 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning universal approximations for partial differential equations with Physics-Informed Broad Learning System
Jun 18, 2026Partial differential equations (PDEs) play a central role in modeling complex physical, biological, and engineering systems. While traditional numerical solvers are robust, they often incur prohibitive computational costs due to mesh dependencies, whereas recent Physics-Informed Neural Networks (PINNs) offer a mesh-free alternative but frequently suffer from slow convergence and optimization instability. To bridge this gap, this article proposes the Physics-Informed Broad Learning System (PIBLS), a novel backpropagation-free framework that reformulates PDE solving as a direct least-squares optimization. We improved an algorithm within this framework to handle nonlinear PDEs efficiently and provide a rigorous mathematical proof establishing the universal approximation property of PIBLS for these equations. Experiments on linear and nonlinear PDEs demonstrate that PIBLS is one to three orders of magnitude faster than conventional PINNs while achieving significantly higher solution accuracy. This framework provides a computationally efficient paradigm for scientific machine learning, offering a practical, high-speed alternative for real-time simulation and design optimization tasks.
P$^2$-DPO: Grounding Hallucination in Perceptual Processing via Calibration Direct Preference Optimization
Jun 03, 2026Hallucination has recently garnered significant research attention in Large Vision-Language Models (LVLMs). Direct Preference Optimization (DPO) aims to learn directly from the corrected preferences provided by humans, thereby addressing the hallucination issue. Despite its success, this paradigm has yet to specifically target the perceptual bottleneck in attended regions or address insufficient Visual Robustness against image degradation. Furthermore, existing preference pairs are often vision-agnostic and their inherently off-policy nature limits their effectiveness in guiding model learning. To address these challenges, we propose Perceptual Processing Direct Preference Optimization (P$^2$-DPO), a novel training paradigm in which the model generates and learns from its own preference pairs, thereby directly addressing the identified visual bottlenecks while inherently avoiding the issues of vision-agnostic and off-policy data. It introduces: (1) an on-policy preference pairs construction method targeting Focus-and-Enhance perception and Visual Robustness, and (2) a well-designed Calibration Loss to precisely align visual signals with the causal generation of text. Experimental results demonstrate that with a comparable amount of training data and cost, P$^2$-DPO outperforms strong baselines that rely on costly human feedback on benchmarks. Furthermore, evaluations on Attention Region Fidelity (ARF) and image degradation scenarios validate the effectiveness of P$^2$-DPO in addressing perceptual bottleneck in attended regions and improving Visual Robustness against degraded inputs.
A Cosine Network for Image Super-Resolution
Jan 23, 2026Deep convolutional neural networks can use hierarchical information to progressively extract structural information to recover high-quality images. However, preserving the effectiveness of the obtained structural information is important in image super-resolution. In this paper, we propose a cosine network for image super-resolution (CSRNet) by improving a network architecture and optimizing the training strategy. To extract complementary homologous structural information, odd and even heterogeneous blocks are designed to enlarge the architectural differences and improve the performance of image super-resolution. Combining linear and non-linear structural information can overcome the drawback of homologous information and enhance the robustness of the obtained structural information in image super-resolution. Taking into account the local minimum of gradient descent, a cosine annealing mechanism is used to optimize the training procedure by performing warm restarts and adjusting the learning rate. Experimental results illustrate that the proposed CSRNet is competitive with state-of-the-art methods in image super-resolution.
Consistency-Regularized GAN for Few-Shot SAR Target Recognition
Jan 22, 2026Few-shot recognition in synthetic aperture radar (SAR) imagery remains a critical bottleneck for real-world applications due to extreme data scarcity. A promising strategy involves synthesizing a large dataset with a generative adversarial network (GAN), pre-training a model via self-supervised learning (SSL), and then fine-tuning on the few labeled samples. However, this approach faces a fundamental paradox: conventional GANs themselves require abundant data for stable training, contradicting the premise of few-shot learning. To resolve this, we propose the consistency-regularized generative adversarial network (Cr-GAN), a novel framework designed to synthesize diverse, high-fidelity samples even when trained under these severe data limitations. Cr-GAN introduces a dual-branch discriminator that decouples adversarial training from representation learning. This architecture enables a channel-wise feature interpolation strategy to create novel latent features, complemented by a dual-domain cycle consistency mechanism that ensures semantic integrity. Our Cr-GAN framework is adaptable to various GAN architectures, and its synthesized data effectively boosts multiple SSL algorithms. Extensive experiments on the MSTAR and SRSDD datasets validate our approach, with Cr-GAN achieving a highly competitive accuracy of 71.21% and 51.64%, respectively, in the 8-shot setting, significantly outperforming leading baselines, while requiring only ~5 of the parameters of state-of-the-art diffusion models. Code is available at: https://github.com/yikuizhai/Cr-GAN.
