 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEJO: MLLM-Engaged Surgical Triplet Recognition via Inter- and Intra-Task Joint Optimization
Sep 16, 2025Surgical triplet recognition, which involves identifying instrument, verb, target, and their combinations, is a complex surgical scene understanding challenge plagued by long-tailed data distribution. The mainstream multi-task learning paradigm benefiting from cross-task collaborative promotion has shown promising performance in identifying triples, but two key challenges remain: 1) inter-task optimization conflicts caused by entangling task-generic and task-specific representations; 2) intra-task optimization conflicts due to class-imbalanced training data. To overcome these difficulties, we propose the MLLM-Engaged Joint Optimization (MEJO) framework that empowers both inter- and intra-task optimization for surgical triplet recognition. For inter-task optimization, we introduce the Shared-Specific-Disentangled (S$^2$D) learning scheme that decomposes representations into task-shared and task-specific components. To enhance task-shared representations, we construct a Multimodal Large Language Model (MLLM) powered probabilistic prompt pool to dynamically augment visual features with expert-level semantic cues. Additionally, comprehensive task-specific cues are modeled via distinct task prompts covering the temporal-spatial dimensions, effectively mitigating inter-task ambiguities. To tackle intra-task optimization conflicts, we develop a Coordinated Gradient Learning (CGL) strategy, which dissects and rebalances the positive-negative gradients originating from head and tail classes for more coordinated learning behaviors. Extensive experiments on the CholecT45 and CholecT50 datasets demonstrate the superiority of our proposed framework, validating its effectiveness in handling optimization conflicts.
Perceiving and Acting in First-Person: A Dataset and Benchmark for Egocentric Human-Object-Human Interactions
Aug 06, 2025



Learning action models from real-world human-centric interaction datasets is important towards building general-purpose intelligent assistants with efficiency. However, most existing datasets only offer specialist interaction category and ignore that AI assistants perceive and act based on first-person acquisition. We urge that both the generalist interaction knowledge and egocentric modality are indispensable. In this paper, we embed the manual-assisted task into a vision-language-action framework, where the assistant provides services to the instructor following egocentric vision and commands. With our hybrid RGB-MoCap system, pairs of assistants and instructors engage with multiple objects and the scene following GPT-generated scripts. Under this setting, we accomplish InterVLA, the first large-scale human-object-human interaction dataset with 11.4 hours and 1.2M frames of multimodal data, spanning 2 egocentric and 5 exocentric videos, accurate human/object motions and verbal commands. Furthermore, we establish novel benchmarks on egocentric human motion estimation, interaction synthesis, and interaction prediction with comprehensive analysis. We believe that our InterVLA testbed and the benchmarks will foster future works on building AI agents in the physical world.
Scaling Offline RL via Efficient and Expressive Shortcut Models
May 28, 2025



Diffusion and flow models have emerged as powerful generative approaches capable of modeling diverse and multimodal behavior. However, applying these models to offline reinforcement learning (RL) remains challenging due to the iterative nature of their noise sampling processes, making policy optimization difficult. In this paper, we introduce Scalable Offline Reinforcement Learning (SORL), a new offline RL algorithm that leverages shortcut models - a novel class of generative models - to scale both training and inference. SORL's policy can capture complex data distributions and can be trained simply and efficiently in a one-stage training procedure. At test time, SORL introduces both sequential and parallel inference scaling by using the learned Q-function as a verifier. We demonstrate that SORL achieves strong performance across a range of offline RL tasks and exhibits positive scaling behavior with increased test-time compute. We release the code at nico-espinosadice.github.io/projects/sorl.
Convergence Of Consistency Model With Multistep Sampling Under General Data Assumptions
May 06, 2025Diffusion models accomplish remarkable success in data generation tasks across various domains. However, the iterative sampling process is computationally expensive. Consistency models are proposed to learn consistency functions to map from noise to data directly, which allows one-step fast data generation and multistep sampling to improve sample quality. In this paper, we study the convergence of consistency models when the self-consistency property holds approximately under the training distribution. Our analysis requires only mild data assumption and applies to a family of forward processes. When the target data distribution has bounded support or has tails that decay sufficiently fast, we show that the samples generated by the consistency model are close to the target distribution in Wasserstein distance; when the target distribution satisfies some smoothness assumption, we show that with an additional perturbation step for smoothing, the generated samples are close to the target distribution in total variation distance. We provide two case studies with commonly chosen forward processes to demonstrate the benefit of multistep sampling.
High-Quality 3D Head Reconstruction from Any Single Portrait Image
Mar 11, 2025



