 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBootstrapping Imitation Learning for Long-horizon Manipulation via Hierarchical Data Collection Space
May 23, 2025Imitation learning (IL) with human demonstrations is a promising method for robotic manipulation tasks. While minimal demonstrations enable robotic action execution, achieving high success rates and generalization requires high cost, e.g., continuously adding data or incrementally conducting human-in-loop processes with complex hardware/software systems. In this paper, we rethink the state/action space of the data collection pipeline as well as the underlying factors responsible for the prediction of non-robust actions. To this end, we introduce a Hierarchical Data Collection Space (HD-Space) for robotic imitation learning, a simple data collection scheme, endowing the model to train with proactive and high-quality data. Specifically, We segment the fine manipulation task into multiple key atomic tasks from a high-level perspective and design atomic state/action spaces for human demonstrations, aiming to generate robust IL data. We conduct empirical evaluations across two simulated and five real-world long-horizon manipulation tasks and demonstrate that IL policy training with HD-Space-based data can achieve significantly enhanced policy performance. HD-Space allows the use of a small amount of demonstration data to train a more powerful policy, particularly for long-horizon manipulation tasks. We aim for HD-Space to offer insights into optimizing data quality and guiding data scaling. project page: https://hd-space-robotics.github.io.
VIRT: Vision Instructed Transformer for Robotic Manipulation
Oct 09, 2024



Robotic manipulation, owing to its multi-modal nature, often faces significant training ambiguity, necessitating explicit instructions to clearly delineate the manipulation details in tasks. In this work, we highlight that vision instruction is naturally more comprehensible to recent robotic policies than the commonly adopted text instruction, as these policies are born with some vision understanding ability like human infants. Building on this premise and drawing inspiration from cognitive science, we introduce the robotic imagery paradigm, which realizes large-scale robotic data pre-training without text annotations. Additionally, we propose the robotic gaze strategy that emulates the human eye gaze mechanism, thereby guiding subsequent actions and focusing the attention of the policy on the manipulated object. Leveraging these innovations, we develop VIRT, a fully Transformer-based policy. We design comprehensive tasks using both a physical robot and simulated environments to assess the efficacy of VIRT. The results indicate that VIRT can complete very competitive tasks like ``opening the lid of a tightly sealed bottle'', and the proposed techniques boost the success rates of the baseline policy on diverse challenging tasks from nearly 0% to more than 65%.
Personalized Trajectory Prediction via Distribution Discrimination
Jul 29, 2021
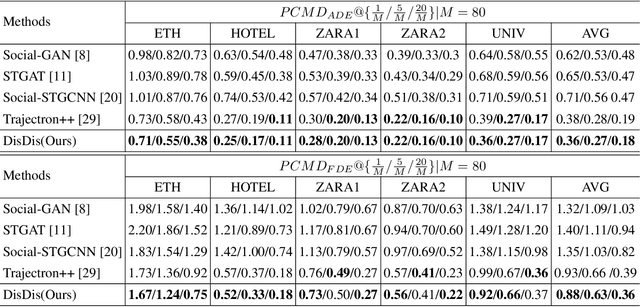
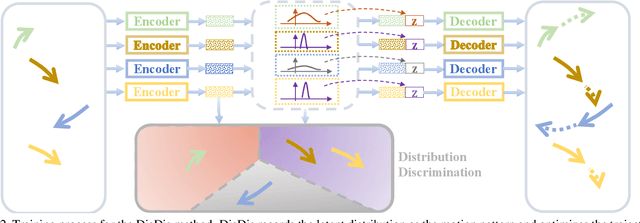
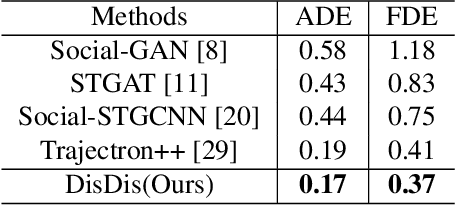
Trajectory prediction is confronted with the dilemma to capture the multi-modal nature of future dynamics with both diversity and accuracy. In this paper, we present a distribution discrimination (DisDis) method to predict personalized motion patterns by distinguishing the potential distributions. Motivated by that the motion pattern of each person is personalized due to his/her habit, our DisDis learns the latent distribution to represent different motion patterns and optimize it by the contrastive discrimination. This distribution discrimination encourages latent distributions to be more discriminative. Our method can be integrated with existing multi-modal stochastic predictive models as a plug-and-play module to learn the more discriminative latent distribution. To evaluate the latent distribution, we further propose a new metric, probability cumulative minimum distance (PCMD) curve, which cumulatively calculates the minimum distance on the sorted probabilities. Experimental results on the ETH and UCY datasets show the effectiveness of our method.