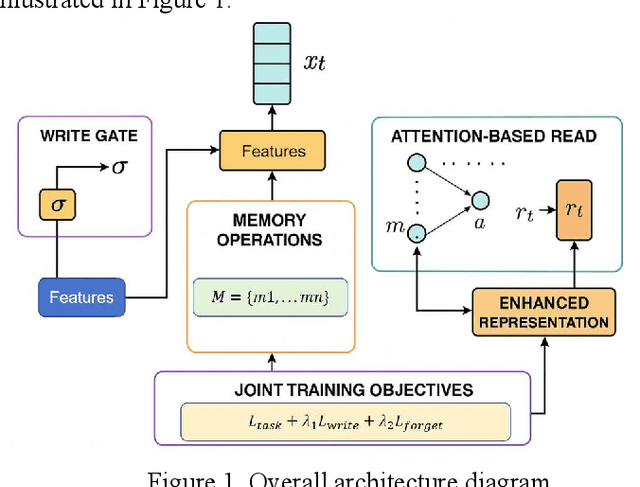
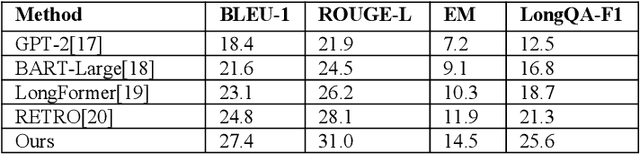
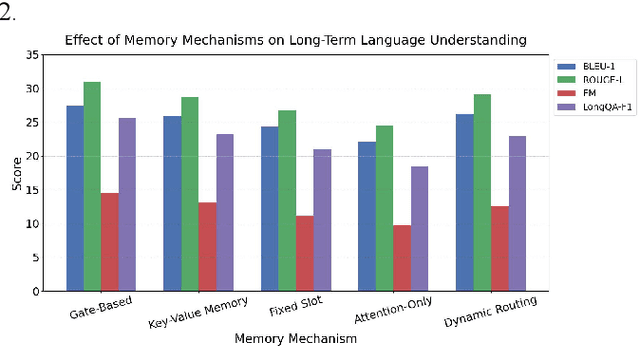
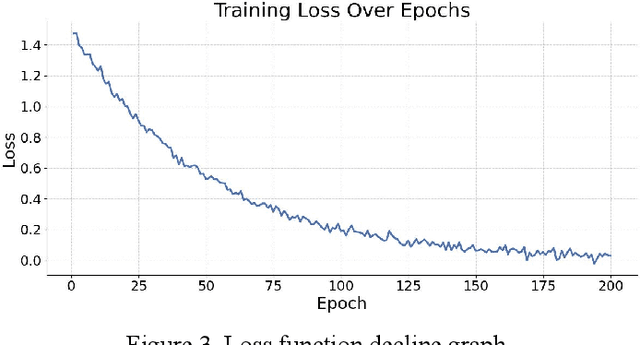
This paper addresses the limitations of large language models in understanding long-term context. It proposes a model architecture equipped with a long-term memory mechanism to improve the retention and retrieval of semantic information across paragraphs and dialogue turns. The model integrates explicit memory units, gated writing mechanisms, and attention-based reading modules. A forgetting function is introduced to enable dynamic updates of memory content, enhancing the model's ability to manage historical information. To further improve the effectiveness of memory operations, the study designs a joint training objective. This combines the main task loss with constraints on memory writing and forgetting. It guides the model to learn better memory strategies during task execution. Systematic evaluation across multiple subtasks shows that the model achieves clear advantages in text generation consistency, stability in multi-turn question answering, and accuracy in cross-context reasoning. In particular, the model demonstrates strong semantic retention and contextual coherence in long-text tasks and complex question answering scenarios. It effectively mitigates the context loss and semantic drift problems commonly faced by traditional language models when handling long-term dependencies. The experiments also include analysis of different memory structures, capacity sizes, and control strategies. These results further confirm the critical role of memory mechanisms in language understanding. They demonstrate the feasibility and effectiveness of the proposed approach in both architectural design and performance outcomes.