Test-time Adaptive Hierarchical Co-enhanced Denoising Network for Reliable Multimodal Classification
Jan 12, 2026Reliable learning on low-quality multimodal data is a widely concerning issue, especially in safety-critical applications. However, multimodal noise poses a major challenge in this domain and leads existing methods to suffer from two key limitations. First, they struggle to reliably remove heterogeneous data noise, hindering robust multimodal representation learning. Second, they exhibit limited adaptability and generalization when encountering previously unseen noise. To address these issues, we propose Test-time Adaptive Hierarchical Co-enhanced Denoising Network (TAHCD). On one hand, TAHCD introduces the Adaptive Stable Subspace Alignment and Sample-Adaptive Confidence Alignment to reliably remove heterogeneous noise. They account for noise at both global and instance levels and enable jointly removal of modality-specific and cross-modality noise, achieving robust learning. On the other hand, TAHCD introduces test-time cooperative enhancement, which adaptively updates the model in response to input noise in a label-free manner, improving adaptability and generalization. This is achieved by collaboratively enhancing the joint removal process of modality-specific and cross-modality noise across global and instance levels according to sample noise. Experiments on multiple benchmarks demonstrate that the proposed method achieves superior classification performance, robustness, and generalization compared with state-of-the-art reliable multimodal learning approaches.
Memo2496: Expert-Annotated Dataset and Dual-View Adaptive Framework for Music Emotion Recognition
Dec 17, 2025
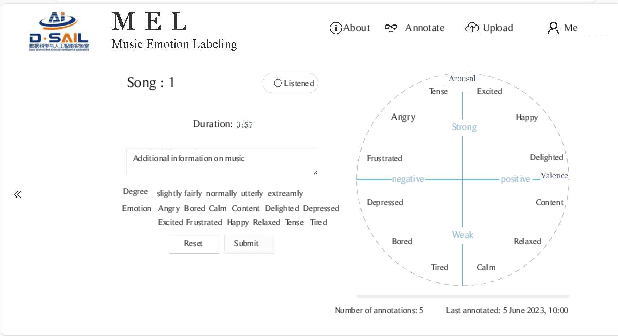
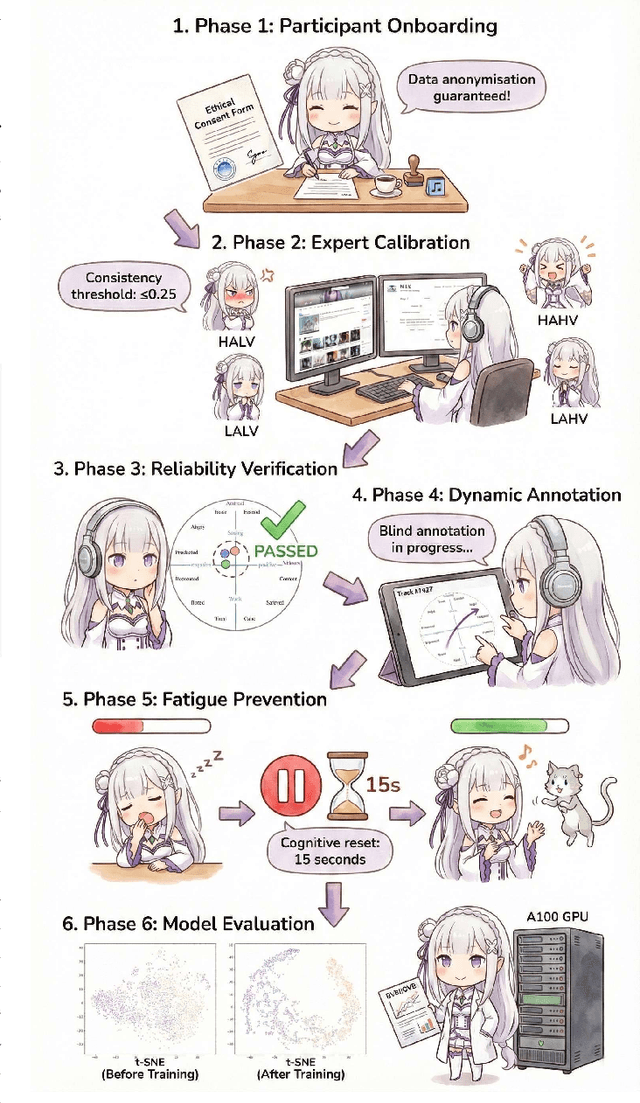
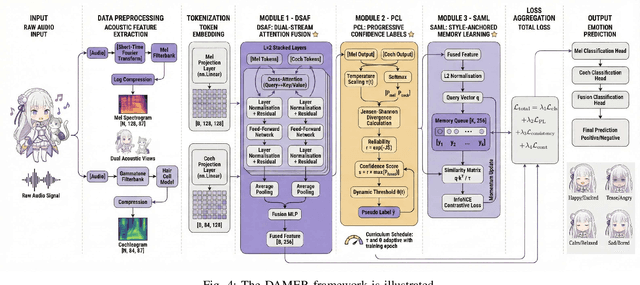
Music Emotion Recogniser (MER) research faces challenges due to limited high-quality annotated datasets and difficulties in addressing cross-track feature drift. This work presents two primary contributions to address these issues. Memo2496, a large-scale dataset, offers 2496 instrumental music tracks with continuous valence arousal labels, annotated by 30 certified music specialists. Annotation quality is ensured through calibration with extreme emotion exemplars and a consistency threshold of 0.25, measured by Euclidean distance in the valence arousal space. Furthermore, the Dual-view Adaptive Music Emotion