In this work, we introduce a novel high-fidelity 3D head reconstruction method from a single portrait image, regardless of perspective, expression, or accessories. Despite significant efforts in adapting 2D generative models for novel view synthesis and 3D optimization, most methods struggle to produce high-quality 3D portraits. The lack of crucial information, such as identity, expression, hair, and accessories, limits these approaches in generating realistic 3D head models. To address these challenges, we construct a new high-quality dataset containing 227 sequences of digital human portraits captured from 96 different perspectives, totalling 21,792 frames, featuring diverse expressions and accessories. To further improve performance, we integrate identity and expression information into the multi-view diffusion process to enhance facial consistency across views. Specifically, we apply identity- and expression-aware guidance and supervision to extract accurate facial representations, which guide the model and enforce objective functions to ensure high identity and expression consistency during generation. Finally, we generate an orbital video around the portrait consisting of 96 multi-view frames, which can be used for 3D portrait model reconstruction. Our method demonstrates robust performance across challenging scenarios, including side-face angles and complex accessories
Fuzzy-aware Loss for Source-free Domain Adaptation in Visual Emotion Recognition
Jan 26, 2025Source-free domain adaptation in visual emotion recognition (SFDA-VER) is a highly challenging task that requires adapting VER models to the target domain without relying on source data, which is of great significance for data privacy protection. However, due to the unignorable disparities between visual emotion data and traditional image classification data, existing SFDA methods perform poorly on this task. In this paper, we investigate the SFDA-VER task from a fuzzy perspective and identify two key issues: fuzzy emotion labels and fuzzy pseudo-labels. These issues arise from the inherent uncertainty of emotion annotations and the potential mispredictions in pseudo-labels. To address these issues, we propose a novel fuzzy-aware loss (FAL) to enable the VER model to better learn and adapt to new domains under fuzzy labels. Specifically, FAL modifies the standard cross entropy loss and focuses on adjusting the losses of non-predicted categories, which prevents a large number of uncertain or incorrect predictions from overwhelming the VER model during adaptation. In addition, we provide a theoretical analysis of FAL and prove its robustness in handling the noise in generated pseudo-labels. Extensive experiments on 26 domain adaptation sub-tasks across three benchmark datasets demonstrate the effectiveness of our method.
Enhancing Printed Circuit Board Defect Detection through Ensemble Learning
Sep 14, 2024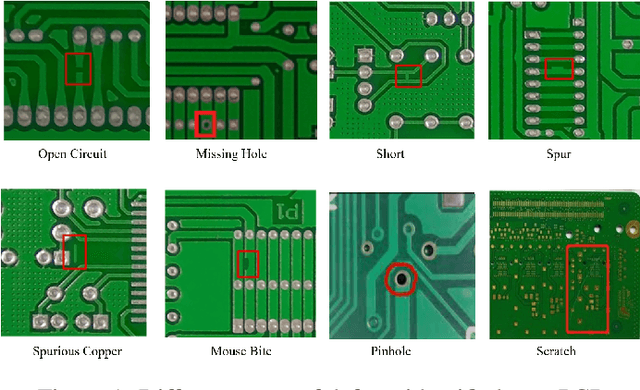
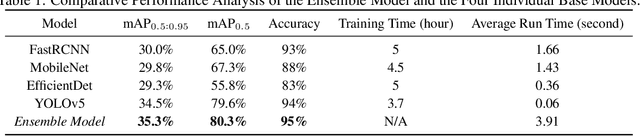


