 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Memory Mechanisms for Stable Context Representation in Large Language Models
Paper and Code
May 28, 2025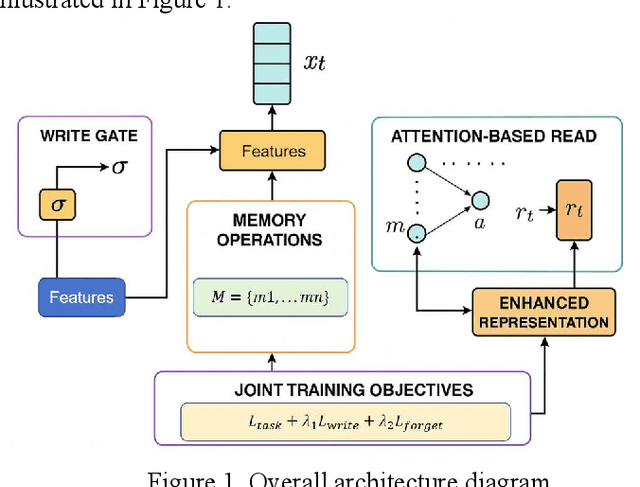
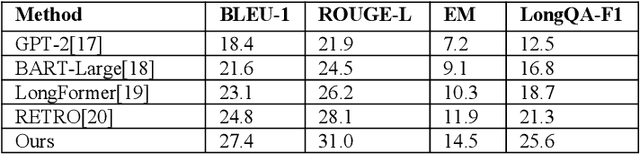
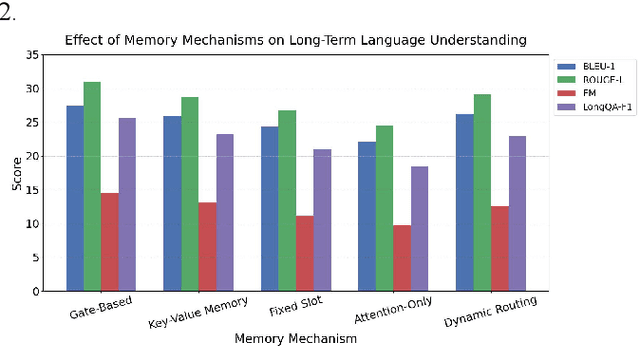
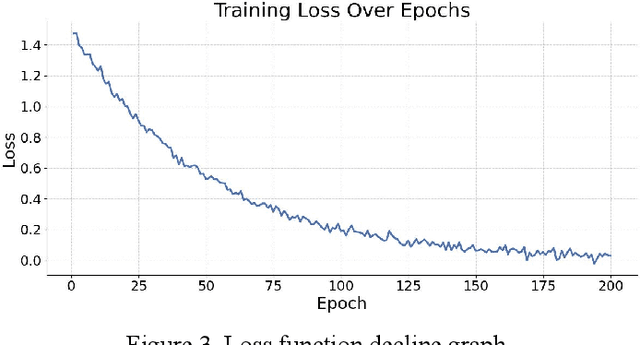
This paper addresses the limitations of large language models in understanding long-term context. It proposes a model architecture equipped with a long-term memory mechanism to improve the retention and retrieval of semantic information across paragraphs and dialogue turns. The model integrates explicit memory units, gated writing mechanisms, and attention-based reading modules. A forgetting function is introduced to enable dynamic updates of memory content, enhancing the model's ability to manage historical information. To further improve the effectiveness of memory operations, the study designs a joint training objective. This combines the main task loss with constraints on memory writing and forgetting. It guides the model to learn better memory strategies during task execution. Systematic evaluation across multiple subtasks shows that the model achieves clear advantages in text generation consistency, stability in multi-turn question answering, and accuracy in cross-context reasoning. In particular, the model demonstrates strong semantic retention and contextual coherence in long-text tasks and complex question answering scenarios. It effectively mitigates the context loss and semantic drift problems commonly faced by traditional language models when handling long-term dependencies. The experiments also include analysis of different memory structures, capacity sizes, and control strategies. These results further confirm the critical role of memory mechanisms in language understanding. They demonstrate the feasibility and effectiveness of the proposed approach in both architectural design and performance outcomes.