Recogniser (DAMER) is introduced. DAMER integrates three synergistic modules: Dual Stream Attention Fusion (DSAF) facilitates token-level bidirectional interaction between Mel spectrograms and cochleagrams via cross attention mechanisms; Progressive Confidence Labelling (PCL) generates reliable pseudo labels employing curriculum-based temperature scheduling and consistency quantification using Jensen Shannon divergence; and Style Anchored Memory Learning (SAML) maintains a contrastive memory queue to mitigate cross-track feature drift. Extensive experiments on the Memo2496, 1000songs, and PMEmo datasets demonstrate DAMER's state-of-the-art performance, improving arousal dimension accuracy by 3.43%, 2.25%, and 0.17%, respectively. Ablation studies and visualisation analyses validate each module's contribution. Both the dataset and source code are publicly available.
PathFinder: Advancing Path Loss Prediction for Single-to-Multi-Transmitter Scenario
Dec 16, 2025Radio path loss prediction (RPP) is critical for optimizing 5G networks and enabling IoT, smart city, and similar applications. However, current deep learning-based RPP methods lack proactive environmental modeling, struggle with realistic multi-transmitter scenarios, and generalize poorly under distribution shifts, particularly when training/testing environments differ in building density or transmitter configurations. This paper identifies three key issues: (1) passive environmental modeling that overlooks transmitters and key environmental features; (2) overemphasis on single-transmitter scenarios despite real-world multi-transmitter prevalence; (3) excessive focus on in-distribution performance while neglecting distribution shift challenges. To address these, we propose PathFinder, a novel architecture that actively models buildings and transmitters via disentangled feature encoding and integrates Mask-Guided Low-rank Attention to independently focus on receiver and building regions. We also introduce a Transmitter-Oriented Mixup strategy for robust training and a new benchmark, single-to-multi-transmitter RPP (S2MT-RPP), tailored to evaluate extrapolation performance (multi-transmitter testing after single-transmitter training). Experimental results show PathFinder outperforms state-of-the-art methods significantly, especially in challenging multi-transmitter scenarios. Our code and project site are available at: https://emorzz1g.github.io/PathFinder/.
