 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Plug-in for Improving Eviction-Based KV Cache Compression
May 22, 2026KV cache growth is a major bottleneck for long-context inference in large language models. Existing methods are often dominated by binary eviction or representation approximation, which may underutilize tokens that are not critical for exact retention but are still reconstructable. We present VECTOR, a plug-and-play augmentation for eviction-based pipelines that introduces three-way token routing: retention, approximation, and eviction. VECTOR combines an importance signal from the base scorer with a reconstructability signal from an offline-calibrated regression-based value estimation. By leveraging reconstructability, VECTOR recovers useful value information that would otherwise be irreversibly lost under binary eviction, while preserving key vectors for attention routing stability. Experimental results show that VECTOR improves quality-memory trade-offs under medium-to-high compression, with especially clear gains in stricter budget regimes.
Ada-MK: Adaptive MegaKernel Optimization via Automated DAG-based Search for LLM Inference
May 12, 2026When large language models (LLMs) serve real-time inference in commercial online advertising systems, end-to-end latency must be strictly bounded to the millisecond range. Yet every token generated during the decode phase triggers thousands of kernel launches, and kernel launch overhead alone can account for 14.6% of end-to-end inference time. MegaKernel eliminates launch overhead and inter-operator HBM round-trips by fusing multiple operators into a single persistent kernel. However, existing MegaKernel implementations face a fundamental tension between portability and efficiency on resource-constrained GPUs such as NVIDIA Ada: hand-tuned solutions are tightly coupled to specific architectures and lack portability, while auto-compiled approaches introduce runtime dynamic scheduling whose branch penalties are unacceptable in latency-critical settings. We observe that under a fixed deployment configuration, the optimal execution path of a MegaKernel is uniquely determined, and runtime dynamic decision-making can be entirely hoisted to compile time. Building on this insight, we propose Ada-MK: (1) a three-dimensional shared-memory constraint model combined with K-dimension splitting that reduces peak shared memory usage by 50%; (2) MLIR-based fine-grained DAG offline search that solidifies the optimal execution path, completely eliminating runtime branching; and (3) a heterogeneous hybrid inference engine that embeds MegaKernel as a plugin into TensorRT-LLM, combining high-throughput Prefill with low-latency Decode. On an NVIDIA L20, Ada-MK improves single-batch throughput by up to 23.6% over vanilla TensorRT-LLM and 50.2% over vLLM, achieving positive gains across all tested scenarios--the first industrial deployment of MegaKernel in a commercial online advertising system.
Efficient LLM-based Advertising via Model Compression and Parallel Verification
May 12, 2026Large language models (LLMs) have shown remarkable potential in advertising scenarios such as ad creative generation and targeted advertising. However, deploying LLMs in real-time advertising systems poses significant challenges due to their high inference latency and computational cost. In this paper, we propose an Efficient Generative Targeting framework that integrates adaptive group quantization, layer-adaptive hierarchical sparsification, and prefix-tree parallel verification to accelerate LLM inference while preserving generation quality. Extensive experiments on two real-world advertising scenarios demonstrate that our framework achieves significant speedup with acceptable quality degradation, making it operationally viable for practical deployments.
Crafting Reversible SFT Behaviors in Large Language Models
May 07, 2026Supervised fine-tuning (SFT) induces new behaviors in large language models, yet imposes no structural constraint on how these behaviors are distributed within the model. Existing behavior interpretation methods, such as circuit attribution approaches, identify sparse subnetworks correlated with SFT-induced behaviors post-hoc. However, such correlations do not imply *causal necessity*, limiting the ability to selectively control SFT-induced behaviors at inference time. We pursue an alternative by asking: can an SFT-induced behavior be deliberately compressed into a sparse, mechanistically necessary subnetwork, termed a *carrier*, while remaining controllable at inference time without weight modification? We propose (a) **Loss-Constrained Dual Descent (LCDD)**, which constructs such carriers by jointly optimizing routing masks and model weights under an explicit utility budget, and (b) **SFT-Eraser**, a soft prompt optimized via activation matching on extracted carrier channels, to reverse the SFT-induced behavior. Across safety, fixed-response, and style behaviors on multiple model families, LCDD yields sparse carriers that preserve target behaviors while enabling strong reversion when triggered by SFT-Eraser. Ablations further establish that the sparse structure is the key precondition for reversal: the same trigger optimization fails on standard SFT models, confirming that structure rather than trigger design is the operative factor. These results provide direct evidence that the learned carriers are causally necessary for the behaviors, pointing to a new direction for systematically localizing and selectively suppressing SFT-induced behaviors in deployed models.
How Do Latent Reasoning Methods Perform Under Weak and Strong Supervision?