Divide and Conquer: Grounding LLMs as Efficient Decision-Making Agents via Offline Hierarchical Reinforcement Learning
May 26, 2025While showing sophisticated reasoning abilities, large language models (LLMs) still struggle with long-horizon decision-making tasks due to deficient exploration and long-term credit assignment, especially in sparse-reward scenarios. Inspired by the divide-and-conquer principle, we propose an innovative framework **GLIDER** (**G**rounding **L**anguage Models as Eff**I**cient **D**ecision-Making Agents via Offline Hi**E**rarchical **R**einforcement Learning) that introduces a parameter-efficient and generally applicable hierarchy to LLM policies. We develop a scheme where the low-level controller is supervised with abstract, step-by-step plans that are learned and instructed by the high-level policy. This design decomposes complicated problems into a series of coherent chain-of-thought reasoning sub-tasks, providing flexible temporal abstraction to significantly enhance exploration and learning for long-horizon tasks. Furthermore, GLIDER facilitates fast online adaptation to non-stationary environments owing to the strong transferability of its task-agnostic low-level skills. Experiments on ScienceWorld and ALFWorld benchmarks show that GLIDER achieves consistent performance gains, along with enhanced generalization capabilities.
SuperAD: A Training-free Anomaly Classification and Segmentation Method for CVPR 2025 VAND 3.0 Workshop Challenge Track 1: Adapt & Detect
May 26, 2025In this technical report, we present our solution to the CVPR 2025 Visual Anomaly and Novelty Detection (VAND) 3.0 Workshop Challenge Track 1: Adapt & Detect: Robust Anomaly Detection in Real-World Applications. In real-world industrial anomaly detection, it is crucial to accurately identify anomalies with physical complexity, such as transparent or reflective surfaces, occlusions, and low-contrast contaminations. The recently proposed MVTec AD 2 dataset significantly narrows the gap between publicly available benchmarks and anomalies found in real-world industrial environments. To address the challenges posed by this dataset--such as complex and varying lighting conditions and real anomalies with large scale differences--we propose a fully training-free anomaly detection and segmentation method based on feature extraction using the DINOv2 model named SuperAD. Our method carefully selects a small number of normal reference images and constructs a memory bank by leveraging the strong representational power of DINOv2. Anomalies are then segmented by performing nearest neighbor matching between test image features and the memory bank. Our method achieves competitive results on both test sets of the MVTec AD 2 dataset.
FullFront: Benchmarking MLLMs Across the Full Front-End Engineering Workflow
May 26, 2025Front-end engineering involves a complex workflow where engineers conceptualize designs, translate them into code, and iteratively refine the implementation. While recent benchmarks primarily focus on converting visual designs to code, we present FullFront, a benchmark designed to evaluate Multimodal Large Language Models (MLLMs) \textbf{across the full front-end development pipeline}. FullFront assesses three fundamental tasks that map directly to the front-end engineering pipeline: Webpage Design (conceptualization phase), Webpage Perception QA (comprehension of visual organization and elements), and Webpage Code Generation (implementation phase). Unlike existing benchmarks that use either scraped websites with bloated code or oversimplified LLM-generated HTML, FullFront employs a novel, two-stage process to transform real-world webpages into clean, standardized HTML while maintaining diverse visual designs and avoiding copyright issues. Extensive testing of state-of-the-art MLLMs reveals significant limitations in page perception, code generation (particularly for image handling and layout), and interaction implementation. Our results quantitatively demonstrate performance disparities across models and tasks, and highlight a substantial gap between current MLLM capabilities and human expert performance in front-end engineering. The FullFront benchmark and code are available in https://github.com/Mikivishy/FullFront.