Multimodal Feature Fusion Network with Text Difference Enhancement for Remote Sensing Change Detection
Sep 04, 2025Although deep learning has advanced remote sensing change detection (RSCD), most methods rely solely on image modality, limiting feature representation, change pattern modeling, and generalization especially under illumination and noise disturbances. To address this, we propose MMChange, a multimodal RSCD method that combines image and text modalities to enhance accuracy and robustness. An Image Feature Refinement (IFR) module is introduced to highlight key regions and suppress environmental noise. To overcome the semantic limitations of image features, we employ a vision language model (VLM) to generate semantic descriptions of bitemporal images. A Textual Difference Enhancement (TDE) module then captures fine grained semantic shifts, guiding the model toward meaningful changes. To bridge the heterogeneity between modalities, we design an Image Text Feature Fusion (ITFF) module that enables deep cross modal integration. Extensive experiments on LEVIRCD, WHUCD, and SYSUCD demonstrate that MMChange consistently surpasses state of the art methods across multiple metrics, validating its effectiveness for multimodal RSCD. Code is available at: https://github.com/yikuizhai/MMChange.
AIM: Adaptive Intra-Network Modulation for Balanced Multimodal Learning
Aug 27, 2025Multimodal learning has significantly enhanced machine learning performance but still faces numerous challenges and limitations. Imbalanced multimodal learning is one of the problems extensively studied in recent works and is typically mitigated by modulating the learning of each modality. However, we find that these methods typically hinder the dominant modality's learning to promote weaker modalities, which affects overall multimodal performance. We analyze the cause of this issue and highlight a commonly overlooked problem: optimization bias within networks. To address this, we propose Adaptive Intra-Network Modulation (AIM) to improve balanced modality learning. AIM accounts for differences in optimization state across parameters and depths within the network during modulation, achieving balanced multimodal learning without hindering either dominant or weak modalities for the first time. Specifically, AIM decouples the dominant modality's under-optimized parameters into Auxiliary Blocks and encourages reliance on these performance-degraded blocks for joint training with weaker modalities. This approach effectively prevents suppression of weaker modalities while enabling targeted optimization of under-optimized parameters to improve the dominant modality. Additionally, AIM assesses modality imbalance level across network depths and adaptively adjusts modulation strength at each depth. Experimental results demonstrate that AIM outperforms state-of-the-art imbalanced modality learning methods across multiple benchmarks and exhibits strong generalizability across different backbones, fusion strategies, and optimizers.
Wavelet-Guided Dual-Frequency Encoding for Remote Sensing Change Detection
Aug 07, 2025Change detection in remote sensing imagery plays a vital role in various engineering applications, such as natural disaster monitoring, urban expansion tracking, and infrastructure management. Despite the remarkable progress of deep learning in recent years, most existing methods still rely on spatial-domain modeling, where the limited diversity of feature representations hinders the detection of subtle change regions. We observe that frequency-domain feature modeling particularly in the wavelet domain an amplify fine-grained differences in frequency components, enhancing the perception of edge changes that are challenging to capture in the spatial domain. Thus, we propose a method called Wavelet-Guided Dual-Frequency Encoding (WGDF). Specifically, we first apply Discrete Wavelet Transform (DWT) to decompose the input images into high-frequency and low-frequency components, which are used to model local details and global structures, respectively. In the high-frequency branch, we design a Dual-Frequency Feature Enhancement (DFFE) module to strengthen edge detail representation and introduce a Frequency-Domain Interactive Difference (FDID) module to enhance the modeling of fine-grained changes. In the low-frequency branch, we exploit Transformers to capture global semantic relationships and employ a Progressive Contextual Difference Module (PCDM) to progressively refine change regions, enabling precise structural semantic characterization. Finally, the high- and low-frequency features are synergistically fused to unify local sensitivity with global discriminability. Extensive experiments on multiple remote sensing datasets demonstrate that WGDF significantly alleviates edge ambiguity and achieves superior detection accuracy and robustness compared to state-of-the-art methods. The code will be available at https://github.com/boshizhang123/WGDF.