Feb 25, 2026Latent reasoning has been recently proposed as a reasoning paradigm and performs multi-step reasoning through generating steps in the latent space instead of the textual space. This paradigm enables reasoning beyond discrete language tokens by performing multi-step computation in continuous latent spaces. Although there have been numerous studies focusing on improving the performance of latent reasoning, its internal mechanisms remain not fully investigated. In this work, we conduct a comprehensive analysis of latent reasoning methods to better understand the role and behavior of latent representation in the process. We identify two key issues across latent reasoning methods with different levels of supervision. First, we observe pervasive shortcut behavior, where they achieve high accuracy without relying on latent reasoning. Second, we examine the hypothesis that latent reasoning supports BFS-like exploration in latent space, and find that while latent representations can encode multiple possibilities, the reasoning process does not faithfully implement structured search, but instead exhibits implicit pruning and compression. Finally, our findings reveal a trade-off associated with supervision strength: stronger supervision mitigates shortcut behavior but restricts the ability of latent representations to maintain diverse hypotheses, whereas weaker supervision allows richer latent representations at the cost of increased shortcut behavior.
$f$-GRPO and Beyond: Divergence-Based Reinforcement Learning Algorithms for General LLM Alignment
Feb 05, 2026Recent research shows that Preference Alignment (PA) objectives act as divergence estimators between aligned (chosen) and unaligned (rejected) response distributions. In this work, we extend this divergence-based perspective to general alignment settings, such as reinforcement learning with verifiable rewards (RLVR), where only environmental rewards are available. Within this unified framework, we propose $f$-Group Relative Policy Optimization ($f$-GRPO), a class of on-policy reinforcement learning, and $f$-Hybrid Alignment Loss ($f$-HAL), a hybrid on/off policy objectives, for general LLM alignment based on variational representation of $f$-divergences. We provide theoretical guarantees that these classes of objectives improve the average reward after alignment. Empirically, we validate our framework on both RLVR (Math Reasoning) and PA tasks (Safety Alignment), demonstrating superior performance and flexibility compared to current methods.
Impact of Positional Encoding: Clean and Adversarial Rademacher Complexity for Transformers under In-Context Regression
Dec 10, 2025Positional encoding (PE) is a core architectural component of Transformers, yet its impact on the Transformer's generalization and robustness remains unclear. In this work, we provide the first generalization analysis for a single-layer Transformer under in-context regression that explicitly accounts for a completely trainable PE module. Our result shows that PE systematically enlarges the generalization gap. Extending to the adversarial setting, we derive the adversarial Rademacher generalization bound. We find that the gap between models with and without PE is magnified under attack, demonstrating that PE amplifies the vulnerability of models. Our bounds are empirically validated by a simulation study. Together, this work establishes a new framework for understanding the clean and adversarial generalization in ICL with PE.
TRAJECT-Bench:A Trajectory-Aware Benchmark for Evaluating Agentic Tool Use
Oct 06, 2025



Large language model (LLM)-based agents increasingly rely on tool use to complete real-world tasks. While existing works evaluate the LLMs' tool use capability, they largely focus on the final answers yet overlook the detailed tool usage trajectory, i.e., whether tools are selected, parameterized, and ordered correctly. We introduce TRAJECT-Bench, a trajectory-aware benchmark to comprehensively evaluate LLMs' tool use capability through diverse tasks with fine-grained evaluation metrics. TRAJECT-Bench pairs high-fidelity, executable tools across practical domains with tasks grounded in production-style APIs, and synthesizes trajectories that vary in breadth (parallel calls) and depth (interdependent chains). Besides final accuracy, TRAJECT-Bench also reports trajectory-level diagnostics, including tool selection and argument correctness, and dependency/order satisfaction. Analyses reveal failure modes such as similar tool confusion and parameter-blind selection, and scaling behavior with tool diversity and trajectory length where the bottleneck of transiting from short to mid-length trajectories is revealed, offering actionable guidance for LLMs' tool use.
SoK: Machine Unlearning for Large Language Models
Jun 10, 2025

Large language model (LLM) unlearning has become a critical topic in machine learning, aiming to eliminate the influence of specific training data or knowledge without retraining the model from scratch. A variety of techniques have been proposed, including Gradient Ascent, model editing, and re-steering hidden representations. While existing surveys often organize these methods by their technical characteristics, such classifications tend to overlook a more fundamental dimension: the underlying intention of unlearning--whether it seeks to truly remove internal knowledge or merely suppress its behavioral effects. In this SoK paper, we propose a new taxonomy based on this intention-oriented perspective. Building on this taxonomy, we make three key contributions. First, we revisit recent findings suggesting that many removal methods may functionally behave like suppression, and explore whether true removal is necessary or achievable. Second, we survey existing evaluation strategies, identify limitations in current metrics and benchmarks, and suggest directions for developing more reliable and intention-aligned evaluations. Third, we highlight practical challenges--such as scalability and support for sequential unlearning--that currently hinder the broader deployment of unlearning methods. In summary, this work offers a comprehensive framework for understanding and advancing unlearning in generative AI, aiming to support future research and guide policy decisions around data removal and privacy.