Unveiling the Compositional Ability Gap in Vision-Language Reasoning Model
May 26, 2025While large language models (LLMs) demonstrate strong reasoning capabilities utilizing reinforcement learning (RL) with verifiable reward, whether large vision-language models (VLMs) can directly inherit such capabilities through similar post-training strategies remains underexplored. In this work, we conduct a systematic compositional probing study to evaluate whether current VLMs trained with RL or other post-training strategies can compose capabilities across modalities or tasks under out-of-distribution conditions. We design a suite of diagnostic tasks that train models on unimodal tasks or isolated reasoning skills, and evaluate them on multimodal, compositional variants requiring skill integration. Through comparisons between supervised fine-tuning (SFT) and RL-trained models, we identify three key findings: (1) RL-trained models consistently outperform SFT on compositional generalization, demonstrating better integration of learned skills; (2) although VLMs achieve strong performance on individual tasks, they struggle to generalize compositionally under cross-modal and cross-task scenario, revealing a significant gap in current training strategies; (3) enforcing models to explicitly describe visual content before reasoning (e.g., caption-before-thinking), along with rewarding progressive vision-to-text grounding, yields notable gains. It highlights two essential ingredients for improving compositionality in VLMs: visual-to-text alignment and accurate visual grounding. Our findings shed light on the current limitations of RL-based reasoning VLM training and provide actionable insights toward building models that reason compositionally across modalities and tasks.
SATORI-R1: Incentivizing Multimodal Reasoning with Spatial Grounding and Verifiable Rewards
May 25, 2025DeepSeek-R1 has demonstrated powerful reasoning capabilities in the text domain through stable reinforcement learning (RL). Recently, in the multimodal domain, works have begun to directly apply RL to generate R1-like free-form reasoning for Visual Question Answering (VQA) tasks. However, multimodal tasks share an intrinsically different nature from textual tasks, which heavily rely on the understanding of the input image to solve the problem. Therefore, such free-form reasoning faces two critical limitations in the VQA task: (1) Extended reasoning chains diffuse visual focus away from task-critical regions, degrading answer accuracy. (2) Unverifiable intermediate steps amplify policy-gradient variance and computational costs overhead. To address these issues, in this paper, we introduce SATORI ($\textbf{S}patially$ $\textbf{A}nchored$ $\textbf{T}ask$ $\textbf{O}ptimization$ with $\textbf{R}e\textbf{I}nforcement$ Learning), which decomposes VQA into three verifiable stages, including global image captioning, region localization, and answer prediction, each supplying explicit reward signals. Furthermore, we also introduce VQA-Verify, a 12k dataset annotated with answer-aligned captions and bounding-boxes to facilitate training. Experiments demonstrate consistent performance improvements across seven VQA benchmarks, achieving up to $15.7\%$ improvement in accuracy in accuracy compared to the R1-like baseline. Our analysis of the attention map confirms enhanced focus on critical regions, which brings improvements in accuracy. Our code is available at https://github.com/justairr/SATORI-R1.
Step-level Reward for Free in RL-based T2I Diffusion Model Fine-tuning
May 25, 2025Recent advances in text-to-image (T2I) diffusion model fine-tuning leverage reinforcement learning (RL) to align generated images with learnable reward functions. The existing approaches reformulate denoising as a Markov decision process for RL-driven optimization. However, they suffer from reward sparsity, receiving only a single delayed reward per generated trajectory. This flaw hinders precise step-level attribution of denoising actions, undermines training efficiency. To address this, we propose a simple yet effective credit assignment framework that dynamically distributes dense rewards across denoising steps. Specifically, we track changes in cosine similarity between intermediate and final images to quantify each step's contribution on progressively reducing the distance to the final image. Our approach avoids additional auxiliary neural networks for step-level preference modeling and instead uses reward shaping to highlight denoising phases that have a greater impact on image quality. Our method achieves 1.25 to 2 times higher sample efficiency and better generalization across four human preference reward functions, without compromising the original optimal policy.