The quality control of printed circuit boards (PCBs) is paramount in advancing electronic device technology. While numerous machine learning methodologies have been utilized to augment defect detection efficiency and accuracy, previous studies have predominantly focused on optimizing individual models for specific defect types, often overlooking the potential synergies between different approaches. This paper introduces a comprehensive inspection framework leveraging an ensemble learning strategy to address this gap. Initially, we utilize four distinct PCB defect detection models utilizing state-of-the-art methods: EfficientDet, MobileNet SSDv2, Faster RCNN, and YOLOv5. Each method is capable of identifying PCB defects independently. Subsequently, we integrate these models into an ensemble learning framework to enhance detection performance. A comparative analysis reveals that our ensemble learning framework significantly outperforms individual methods, achieving a 95% accuracy in detecting diverse PCB defects. These findings underscore the efficacy of our proposed ensemble learning framework in enhancing PCB quality control processes.
A Survey of Embodied Learning for Object-Centric Robotic Manipulation
Aug 21, 2024



Embodied learning for object-centric robotic manipulation is a rapidly developing and challenging area in embodied AI. It is crucial for advancing next-generation intelligent robots and has garnered significant interest recently. Unlike data-driven machine learning methods, embodied learning focuses on robot learning through physical interaction with the environment and perceptual feedback, making it especially suitable for robotic manipulation. In this paper, we provide a comprehensive survey of the latest advancements in this field and categorize the existing work into three main branches: 1) Embodied perceptual learning, which aims to predict object pose and affordance through various data representations; 2) Embodied policy learning, which focuses on generating optimal robotic decisions using methods such as reinforcement learning and imitation learning; 3) Embodied task-oriented learning, designed to optimize the robot's performance based on the characteristics of different tasks in object grasping and manipulation. In addition, we offer an overview and discussion of public datasets, evaluation metrics, representative applications, current challenges, and potential future research directions. A project associated with this survey has been established at https://github.com/RayYoh/OCRM_survey.
User-Friendly Customized Generation with Multi-Modal Prompts
May 26, 2024Text-to-image generation models have seen considerable advancement, catering to the increasing interest in personalized image creation. Current customization techniques often necessitate users to provide multiple images (typically 3-5) for each customized object, along with the classification of these objects and descriptive textual prompts for scenes. This paper questions whether the process can be made more user-friendly and the customization more intricate. We propose a method where users need only provide images along with text for each customization topic, and necessitates only a single image per visual concept. We introduce the concept of a ``multi-modal prompt'', a novel integration of text and images tailored to each customization concept, which simplifies user interaction and facilitates precise customization of both objects and scenes. Our proposed paradigm for customized text-to-image generation surpasses existing finetune-based methods in user-friendliness and the ability to customize complex objects with user-friendly inputs. Our code is available at $\href{https://github.com/zhongzero/Multi-Modal-Prompt}{https://github.com/zhongzero/Multi-Modal-Prompt}$.
Assessing Image Inpainting via Re-Inpainting Self-Consistency Evaluation
May 25, 2024Image inpainting, the task of reconstructing missing segments in corrupted images using available data, faces challenges in ensuring consistency and fidelity, especially under information-scarce conditions. Traditional evaluation methods, heavily dependent on the existence of unmasked reference images, inherently favor certain inpainting outcomes, introducing biases. Addressing this issue, we introduce an innovative evaluation paradigm that utilizes a self-supervised metric based on multiple re-inpainting passes. This approach, diverging from conventional reliance on direct comparisons in pixel or feature space with original images, emphasizes the principle of self-consistency to enable the exploration of various viable inpainting solutions, effectively reducing biases. Our extensive experiments across numerous benchmarks validate the alignment of our evaluation method with human judgment.