Structured Memory Mechanisms for Stable Context Representation in Large Language Models
May 28, 2025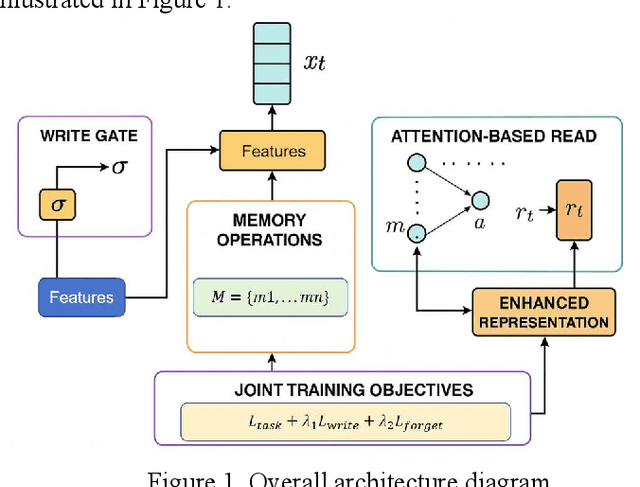
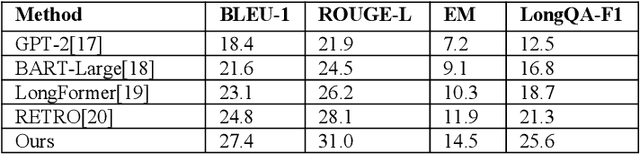
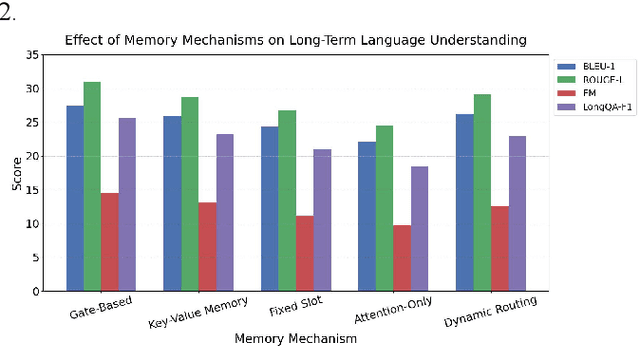
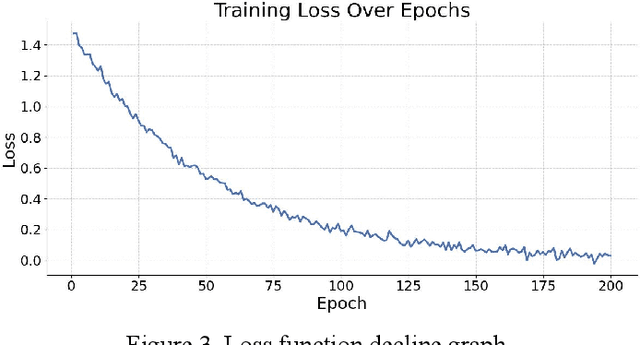
This paper addresses the limitations of large language models in understanding long-term context. It proposes a model architecture equipped with a long-term memory mechanism to improve the retention and retrieval of semantic information across paragraphs and dialogue turns. The model integrates explicit memory units, gated writing mechanisms, and attention-based reading modules. A forgetting function is introduced to enable dynamic updates of memory content, enhancing the model's ability to manage historical information. To further improve the effectiveness of memory operations, the study designs a joint training objective. This combines the main task loss with constraints on memory writing and forgetting. It guides the model to learn better memory strategies during task execution. Systematic evaluation across multiple subtasks shows that the model achieves clear advantages in text generation consistency, stability in multi-turn question answering, and accuracy in cross-context reasoning. In particular, the model demonstrates strong semantic retention and contextual coherence in long-text tasks and complex question answering scenarios. It effectively mitigates the context loss and semantic drift problems commonly faced by traditional language models when handling long-term dependencies. The experiments also include analysis of different memory structures, capacity sizes, and control strategies. These results further confirm the critical role of memory mechanisms in language understanding. They demonstrate the feasibility and effectiveness of the proposed approach in both architectural design and performance outcomes.